
Java 문자열 인코딩 및 디코딩 성능을 향상시키는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-20 11:28:571277검색
1. 일반적인 문자열 인코딩
일반적인 문자열 인코딩은 다음과 같습니다.
LATIN1은 ISO-8859-1이라고도 하는 ASCII 문자만 저장할 수 있습니다.
UTF-8은 1, 2 또는 3바이트를 사용하여 문자를 나타내는 가변 길이 바이트 인코딩입니다. 중국어는 일반적으로 표현하는 데 3바이트가 필요하므로 중국어 장면 UTF-8 인코딩에는 일반적으로 더 많은 공간이 필요하며 대안은 GBK/GB2312/GB18030입니다.
UTF-16 2바이트, 한 문자는 2바이트로 표현되어야 하며 UCS-2(2바이트 범용 문자 집합)라고도 합니다. 큰 끝과 작은 끝의 구분에 따라 UTF-16에는 UTF-16BE와 UTF-16LE의 두 가지 형식이 있습니다. 기본 UTF-16은 UTF-16BE를 나타냅니다. Java 언어의 char은 UTF-16LE 인코딩입니다.
GB18030은 가변 길이 바이트 인코딩을 채택하고 각 문자는 1, 2 또는 3바이트로 표시됩니다. UTF8과 유사하게 2개의 문자를 사용하여 중국어를 표현하면 바이트를 절약할 수 있지만, 이 방법은 국제적으로 보편적이지 않습니다.
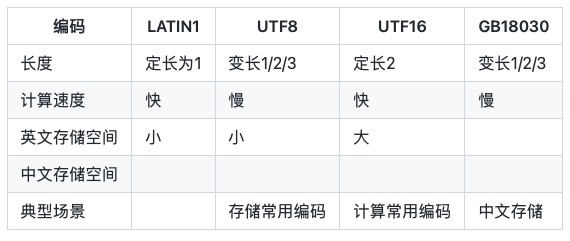
계산의 편의를 위해 메모리의 문자열은 일반적으로 Java 언어의 char과 .NET의 char 모두 UTF-16을 사용합니다. 초기 Windows-NT는 UTF-16만 지원했습니다.
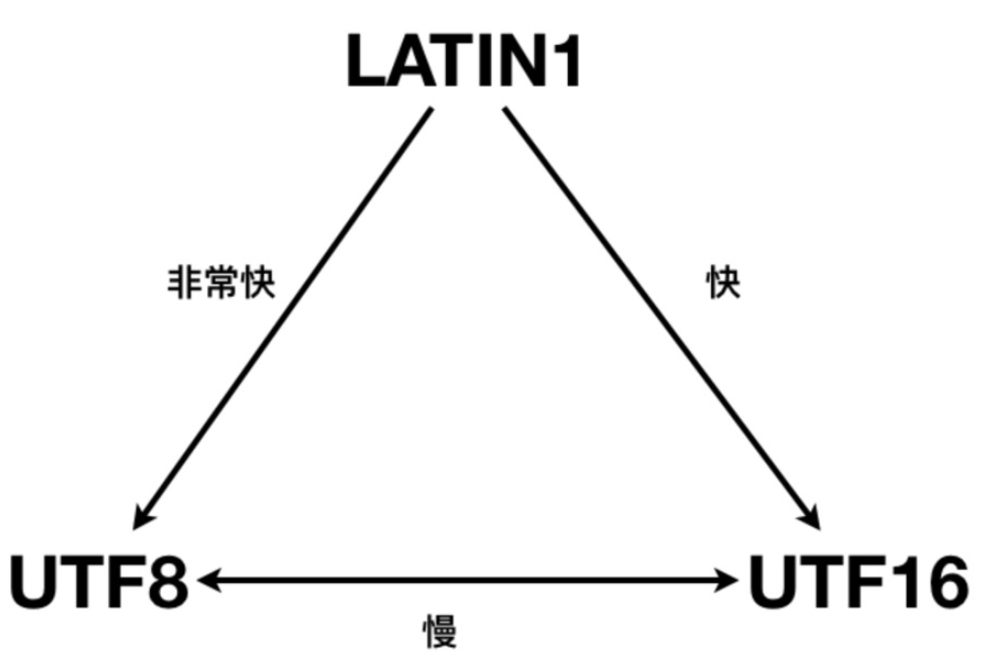
2. 인코딩 변환 성능
UTF-16과 UTF-8 간의 변환은 더 복잡하며 일반적으로 성능이 좋지 않습니다.
다음은 UTF-16을 UTF-8 인코딩으로 변환하는 구현입니다. 알고리즘이 상대적으로 복잡하므로 이 작업을 벡터 API를 사용하여 최적화할 수 없다는 것을 알 수 있습니다.
static int encodeUTF8(char[] utf16, int off, int len, byte[] dest, int dp) {
int sl = off + len, last_offset = sl - 1;
while (off < sl) {
char c = utf16[off++];
if (c < 0x80) {
// Have at most seven bits
dest[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 dest, 11 bits
dest[dp++] = (byte) (0xc0 | (c >> 6));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < '\uE000') {
int uc;
if (c < '\uDC00') {
if (off > last_offset) {
dest[dp++] = (byte) '?';
return dp;
}
char d = utf16[off];
if (d >= '\uDC00' && d < '\uE000') {
uc = (c << 10) + d + 0xfca02400;
} else {
throw new RuntimeException("encodeUTF8 error", new MalformedInputException(1));
}
} else {
uc = c;
}
dest[dp++] = (byte) (0xf0 | ((uc >> 18)));
dest[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dest[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (uc & 0x3f));
off++; // 2 utf16
} else {
// 3 dest, 16 bits
dest[dp++] = (byte) (0xe0 | ((c >> 12)));
dest[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}Java의 char은 UTF-16LE로 인코딩되므로 char[]를 UTF-16LE로 인코딩된 byte[]로 변환해야 하는 경우 sun.misc.Unsafe#copyMemory 메서드를 사용하면 빠르게 복사할 수 있습니다. 예를 들면 다음과 같습니다.
static int writeUtf16LE(char[] chars, int off, int len, byte[] dest, final int dp) {
UNSAFE.copyMemory(chars
, CHAR_ARRAY_BASE_OFFSET + off * 2
, dest
, BYTE_ARRAY_BASE_OFFSET + dp
, len * 2
);
dp += len * 2;
return dp;
}3. Java 문자열 인코딩
JDK의 버전에 따라 문자열 처리 방법이 다르기 때문에 성능도 달라집니다. JDK 9 이후에는 String이 내부적으로 LATIN1 인코딩을 사용할 수도 있지만 char은 여전히 UTF-16 인코딩을 사용합니다.
3.1. JDK 6 이전의 문자열 구현
static class String {
final char[] value;
final int offset;
final int count;
}Java 6 이전에는 String.subString 메소드에 의해 생성된 String 객체와 원본 String 객체가 char[] 값을 공유하므로, 참조할 subString 메소드이며 GC에서 재활용할 수 없습니다. 많은 라이브러리는 JDK 6 이하의 문제를 방지하기 위해 subString 메서드 사용을 피합니다.
3.2. JDK 7/8의 문자열 구현
static class String {
final char[] value;
}JDK 7 이후에는 오프셋 및 개수 필드가 문자열에서 제거되고 value.length는 원래 개수입니다. 이렇게 하면 큰 char[]를 참조하는 subString 문제가 방지되고 최적화가 쉬워집니다. 결과적으로 JDK7/8의 문자열 작업 성능은 Java 6에 비해 크게 향상됩니다.
3.3 JDK 9/10/11
static class String {
final byte code;
final byte[] value;
static final byte LATIN1 = 0;
static final byte UTF16 = 1;
}구현 JDK 9 이후에는 값 유형이 char[]에서 byte[]로 변경되고, 필드 코드가 추가됩니다. 문자가 모두 ASCII 문자인 경우 값을 사용합니다. LATIN 인코딩을 사용합니다. ASCII가 아닌 문자가 있으면 UTF16으로 인코딩됩니다. 이러한 혼합 인코딩 방식을 사용하면 영어 장면이 메모리를 덜 차지하게 됩니다. 단점은 Java 9의 String API 성능이 JDK 8만큼 좋지 않을 수 있다는 것입니다. 특히 char[]를 전달하여 문자열을 구성하면 라틴어로 인코딩된 byte[]로 압축됩니다. 일부 시나리오에서는 10% 감소할 수 있습니다.
4. 문자열을 빠르게 구성하는 방법
문자열의 불변성을 실현하려면 문자열을 구성할 때 복사 과정이 있습니다. 문자열 구성 비용을 늘리려면 이러한 복사를 피해야 합니다. .
예를 들어 다음은 JDK8에서 String의 생성자를 구현한 것입니다.
public final class String {
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
}JDK8에는 복사하지 않는 생성자가 있지만 이 메서드는 공개되지 않습니다. MethodHandles.Lookup을 구현하려면 트릭을 사용해야 합니다. & LambdaMetafactory 바인딩 반영 호출을 위해 기사 뒷부분에 이 기술을 소개하는 코드가 있습니다.
public final class String {
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
}문자를 빠르게 구성하는 세 가지 방법이 있습니다.
MethodHandles.Lookup 및 LambdaMetafactory를 사용하여 리플렉션 바인딩
JavaLangAccess의 관련 메서드 사용
Unsafe를 사용하여
1 및 2 성능은 비슷하고 3은 약간 느리지만 둘 다 새 문자열을 직접 사용하는 것보다 빠릅니다. JMH 테스트를 사용한 JDK8의 데이터는 다음과 같습니다.
JDK 9 이후에는 모두 ASCII 문자인 장면에 대해 직접 구성이 더 나은 결과를 얻을 수 있습니다.Benchmark ‐ ' s ' s ' t- t , 1936.7 54 ops/ms
StringCreateBenchmark.langAccess thrpt 5 784029.186 ± 2734.300 ops/ms
StringCreateBenchmark.unsafe thrpt 5 761176.319 ± 11914.549 ops/ms
StringCreateBenchmark.newString thrpt 5 140883.533 ± 2217.773 ops/ms
4.1 基于MethodHandles.Lookup & LambdaMetafactory绑定反射的快速构造字符串的方法
4.1.1 JDK8快速构造字符串
public static BiFunction<char[], Boolean, String> getStringCreatorJDK8() throws Throwable {
Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class);
constructor.setAccessible(true);
MethodHandles lookup = constructor.newInstance(
String.class
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findConstructor(
String.class, MethodType.methodType(void.class, char[].class, boolean.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "apply"
, MethodType.methodType(BiFunction.class)
, handle.type().generic()
, handle
, handle.type()
);
return (BiFunction) callSite.getTarget().invokeExact();
}4.1.2 JDK 11快速构造字符串的方法
public static ToIntFunction<String> getStringCode11() throws Throwable {
Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class);
constructor.setAccessible(true);
MethodHandles.Lookup lookup = constructor.newInstance(
String.class
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findVirtual(
String.class, "coder", MethodType.methodType(byte.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "applyAsInt"
, MethodType.methodType(ToIntFunction.class)
, MethodType.methodType(int.class, Object.class)
, handle
, handle.type()
);
return (ToIntFunction<String>) callSite.getTarget().invokeExact();
}if (JDKUtils.JVM_VERSION == 11) {
Function<byte[], String> stringCreator = JDKUtils.getStringCreatorJDK11();
byte[] bytes = new byte[]{'a', 'b', 'c'};
String apply = stringCreator.apply(bytes);
assertEquals("abc", apply);
}4.1.3 JDK 17快速构造字符串的方法
在JDK 17中,MethodHandles.Lookup使用Reflection.registerFieldsToFilter对lookupClass和allowedModes做了保护,网上搜索到的通过修改allowedModes的办法是不可用的。
在JDK 17中,要通过配置JVM启动参数才能使用MethodHandlers。如下:
--add-opens java.base/java.lang.invoke=ALL-UNNAMED
public static BiFunction<byte[], Charset, String> getStringCreatorJDK17() throws Throwable {
Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, Class.class, int.class);
constructor.setAccessible(true);
MethodHandles.Lookup lookup = constructor.newInstance(
String.class
, null
, -1 // Lookup.TRUSTED
);
MethodHandles.Lookup caller = lookup.in(String.class);
MethodHandle handle = caller.findStatic(
String.class, "newStringNoRepl1", MethodType.methodType(String.class, byte[].class, Charset.class)
);
CallSite callSite = LambdaMetafactory.metafactory(
caller
, "apply"
, MethodType.methodType(BiFunction.class)
, handle.type().generic()
, handle
, handle.type()
);
return (BiFunction<byte[], Charset, String>) callSite.getTarget().invokeExact();
}if (JDKUtils.JVM_VERSION == 17) {
BiFunction<byte[], Charset, String> stringCreator = JDKUtils.getStringCreatorJDK17();
byte[] bytes = new byte[]{'a', 'b', 'c'};
String apply = stringCreator.apply(bytes, StandardCharsets.US_ASCII);
assertEquals("abc", apply);
}4.2 基于JavaLangAccess快速构造
通过SharedSecrets提供的JavaLangAccess,也可以不拷贝构造字符串,但是这个比较麻烦,JDK 8/11/17的API都不一样,对一套代码兼容不同的JDK版本不方便,不建议使用。
JavaLangAccess javaLangAccess = SharedSecrets.getJavaLangAccess(); javaLangAccess.newStringNoRepl(b, StandardCharsets.US_ASCII);
4.3 基于Unsafe实现快速构造字符串
public static final Unsafe UNSAFE;
static {
Unsafe unsafe = null;
try {
Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeField.setAccessible(true);
unsafe = (Unsafe) theUnsafeField.get(null);
} catch (Throwable ignored) {}
UNSAFE = unsafe;
}
////////////////////////////////////////////
Object str = UNSAFE.allocateInstance(String.class);
UNSAFE.putObject(str, valueOffset, chars);注意:在JDK 9之后,实现是不同,比如:
Object str = UNSAFE.allocateInstance(String.class); UNSAFE.putByte(str, coderOffset, (byte) 0); UNSAFE.putObject(str, valueOffset, (byte[]) bytes);
4.4 快速构建字符串的技巧应用:
如下的方法格式化日期为字符串,性能就会非常好。
public String formatYYYYMMDD(Calendar calendar) throws Throwable {
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH) + 1;
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH);
byte y0 = (byte) (year / 1000 + '0');
byte y1 = (byte) ((year / 100) % 10 + '0');
byte y2 = (byte) ((year / 10) % 10 + '0');
byte y3 = (byte) (year % 10 + '0');
byte m0 = (byte) (month / 10 + '0');
byte m1 = (byte) (month % 10 + '0');
byte d0 = (byte) (dayOfMonth / 10 + '0');
byte d1 = (byte) (dayOfMonth % 10 + '0');
if (JDKUtils.JVM_VERSION >= 9) {
byte[] bytes = new byte[] {y0, y1, y2, y3, m0, m1, d0, d1};
if (JDKUtils.JVM_VERSION == 17) {
return JDKUtils.getStringCreatorJDK17().apply(bytes, StandardCharsets.US_ASCII);
}
if (JDKUtils.JVM_VERSION <= 11) {
return JDKUtils.getStringCreatorJDK11().apply(bytes);
}
return new String(bytes, StandardCharsets.US_ASCII);
}
char[] chars = new char[]{
(char) y0,
(char) y1,
(char) y2,
(char) y3,
(char) m0,
(char) m1,
(char) d0,
(char) d1
};
if (JDKUtils.JVM_VERSION == 8) {
return JDKUtils.getStringCreatorJDK8().apply(chars, true);
}
return new String(chars);
}5.快速遍历字符串的办法
无论JDK什么版本,String.charAt都是一个较大的开销,JIT的优化效果并不好,无法消除参数index范围检测的开销,不如直接操作String里面的value数组。
public final class String {
private final char value[];
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
}在JDK 9之后的版本,charAt开销更大
public final class String {
private final byte[] value;
private final byte coder;
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}
}5.1 获取String.value的方法
获取String.value的方法有如下:
使用Field反射
使用Unsafe
Unsafe和Field反射在JDK 8 JMH的比较数据如下:
Benchmark Mode Cnt Score Error Units
StringGetValueBenchmark.reflect thrpt 5 438374.685 ± 1032.028 ops/ms
StringGetValueBenchmark.unsafe thrpt 5 1302654.150 ± 59169.706 ops/ms
5.1.1 使用反射获取String.value
static Field valueField;
static {
try {
valueField = String.class.getDeclaredField("value");
valueField.setAccessible(true);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
char[] chars = (char[]) valueField.get(str);5.1.2 使用Unsafe获取String.value
static long valueFieldOffset;
static {
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UNSAFE.objectFieldOffset(valueField);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
char[] chars = (char[]) UNSAFE.getObject(str, valueFieldOffset);static long valueFieldOffset;
static long coderFieldOffset;
static {
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UNSAFE.objectFieldOffset(valueField);
Field coderField = String.class.getDeclaredField("coder");
coderFieldOffset = UNSAFE.objectFieldOffset(coderField);
} catch (NoSuchFieldException ignored) {}
}
////////////////////////////////////////////
byte coder = UNSAFE.getObject(str, coderFieldOffset);
byte[] bytes = (byte[]) UNSAFE.getObject(str, valueFieldOffset);6.更快的encodeUTF8方法
当能直接获取到String.value时,就可以直接对其做encodeUTF8操作,会比String.getBytes(StandardCharsets.UTF_8)性能好很多。
6.1 JDK8高性能encodeUTF8的方法
public static int encodeUTF8(char[] src, int offset, int len, byte[] dst, int dp) {
int sl = offset + len;
int dlASCII = dp + Math.min(len, dst.length);
// ASCII only optimized loop
while (dp < dlASCII && src[offset] < '\u0080') {
dst[dp++] = (byte) src[offset++];
}
while (offset < sl) {
char c = src[offset++];
if (c < 0x80) {
// Have at most seven bits
dst[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 bytes, 11 bits
dst[dp++] = (byte) (0xc0 | (c >> 6));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < ('\uDFFF' + 1)) { //Character.isSurrogate(c) but 1.7
final int uc;
int ip = offset - 1;
if (c >= '\uD800' && c < ('\uDBFF' + 1)) { // Character.isHighSurrogate(c)
if (sl - ip < 2) {
uc = -1;
} else {
char d = src[ip + 1];
// d >= '\uDC00' && d < ('\uDFFF' + 1)
if (d >= '\uDC00' && d < ('\uDFFF' + 1)) { // Character.isLowSurrogate(d)
uc = ((c << 10) + d) + (0x010000 - ('\uD800' << 10) - '\uDC00'); // Character.toCodePoint(c, d)
} else {
dst[dp++] = (byte) '?';
continue;
}
}
} else {
//
if (c >= '\uDC00' && c < ('\uDFFF' + 1)) { // Character.isLowSurrogate(c)
dst[dp++] = (byte) '?';
continue;
} else {
uc = c;
}
}
if (uc < 0) {
dst[dp++] = (byte) '?';
} else {
dst[dp++] = (byte) (0xf0 | ((uc >> 18)));
dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (uc & 0x3f));
offset++; // 2 chars
}
} else {
// 3 bytes, 16 bits
dst[dp++] = (byte) (0xe0 | ((c >> 12)));
dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}使用encodeUTF8方法举例
char[] chars = UNSAFE.getObject(str, valueFieldOffset); // ensureCapacity(chars.length * 3) byte[] bytes = ...; // int bytesLength = IOUtils.encodeUTF8(chars, 0, chars.length, bytes, bytesOffset);
这样encodeUTF8操作,不会有多余的arrayCopy操作,性能会得到提升。
6.1.1 性能测试比较
测试代码
public class EncodeUTF8Benchmark {
static String STR = "01234567890ABCDEFGHIJKLMNOPQRSTUVWZYZabcdefghijklmnopqrstuvwzyz一二三四五六七八九十";
static byte[] out;
static long valueFieldOffset;
static {
out = new byte[STR.length() * 3];
try {
Field valueField = String.class.getDeclaredField("value");
valueFieldOffset = UnsafeUtils.UNSAFE.objectFieldOffset(valueField);
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
@Benchmark
public void unsafeEncodeUTF8() throws Exception {
char[] chars = (char[]) UnsafeUtils.UNSAFE.getObject(STR, valueFieldOffset);
int len = IOUtils.encodeUTF8(chars, 0, chars.length, out, 0);
}
@Benchmark
public void getBytesUTF8() throws Exception {
byte[] bytes = STR.getBytes(StandardCharsets.UTF_8);
System.arraycopy(bytes, 0, out, 0, bytes.length);
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(EncodeUTF8Benchmark.class.getName())
.mode(Mode.Throughput)
.timeUnit(TimeUnit.MILLISECONDS)
.forks(1)
.build();
new Runner(options).run();
}
}测试结果
EncodeUTF8Benchmark.getBytesUTF8 thrpt 5 20690.960 ± 5431.442 ops/ms
EncodeUTF8Benchmark.unsafeEncodeUTF8 thrpt 5 34508.606 ± 55.510 ops/ms
从结果来看,通过unsafe + 直接调用encodeUTF8方法, 编码的所需要开销是newStringUTF8的58%。
6.2 JDK9/11/17高性能encodeUTF8的方法
public static int encodeUTF8(byte[] src, int offset, int len, byte[] dst, int dp) {
int sl = offset + len;
while (offset < sl) {
byte b0 = src[offset++];
byte b1 = src[offset++];
if (b1 == 0 && b0 >= 0) {
dst[dp++] = b0;
} else {
char c = (char)(((b0 & 0xff) << 0) | ((b1 & 0xff) << 8));
if (c < 0x800) {
// 2 bytes, 11 bits
dst[dp++] = (byte) (0xc0 | (c >> 6));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < ('\uDFFF' + 1)) { //Character.isSurrogate(c) but 1.7
final int uc;
int ip = offset - 1;
if (c >= '\uD800' && c < ('\uDBFF' + 1)) { // Character.isHighSurrogate(c)
if (sl - ip < 2) {
uc = -1;
} else {
b0 = src[ip + 1];
b1 = src[ip + 2];
char d = (char) (((b0 & 0xff) << 0) | ((b1 & 0xff) << 8));
// d >= '\uDC00' && d < ('\uDFFF' + 1)
if (d >= '\uDC00' && d < ('\uDFFF' + 1)) { // Character.isLowSurrogate(d)
uc = ((c << 10) + d) + (0x010000 - ('\uD800' << 10) - '\uDC00'); // Character.toCodePoint(c, d)
} else {
return -1;
}
}
} else {
//
if (c >= '\uDC00' && c < ('\uDFFF' + 1)) { // Character.isLowSurrogate(c)
return -1;
} else {
uc = c;
}
}
if (uc < 0) {
dst[dp++] = (byte) '?';
} else {
dst[dp++] = (byte) (0xf0 | ((uc >> 18)));
dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (uc & 0x3f));
offset++; // 2 chars
}
} else {
// 3 bytes, 16 bits
dst[dp++] = (byte) (0xe0 | ((c >> 12)));
dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
}
return dp;
}使用encodeUTF8方法举例
byte coder = UNSAFE.getObject(str, coderFieldOffset);
byte[] value = UNSAFE.getObject(str, coderFieldOffset);
if (coder == 0) {
// ascii arraycopy
} else {
// ensureCapacity(chars.length * 3)
byte[] bytes = ...; //
int bytesLength = IOUtils.encodeUTF8(value, 0, value.length, bytes, bytesOffset);
}这样encodeUTF8操作,不会有多余的arrayCopy操作,性能会得到提升。
위 내용은 Java 문자열 인코딩 및 디코딩 성능을 향상시키는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!