
딥 러닝을 위한 최고의 GPU 선택

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-20 17:04:061882검색
머신 러닝 프로젝트를 작업할 때, 특히 딥 러닝과 신경망을 다룰 때는 CPU보다는 GPU를 사용하는 것이 좋습니다. 신경망의 경우 아주 기본적인 GPU라도 CPU보다 성능이 뛰어나기 때문입니다.

그러나 어떤 GPU를 구입해야 할까요? 이 기사에서는 예산과 특정 모델링 요구 사항에 따라 현명한 선택을 할 수 있도록 고려해야 할 관련 요소를 요약합니다.
머신러닝에 CPU보다 GPU가 더 좋은 이유는 무엇인가요?
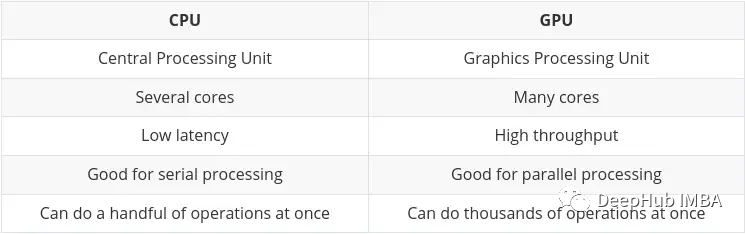
CPU(중앙 처리 장치)는 컴퓨터의 주요 작업으로 매우 유연하며 다양한 프로그램과 하드웨어의 명령을 처리해야 할 뿐만 아니라 특정 처리 속도 요구 사항도 있습니다. 이러한 멀티태스킹 환경에서 우수한 성능을 발휘하기 위해 CPU에는 소수의 유연하고 빠른 처리 장치(코어라고도 함)가 있습니다.
GPU(그래픽 처리 장치) GPU는 멀티태스킹에 있어서 그다지 유연하지 않습니다. 그러나 대량의 복잡한 수학적 계산을 동시에 수행할 수 있습니다. 이는 많은 간단한 계산을 동시에 처리할 수 있는 더 많은 수의 단순 코어(수천에서 수만)를 가짐으로써 달성됩니다.
여러 계산을 병렬로 수행해야 하는 요구 사항은 다음과 같은 경우에 이상적입니다.
- 그래픽 렌더링 - 움직이는 그래픽 개체는 지속적으로 궤적을 계산해야 하며, 이를 위해서는 지속적으로 반복되는 수많은 병렬 수학적 계산이 필요합니다.
- 기계 및 딥 러닝 - 다수의 행렬/텐서 계산을 GPU에서 병렬로 처리할 수 있습니다.
- 모든 종류의 수학적 계산을 분할하여 병렬로 실행할 수 있습니다.
CPU와 GPU의 주요 차이점은 Nvidia 자체 블로그에 요약되어 있습니다.
Tensor 처리 장치(TPU)
인공 지능과 머신/딥 러닝의 발전으로 이제 더 많은 특수 처리 코어가 있습니다. , Tensor 코어라고 합니다. 텐서/행렬 계산을 수행할 때 더 빠르고 효율적입니다. 머신러닝/딥러닝에서 다루는 데이터 유형이 텐서이기 때문입니다.
전용 TPU가 있지만 일부 최신 GPU에는 많은 텐서 코어도 포함되어 있는데 이에 대해서는 나중에 요약하겠습니다.
Nvidia vs AMD
이 질문에 대한 대답은 확실히 Nvidia이므로 이 섹션은 상당히 짧은 섹션이 될 것입니다.
머신/딥 러닝에 AMD의 GPU를 사용할 수 있지만 이 글을 쓰는 시점에서 Nvidia의 GPU는 더 높은 호환성과 일반적으로 TensorFlow 및 PyTorch와 같은 도구와의 더 나은 통합(예를 들어 PyTorch의 AMD GPU 지원은 현재 Linux에서만 사용 가능)
AMD GPU를 사용하려면 추가 도구(ROCm)를 사용해야 하며, 이를 위해서는 약간의 추가 작업이 필요하며 버전이 빠르게 업데이트되지 않을 수 있습니다. 이러한 상황은 향후 개선될 수 있지만 현재로서는 Nvidia를 고수하는 것이 좋습니다.
GPU 선택의 주요 특성
머신 러닝 작업에 적합하고 예산에 맞는 GPU를 선택하는 것은 기본적으로 다음 네 가지 주요 요소의 균형으로 요약됩니다.
- GPU에는 메모리 용량이 얼마나 됩니까? GPU에 CUDA 및/또는 CUDA가 있습니까? 아니면 Tensor Core가 있습니까?
- 카드는 어떤 칩 아키텍처를 사용합니까?
- 전력 요구 사항은 무엇입니까(있는 경우)?
- 이러한 측면은 귀하에게 중요한 것이 무엇인지 더 잘 이해할 수 있도록 아래에서 하나씩 논의될 것입니다.
GPU 메모리
답은 많을수록 좋다는 것입니다!
그것은 실제로 작업과 해당 모델의 크기에 따라 다릅니다. 예를 들어 이미지, 비디오 또는 오디오를 처리하는 경우 정의상 상당히 많은 양의 데이터를 처리하게 되며 GPU RAM은 매우 중요한 고려 사항이 됩니다.
메모리 부족 문제를 해결하는 방법은 항상 있습니다(예: 배치 크기 줄이기). 그러나 이는 훈련 시간을 낭비하게 되므로 요구 사항의 균형을 잘 맞춰야 합니다.
경험에 근거하여 제가 추천하는 사항은 다음과 같습니다.
4GB: 제 생각에는 이것이 절대적인 최소값이라고 생각하며 지나치게 복잡한 모델이나 큰 이미지, 비디오 또는 오디오를 다루지 않는 한 대부분의 경우 효과가 있지만 매일 사용하기에는 충분하지 않습니다. 막 시작했는데 올인하지 않고 해보고 싶다면 시작해 보세요- 8GB: 일상 학습을 위한 훌륭한 시작이며 RAM 제한을 초과하지 않고 대부분의 작업을 완료할 수 있지만 더 많이 사용하는 것이 좋습니다. 복잡한 이미지, 비디오 또는 오디오 모델에서 문제가 발생할 수 있습니다.
- 12GB: 이것이 과학 연구에 있어서 가장 기본적인 요구 사항이라고 생각합니다. 이미지, 비디오 또는 오디오 작업을 포함하여 가장 큰 모델을 처리할 수 있습니다.
- 12GB+: 많을수록 더 큰 데이터 세트와 더 큰 배치 크기를 처리할 수 있습니다. 12GB 이상에서는 가격이 실제로 상승하기 시작합니다.
- 일반적으로 비용이 동일하다면 메모리가 더 많고 "느린" 카드를 선택하는 것이 좋습니다. GPU의 장점은 GPU를 통해 데이터를 전송하기 위해 사용 가능한 RAM에 크게 의존하는 높은 처리량입니다.
CUDA 코어 및 Tensor 코어
이것은 실제로 매우 간단하며 많을수록 좋습니다.
RAM을 먼저 고려한 다음 CUDA를 고려하세요. 머신/딥 러닝의 경우 Tensor 코어가 CUDA 코어보다 더 좋습니다(더 빠르고 효율적). 머신/딥러닝 분야에서 요구되는 연산을 위해 정밀하게 설계되었기 때문입니다.
그러나 CUDA 커널은 이미 충분히 빠르기 때문에 문제가 되지 않습니다. Tensor 코어가 포함된 카드를 얻을 수 있다면 이는 좋은 장점이므로 너무 집착하지 마세요.
나중에 "CUDA"가 여러 번 언급되는 것을 볼 수 있습니다. 먼저 요약해 보겠습니다.
CUDA 코어 - 이는 그래픽 카드의 물리적 프로세서로, 일반적으로 수천 개가 있고 4090에는 16,000개가 있습니다.
CUDA 11 - 숫자는 변경될 수 있지만 이는 그래픽 카드가 제대로 작동할 수 있도록 설치된 소프트웨어/드라이버를 나타냅니다. NV는 정기적으로 새 버전을 출시하며 다른 소프트웨어와 마찬가지로 설치 및 업데이트가 가능합니다.
CUDA 세대(또는 컴퓨팅 성능) - 최신 버전의 그래픽 카드 코드명을 설명합니다. 이는 하드웨어에 고정되어 있으므로 새 카드로 업그레이드해야만 변경할 수 있습니다. 숫자와 코드명으로 구별됩니다. 예: 3. x[케플러],5. x[맥스웰], 6. x [파스칼], 7. x[튜링] 및 8. x(암페어).
Chip Architecture
이것은 실제로 생각보다 더 중요합니다. 여기서는 AMD에 대해 논의하는 것이 아닙니다. 제 눈에는 "Old Huang"만 보입니다.
위에서 이미 30 시리즈 카드가 Ampere 아키텍처이고 최신 40 시리즈 카드가 Ada Lovelace라고 언급했습니다. 일반적으로 Huang은 유명한 과학자이자 수학자 이름을 따서 아키텍처 이름을 지정하지만 이번에는 루프와 서브루틴의 개념을 확립한 여성 수학자이자 컴퓨터 프로그램 창시자인 유명한 영국 시인 바이런의 딸인 Ada Lovelace를 선택했습니다.
카드의 컴퓨팅 성능을 이해하려면 다음 두 가지 측면을 이해해야 합니다.
- 획기적인 기능 개선
- 여기서 중요한 기능은 혼합 정밀도 교육입니다.
32비트 부동 소수점보다 정밀도가 낮은 숫자를 사용합니다. 숫자 형식에는 많은 이점이 있습니다. 첫째, 메모리가 덜 필요하므로 더 큰 신경망을 훈련하고 배포할 수 있습니다. 둘째, 메모리 대역폭이 덜 필요하므로 데이터 전송 작업 속도가 빨라집니다. 세 번째 수학 연산은 특히 Tensor 코어가 있는 GPU에서 감소된 정밀도로 더 빠르게 실행됩니다. 혼합 정밀 훈련은 전체 정밀 훈련에 비해 작업별 정확도를 잃지 않으면서 이러한 모든 이점을 달성합니다. 이는 전체 정밀도가 필요한 단계를 식별하고 해당 단계에만 32비트 부동 소수점을 사용하고 다른 모든 단계에서는 16비트 부동 소수점을 사용하여 이를 수행합니다.
다음은 공식 Nvidia 문서입니다. 관심이 있으시면 살펴보실 수 있습니다.
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
GPU가 있는 경우 7.x(Turing) 이상의 아키텍처를 가지고 있어 하이브리드 정밀훈련이 가능합니다. 이는 데스크톱의 RTX 20 시리즈 이상, 서버의 "T" 또는 "A" 시리즈를 의미합니다.
혼합 정밀 훈련이 이러한 장점을 갖는 주된 이유는 Tensor Core의 GPU가 혼합 정밀 훈련을 가속화한다는 것입니다. 그렇지 않은 경우 FP16을 사용하면 비디오 메모리가 절약되고 더 큰 배치 크기를 훈련할 수 있어 간접적으로 훈련 속도가 향상됩니다. .
더 이상 사용되지 않을 예정인가요?
RAM 요구 사항이 특히 높지만 고급 카드를 구입할 돈이 충분하지 않은 경우 중고 시장에서 구형 GPU를 선택할 수 있습니다. 여기에는 꽤 큰 단점이 있습니다. 카드의 수명이 끝났습니다.
전형적인 예는 4992개의 CUDA 코어와 24GB RAM을 갖춘 Tesla K80입니다. 2014년에는 약 7,000달러에 판매되었습니다. 현재 가격은 150달러에서 170달러 사이입니다. (젓갈 가격은 600~700달러 정도입니다.) 이렇게 저렴한 가격에 이렇게 큰 추억을 갖게 되니 정말 신나시겠어요.
하지만 아주 큰 문제가 있습니다. K80의 컴퓨팅 아키텍처는 3.7(Kepler)이며, CUDA 11(현재 CUDA 버전은 11.7)부터 더 이상 지원되지 않습니다. 이는 카드의 유효기간이 만료되었다는 의미이므로 이렇게 저렴하게 판매되는 것입니다.
그러므로 중고 카드를 선택할 때 최신 버전의 드라이버와 CUDA를 지원하는지 확인하는 것이 가장 중요합니다.
고급 게이밍 카드 VS 워크스테이션/서버 카드
Lao Huang은 기본적으로 카드를 두 부분으로 나눴습니다. 소비자용 그래픽 카드 및 워크스테이션/서버 그래픽 카드(예: 전문가용 그래픽 카드)
두 부분 사이에는 분명한 차이가 있습니다. 동일한 사양(RAM, CUDA 코어, 아키텍처) 소비자 그래픽 카드가 일반적으로 더 저렴하기 때문입니다. 그러나 전문 카드는 일반적으로 품질이 더 좋고 에너지 소비가 더 낮습니다. 실제로 터빈의 소음은 꽤 커서 컴퓨터실에 놓으면 괜찮지만 집이나 실험실에 놓으면 약간 시끄럽습니다.
고급(매우 비싼) 전문 카드에는 RAM이 많다는 것을 알 수 있습니다(예: RTX A6000은 48GB, A100은 80GB!). 이는 일반적으로 높은 수준의 RAM이 필요한 3D 모델링, 렌더링, 머신/딥 러닝 전문 시장을 대상으로 하기 때문입니다. 역시 돈이 있으면 그냥 A100 사세요! (H100은 A100의 새 버전이라 현재 평가는 불가능합니다.)
하지만 개인적으로는 소비자용 고급 게임카드를 선택해야 한다고 생각합니다. 돈, 당신도 이 글을 읽지 않겠죠?
제안을 선택하세요
그래서 마지막에 예산과 필요에 따라 몇 가지 제안을 할게요.
- 저예산
- 중예산
- 고예산
고예산은 고급형 소비자용 그래픽 카드 외에는 아무것도 고려하지 않습니다. 다시 말하지만, 돈이 있다면 A100이나 H100을 구입하세요.
이 기사에는 중고 시장에서 구입한 카드가 포함되어 있습니다. 이는 주로 예산이 낮은 경우 중고품을 고려해야 한다고 생각하기 때문입니다. Professional Desktop 시리즈 카드(T600, A2000 및 A4000)도 여기에 포함됩니다. 일부 구성은 유사한 소비자 그래픽 카드보다 약간 나쁘지만 전력 소비는 훨씬 더 좋기 때문입니다.
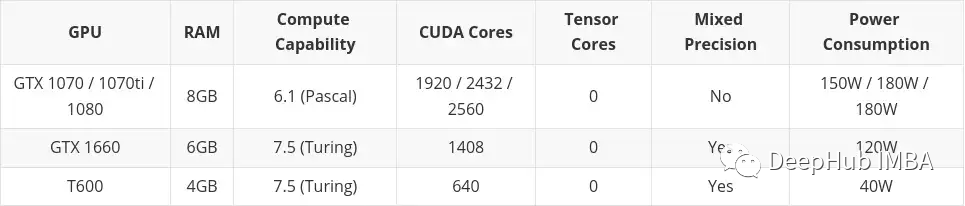
저예산
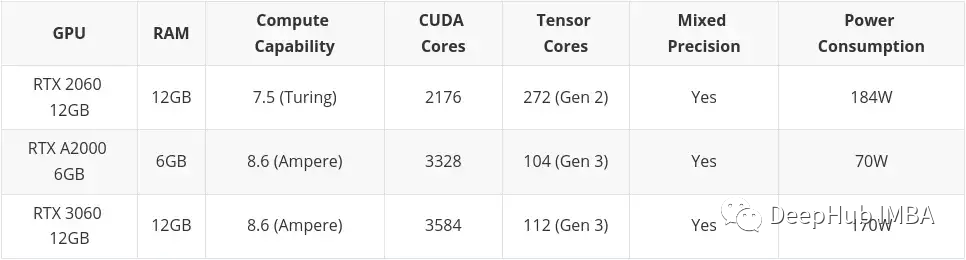
중간예산
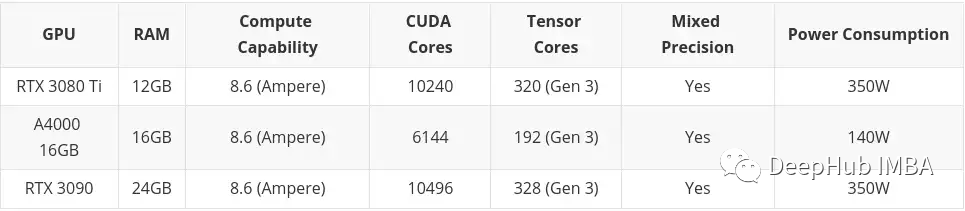
고예산
온라인/클라우드 서비스
그래픽 카드에 돈을 쓰는 것이 적합하지 않다고 판단되면 다음을 활용할 수 있습니다. GPU를 무료로 사용할 수 있는 Google Colab.
하지만 시간 제한이 있습니다. GPU를 너무 오랫동안 사용하면 쫓겨나고 CPU로 돌아가게 됩니다. 또한 코드를 작성하는 동안 GPU가 너무 오랫동안 비활성 상태인 경우 GPU를 다시 가져옵니다. GPU도 자동으로 할당되기 때문에 정확히 원하는 GPU를 선택할 수는 없습니다. (또한 Colab Pro를 월 9.99달러에 구입할 수 있는데 개인적으로 저예산보다 훨씬 낫다고 생각하지만 사다리가 필요하고, $49.99 Colab Pro+는 약간 비싸므로 권장하지 않습니다.
글을 쓰는 시점에 Colab을 통해 다음 GPU를 사용할 수 있습니다.
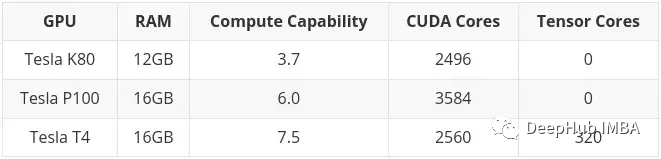
앞서 언급했듯이 K80에는 24GB RAM과 4992 CUDA 코어가 있으며 이는 기본적으로 두 개의 K40 카드가 서로 연결되어 있습니다. 즉, Colab에서 K80을 사용하면 실제로 카드의 절반에 액세스할 수 있으므로 12GB 및 2496 CUDA 코어에 불과합니다.
요약
결국 4090은 여전히 원숭이 상태네요 기본적으로 더 높은 가격에 사거나 스캘퍼를 구해야 합니다
하지만 3090의 10496 CUDA에 비하면 16384 CUDA + 24GB입니다. , 정말 좋아요.
그리고 4080 16G 9728CUDA의 가격이 7000이내라면 매우 가성비 좋은 선택이겠죠. 12G 4080을 고려하지 마십시오. 이름에 걸맞지 않습니다.
AMD의 7900XTX도 좋은 선택이겠지만, 호환성이 큰 문제라면 누구든지 테스트해 보면 한 마디 남길 수 있습니다.
Lao Huang이 40 시리즈에서 장난을 쳤으니 서두르지 않으면 조금만 더 기다려주세요.
당신도 안 사요 나도 안 사요 그러면 줄어들 거예요 내일 200까지
위 내용은 딥 러닝을 위한 최고의 GPU 선택의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!