
springboot+kafka에서 @KafkaListener를 사용하여 여러 주제를 동적으로 지정하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-20 20:58:194005검색
Description
이 프로젝트는 springboot+kafak 통합 프로젝트이므로 springboot에서 kafak 소비 주석 @KafkaListener를 사용합니다
먼저 application.properties에서 여러 주제를 쉼표로 구분하여 구성합니다.
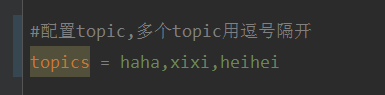
방법: Spring의 SpEl 표현식을 사용하여 주제를 다음과 같이 구성합니다. @KafkaListener(topics = “#{’${topics}’.split(’,’)}”)
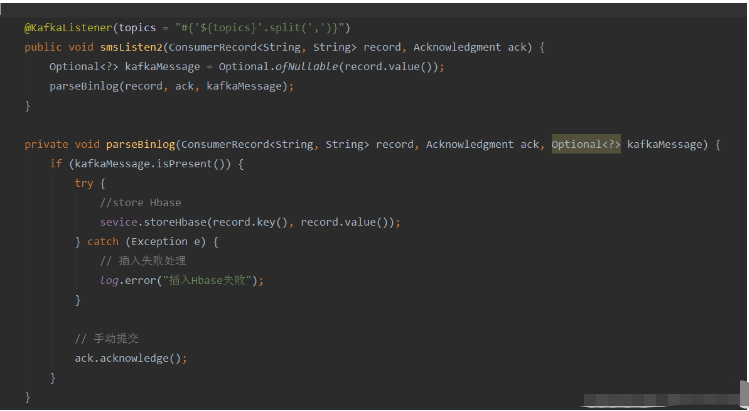
Run 프로그램 및 콘솔 인쇄 효과는 다음과 같습니다.

단 하나의 소비자 스레드만 열렸으므로 모든 주제와 파티션이 이 스레드에 할당됩니다.
이러한 주제를 소비하기 위해 여러 소비자 스레드를 열려면 원하는 소비자 수에 @KafkaListener 주석의 concurrency 매개변수를 추가하세요(소비자 수는 소비자가 원하는) 모든 주제의 파티션 수의 합)

프로그램을 실행하면 콘솔 인쇄 효과는 다음과 같습니다.

자주 묻는 질문을 정리하자면
방법 프로그램이 실행되는 동안 주제를 변경하고 소비할 수 있나요?
ans: 시도한 후에는 @KafkaListener 주석을 사용하여 이 요구 사항을 달성할 수 없습니다. 프로그램이 소비자를 초기화합니다. @KafkaListener 주석 정보를 기반으로 지정된 주제를 사용합니다. 프로그램이 실행되는 동안 주제가 수정되면 소비자는 소비자 구성을 수정한 다음 주제를 다시 구독할 수 없습니다.
하지만 주제 일치를 위해 @KafkaListener의 topicPattern 매개변수를 사용하는 절충안이 있을 수 있습니다.
궁극적인 방법
Idea
Kafka 기본 클라이언트 종속성을 사용하고 @KafkaListener를 사용하는 대신 수동으로 소비자를 초기화하고 소비자 스레드를 시작합니다.
소비자 스레드에서 각 주기는 구성, 데이터베이스 또는 기타 구성 소스에서 최신 주제 정보를 얻고 이를 이전 주제와 비교하며 변경 사항이 발생하면 주제를 다시 구독하거나 소비자를 초기화합니다.
구현
kafka 클라이언트 종속성 추가(이 테스트 서버 kafka 버전: 2.12-2.4.0)
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency>
Code
@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}72번째 코드 줄에 대해 이야기해 보겠습니다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
위 코드 줄의 의미: 100ms Kafka의 브로커가 데이터를 반환할 때까지 기다립니다. 슈퍼마켓 매개변수는 사용 가능한 데이터가 있는지 여부에 관계없이 폴링이 반환될 수 있는 시간을 지정합니다.
주제를 수정한 후에는 이 설문 조사에서 가져온 메시지가 처리될 때까지 기다려야 하며 주제를 다시 구독하기 전에 while(true) 루프 중에 주제의 변경 사항을 감지해야 합니다. 한 번에 poll() 메서드는 500입니다. 아래와 같이 kafka 클라이언트 소스 코드에 설정되어 있습니다.
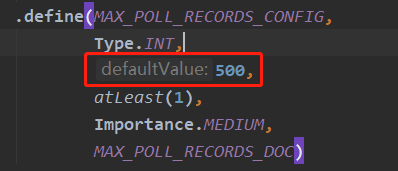 이 구성을 사용자 정의하려면 소비자를 초기화할 때
이 구성을 사용자 정의하려면 소비자를 초기화할 때
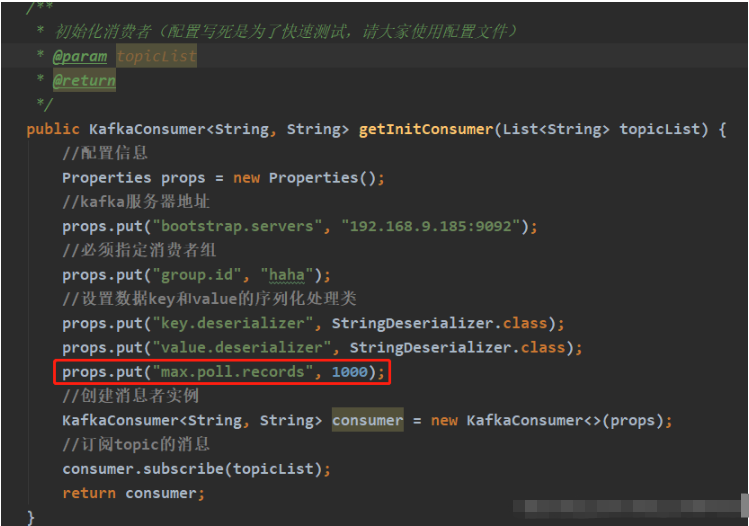 실행 결과를 추가할 수 있습니다(테스트된 주제에는 데이터가 없습니다)
실행 결과를 추가할 수 있습니다(테스트된 주제에는 데이터가 없습니다)
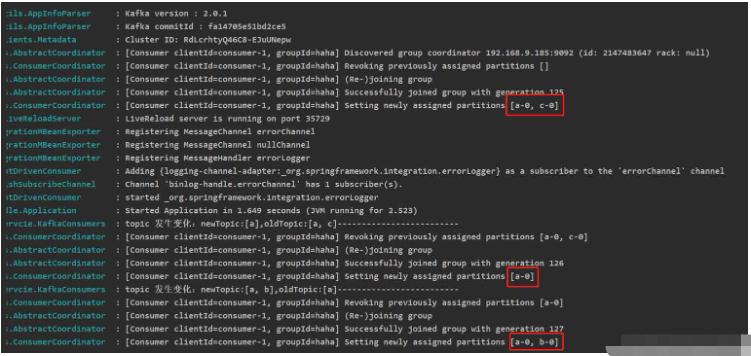 참고: KafkaConsumer는 스레드에 안전하지 않습니다. 여러 소비자를 열려면 하나의 KafkaConsumer 인스턴스를 사용하지 마세요. 여러 소비자를 열려면 여러 개의 새로운 KafkaConsumer 인스턴스를 만들어야 합니다.
참고: KafkaConsumer는 스레드에 안전하지 않습니다. 여러 소비자를 열려면 하나의 KafkaConsumer 인스턴스를 사용하지 마세요. 여러 소비자를 열려면 여러 개의 새로운 KafkaConsumer 인스턴스를 만들어야 합니다.
위 내용은 springboot+kafka에서 @KafkaListener를 사용하여 여러 주제를 동적으로 지정하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!