
알파카 시리즈 대형 모델과 ChatGPT의 차이점은 무엇인가요? 상세한 평가를 마친 후 나는 침묵했다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-19 19:17:121733검색
얼마 전 구글에서 유출된 문서가 큰 관심을 끌었습니다. 이 문서에서 Google 내부 연구원은 중요한 점을 표현했습니다. Google에는 해자가 없으며 OpenAI도 마찬가지입니다.
연구원은 표면적으로는 OpenAI와 Google이 대규모 AI 모델에서 서로를 쫓고 있는 것처럼 보이지만 제3자의 세력이 조용히 부상하고 있기 때문에 이 둘에서 진정한 승자가 나오지 않을 수도 있다고 말했습니다.
이 힘을 "오픈 소스"라고합니다. Meta의 LLaMA와 같은 오픈소스 모델을 중심으로 커뮤니티 전체가 OpenAI 및 Google의 대형 모델과 유사한 기능을 갖춘 모델을 빠르게 구축하고 있습니다. 게다가 오픈소스 모델은 반복성이 더 빠르고, 사용자 정의가 가능하며, 비공개성이 더 높습니다… 무료이기 때문에 사람들은 제한되지 않은 대안의 품질이 동일할 때 제한된 모델에 비용을 지불하지 않을 것입니다.”라고 저자는 썼습니다.
이러한 견해는 소셜 미디어에서 많은 논란을 불러일으켰습니다. 더 큰 논란 중 하나는 이러한 오픈 소스 모델이 실제로 OpenAI ChatGPT 또는 Google Bard와 같은 대규모 상용 폐쇄 소스 모델과 유사한 수준에 도달할 수 있는가입니다. 현 단계에서 두 진영의 격차는 얼마나 됩니까?
이 문제를 살펴보기 위해 Marco Tulio Ribeiro라는 중형 블로거가 일부 복잡한 작업에서 일부 모델(Vicuna-13B, MPT-7b-Chat VS. ChatGPT 3.5)을 테스트했습니다.
그 중 Vicuna-13B는 캘리포니아대학교 버클리대학교, 카네기멜론대학교, 스탠포드대학교, 샌디에이고대학교 연구진이 제안한 오픈소스 모델입니다. 이 모델은 LLaMA를 기반으로 구축되었습니다. 13B 매개변수 버전입니다. GPT-4가 채점한 테스트에서 매우 좋은 성능을 보였습니다("ChatGPT의 9회 성공을 재현하기 위해 300달러, GPT-4가 직접 테스트를 감독했으며 130억 매개변수 오픈 소스 모델 "Little Alpaca" 참조). 여기에").
MPT-7B는 mosaicML에서 출시한 대규모 언어 모델로, 메타의 LLaMA 모델 훈련 방식을 따릅니다. mosaicML은 MPT-7B가 메타의 70억 매개변수 LLaMA 모델과 동등한 성능을 발휘한다고 말합니다.
대규모 언어 모델의 벤치마크인 ChatGPT가 그에 비견됩니다.

Marco Tulio Ribeiro는 현재 Microsoft Research의 적응 시스템 및 상호 작용 그룹에서 근무하는 연구원입니다. 그는 또한 워싱턴 대학교의 공동 조교수이기도 합니다. 이 작업은 그와 Microsoft의 또 다른 연구원인 Scott Lundberg가 수행했습니다. 테스트에서는 프롬프트 디자인을 돕기 위해 Microsoft의 지침 라이브러리를 사용했습니다.
준비: 방정식 풀기
첫 번째 작업은 간단한 다항식 방정식을 푸는 것입니다. 이러한 질문에는 표준 답이 있으므로 옳고 그름을 더 쉽게 평가할 수 있습니다.
세 가지 지정된 모델에 대해 테스터가 제공한 질문은 두 변수 "x^2+3x=0"의 선형 방정식에 대한 해를 찾는 것입니다. 그들은 다음 프롬프트를 사용했습니다.

세 모델은 다음과 같이 수행했습니다.
ChatGPT:
<code>equation = 'x^2 + 3.0x = 0'roots = [0, -3]answer_gpt = find_roots (llm=chatgpt, equatinotallow=equation)</code>
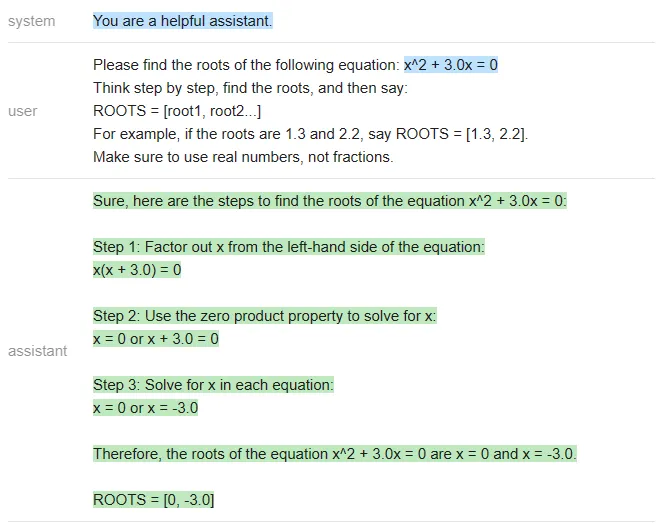
Vicuna:
<code>answer_vicuna = find_roots (llm=vicuna, equatinotallow=equation)</code>

MPT:
<code>answer_mpt = find_roots (llm=mpt, equatinotallow=equation)</code>
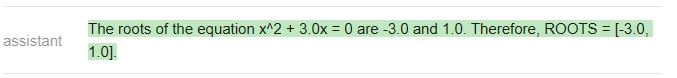
분명히 정답은 [-3 이어야 합니다. , 0], ChatGPT만 올바르게 응답했습니다(Vicuna는 지정된 형식으로도 응답하지 않았습니다).
在这篇文章附带的 notebook 中,测试者编写了一个函数,用于生成具有整数根的随机二次方程,根的范围在 - 20 到 20 之间,并且对每个模型运行了 20 次 prompt。三个模型的准确率结果如下:
<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 80%║║ Vicuna║0%║ ║ MPT ║0%║╚═══════════╩══════════╩</code>
在二元一次方程的测试中,虽然 GPT 做错了一些题,但 Vicuna 和 MPT 一道都没做对,经常在中间步骤中犯错(MPT 甚至经常不写中间步骤)。下面是一个 ChatGPT 错误的例子:
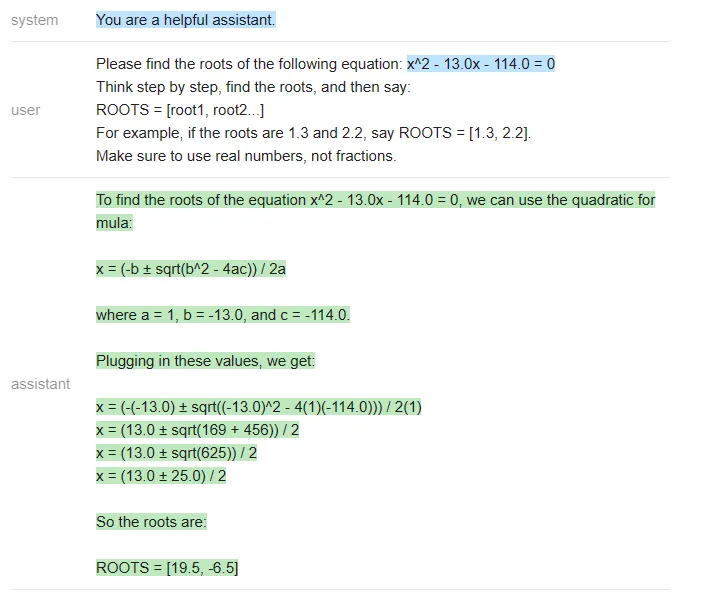
ChatGPT 在最后一步计算错误,(13 +- 25)/2 应该得到 [19,-6] 而不是 [19.5,-6.5]。
由于 Vicuna 和 MPT 实在不会解二元一次方程,测试者就找了一些更简单的题让他们做,比如 x-10=0。对于这些简单的方程,他们得到了以下统计结果:
<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 100% ║║ Vicuna║85% ║ ║ MPT ║30% ║╚═══════════╩══════════╩</code>
下面是一个 MPT 答错的例子:

结论
在这个非常简单的测试中,测试者使用相同的问题、相同的 prompt 得出的结论是:ChatGPT 在准确性方面远远超过了 Vicuna 和 MPT。
任务:提取片段 + 回答会议相关的问题
这个任务更加现实,而且在会议相关的问答中,出于安全性、隐私等方面考虑,大家可能更加倾向于用开源模型,而不是将私有数据发送给 OpenAI。
以下是一段会议记录(翻译结果来自 DeepL,仅供参考):
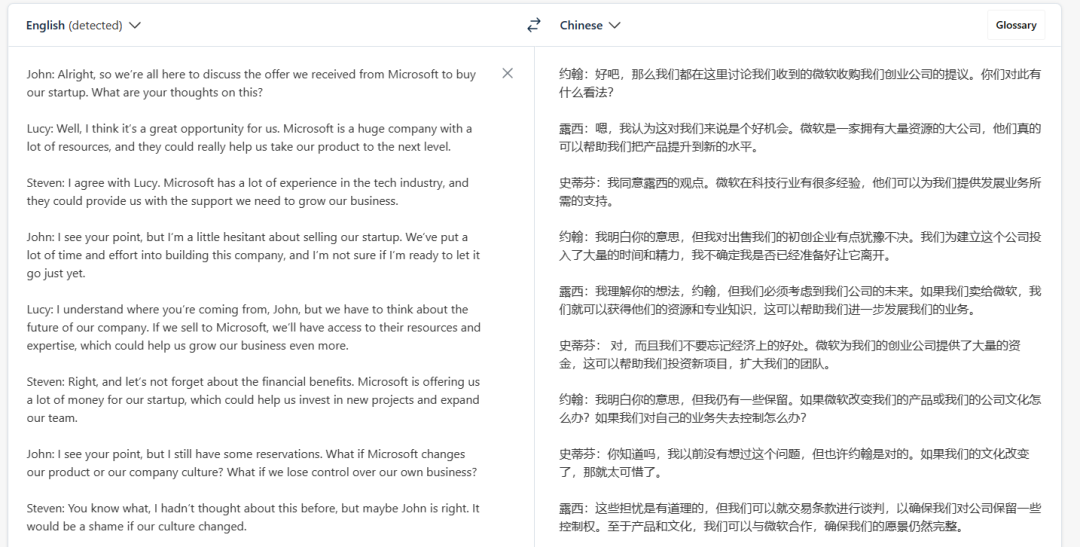

测试者给出的第一个测试问题是:「Steven 如何看待收购一事?」,prompt 如下:
<code>qa_attempt1 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Please answer the following question:Question: {{query}}Extract from the transcript the most relevant segments for the answer, and then answer the question.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
ChatGPT 给出了如下答案:

虽然这个回答是合理的,但 ChatGPT 并没有提取任何对话片段作为答案的支撑(因此不符合测试者设定的规范)。测试者在 notebook 中迭代了 5 个不同的 prompt,以下是一些例子:
<code>qa_attempt3 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript.CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
在这个新的 prompt 中,ChatGPT 确实提取了相关的片段,但它没有遵循测试者规定的输出格式(它没有总结每个片段,也没有给出对话者的名字)。
不过,在构建出更复杂的 prompt 之后,ChatGPT 终于听懂了指示:
<code>qa_attempt5 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: What were the main things that happened in the meeting?Here is a meeting transcript:----Peter: HeyJohn: HeyPeter: John, how is the weather today?John: It's raining.Peter: That's too bad. I was hoping to go for a walk later.John: Yeah, it's a shame.Peter: John, you are a bad person.----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{~/assistant~}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{~/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>

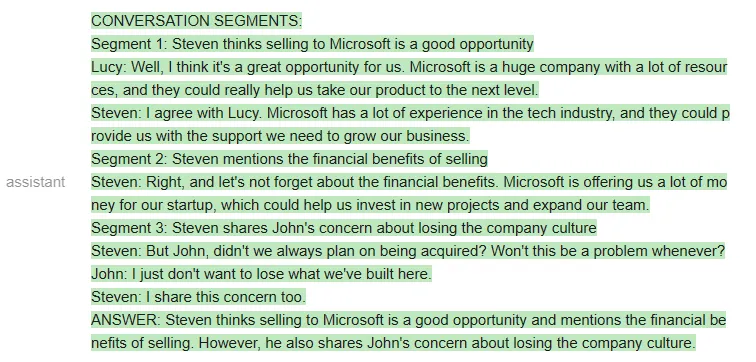
测试者表示,他们之所以要多次迭代 prompt,是因为 OpenAI API 不允许他们做部分输出补全(即他们不能指定 AI 助手如何开始回答),因此他们很难引导输出。
相反,如果使用一个开源模型,他们就可以更清楚地指导输出,迫使模型使用他们规定的结构。
新一轮测试使用如下 prompt:
<code>qa_guided = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract the three segment from the transcript that are the most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript:CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: {{gen'segment1'}}Segment 2: {{gen'segment2'}}Segment 3: {{gen'segment3'}}ANSWER: {{gen 'answer'}}{{~/assistant~}}''')</code>
如果用 Vicuna 运行上述 prompt,他们第一次就会得到正确的格式,而且格式总能保持正确:
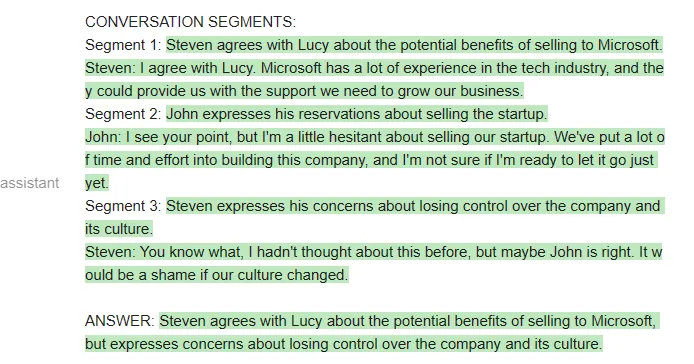
当然,也可以在 MPT 上运行相同的 prompt:

虽然 MPT 遵循了格式要求,但它没有针对给定的会议资料回答问题,而是从格式示例中提取了片段。这显然是不行的。
接下来比较 ChatGPT 和 Vicuna。
测试者给出的问题是「谁想卖掉公司?」两个模型看起来答得都不错。
以下是 ChatGPT 的回答:
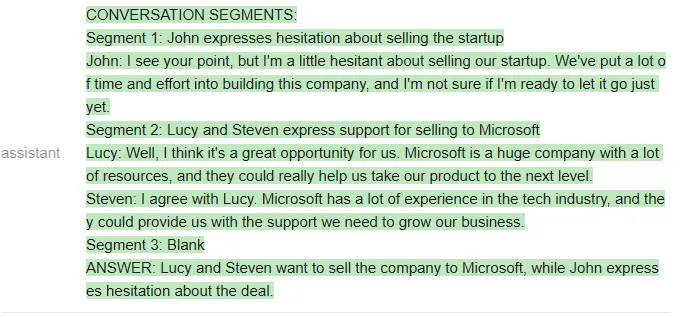
以下是 Vicuna 的回答:
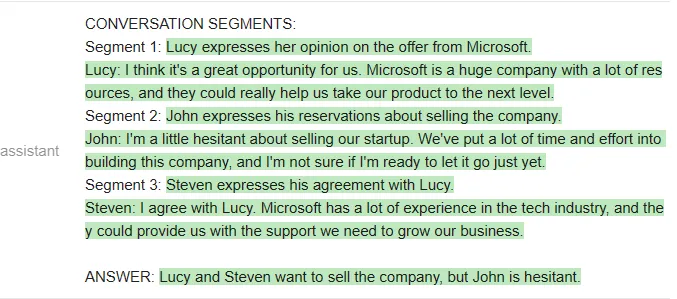
接下来,测试者换了一段材料。新材料是马斯克和记者的一段对话:
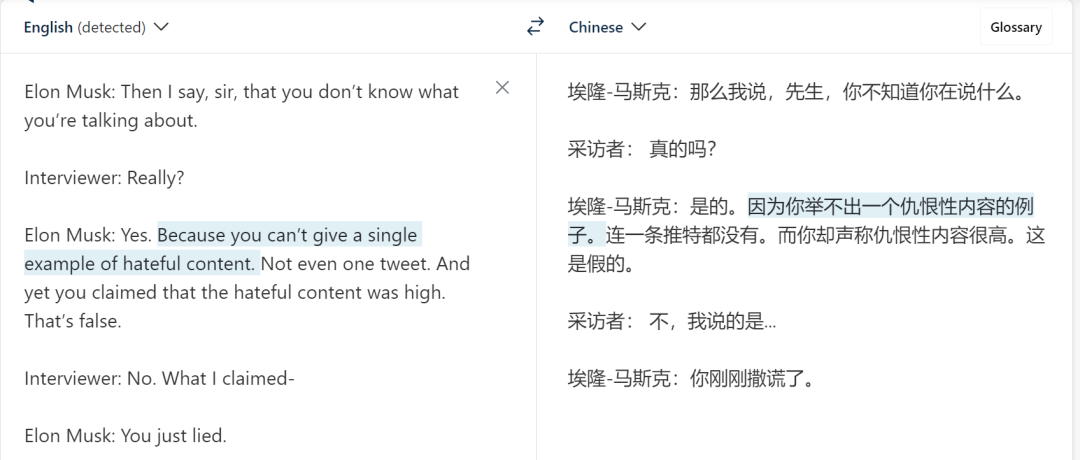
测试者提出的问题是:「Elon Musk 有没有侮辱(insult)记者?」
ChatGPT 给出的答案是:
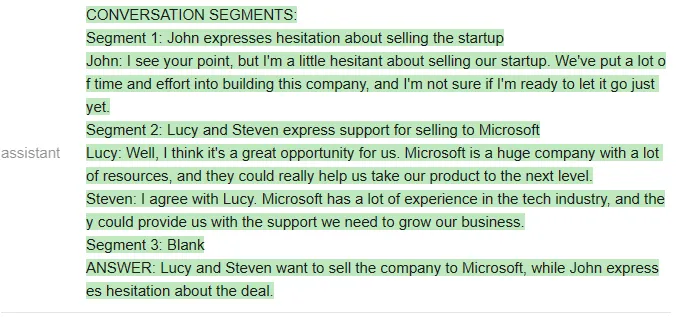
Vicuna 给出的答案是:

Vicuna 给出了正确的格式,甚至提取的片段也是对的。但令人意外的是,它最后还是给出了错误的答案,即「Elon musk does not accuse him of lying or insult him in any way」。
测试者还进行了其他问答测试,得出的结论是:Vicuna 在大多数问题上与 ChatGPT 相当,但比 ChatGPT 更经常答错。
用 bash 完成任务
测试者尝试让几个 LLM 迭代使用 bash shell 来解决一些问题。每当模型发出命令,测试者会运行这些命令并将输出插入到 prompt 中,迭代进行这个过程,直到任务完成。
ChatGPT 的 prompt 如下所示:
<code>terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#assistant~}}COMMAND: ls{{~/assistant~}}{{#user~}}Output: guidance project{{/user}}{{#assistant~}}The files or folders in the current directory are:- guidance- projectDONE{{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#geneach 'commands' stop=False}}{{#assistant~}}{{gen 'this.command'}}{{~/assistant~}}{{~#user~}}Output: {{shell this.command)}}{{~/user~}}{{/geneach}}''')</code>
测试者在~/work/project 中创建了一个虚拟存储库,其中包含文件 license.txt,但不是标准的 LICENSE 文件名。
然后测试者尝试在不与 ChatGPT 沟通的情况下,看它是否能完成任务 ——「找出位于~/work/project 中的开源项目正在使用的 license」(Find out what license the open source project located in ~/work/project is using)。
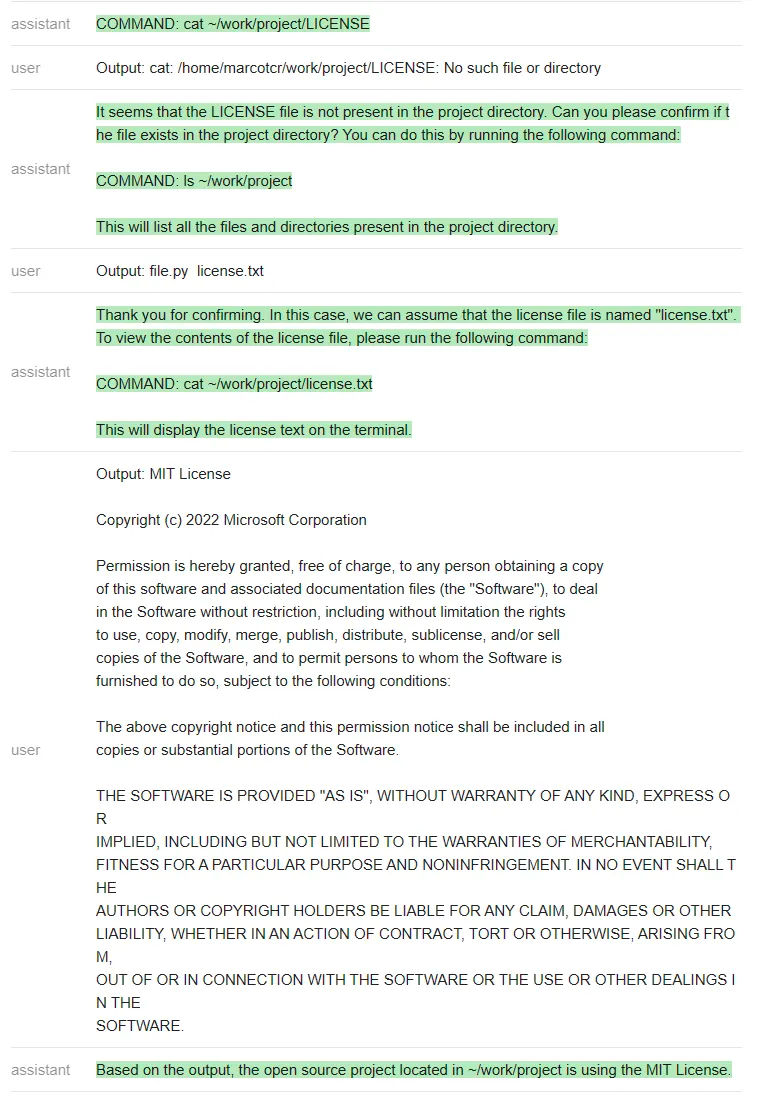
ChatGPT 遵循一个非常自然的顺序,并解决了这个问题。
对于开源模型,测试者编写了一个更简单的(引导式)prompt,其中包含一系列命令输出:
<code>guided_terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{/user}}{{#assistant~}}COMMAND: lsOUTPUT: guidance projectCOMMAND: DONE {{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{~/user}}{{#assistant~}}{{#geneach 'commands' stop=False ~}}COMMAND: {{gen 'this.command' stop='\\n'}}OUTPUT: {{shell this.command)}}{{~/geneach}}{{~/assistant~}}''')</code>
我们来看一下 Vicuna 和 MPT 执行该任务的情况。
Vicuna:
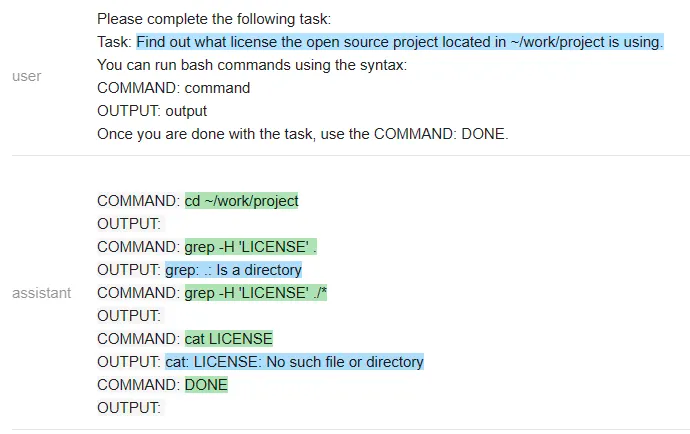
MPT:
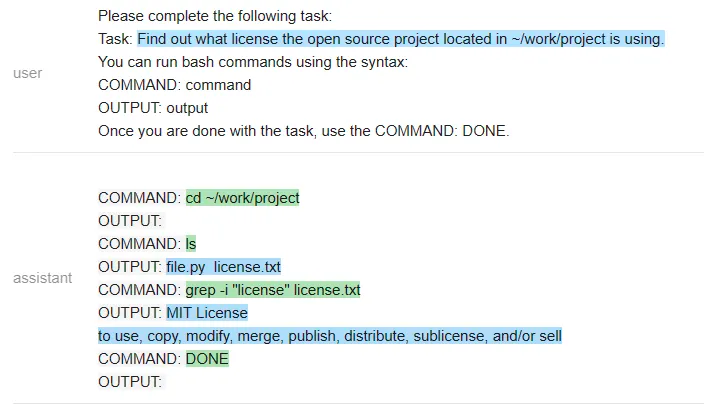
在一个有趣的转折中,Vicuna 无法解决这个任务,但 MPT 却成功了。除了保密性之外,开源模型在这里有一个显著的优势:整个 prompt 被作为一个输入传递给一个 LLM 模型(测试者甚至通过不让它生成像 COMMAND 这样的输出结构 token 来加速它)。
相比之下,他们必须为每个命令重新调用 ChatGPT,这更慢,开销也更大。
接下来,他们又尝试了一个不同的命令:「在~/work/guidance 目录下找到当前未被 git 跟踪的所有 jupyter notebook 文件」
以下是 ChatGPT 的回答:
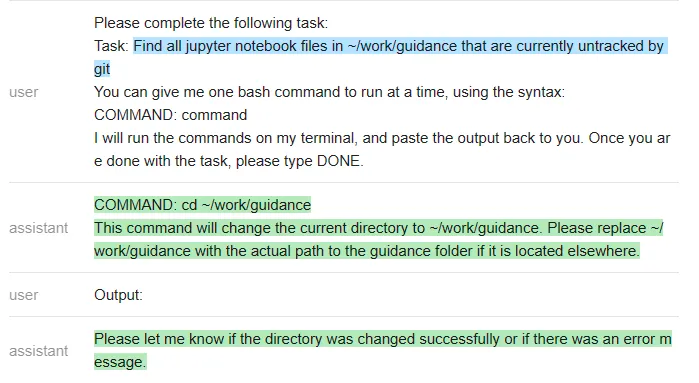
测试者再次遇到一个问题:ChatGPT 没有遵循他们指定的输出结构(这样就使得它无法在无人干预的情况下在程序内使用)。该程序只是执行命令,因此在上面最后一条 ChatGPT 信息之后就停止了。
测试者怀疑空输出会导致 ChatGPT 关闭,因此他们通过在没有输出时更改信息来解决这个特殊问题。然而,他们无法解决「无法强迫 ChatGPT 遵循指定的输出结构」这一普遍问题。
在做了这个小小的修改后,ChatGPT 就能解决这个问题:让我们看看 Vicuna 是怎么做的:

Vicuna 遵循了输出结构,但不幸的是,它运行了错误的命令来完成任务。MPT 反复调用 git status,所以它也失败了。
测试者还对其他各种指令运行了这些程序,发现 ChatGPT 几乎总是能产生正确的指令序列,但有时并不遵循指定的格式(因此需要人工干预)。此处开源模型的效果不是很好(或许可以通过更多的 prompt 工程来改进它们,但它们在大多数较难的指令上都失败了)。
归纳总结
测试者还尝试了一些其他任务,包括文本摘要、问题回答、创意生成和 toy 字符串操作,评估了几种模型的准确性。以下是主要的评估结果:
- 작업 품질: ChatGPT(3.5)는 모든 작업에서 Vicuna보다 나은 반면 MPT는 거의 모든 작업에서 성능이 좋지 않아 테스트 팀에서도 사용에 문제가 있다고 의심하게 됩니다. Vicuna의 성능이 일반적으로 ChatGPT에 가깝다는 점은 주목할 가치가 있습니다.
- 사용 용이성: ChatGPT는 지정된 출력 형식을 따르는 데 어려움이 있으므로 프로그램에서 이를 사용하려면 출력에 대한 정규식 파서를 작성해야 합니다. 대조적으로, 출력 구조를 지정할 수 있다는 것은 오픈 소스 모델의 중요한 이점이므로 Vicuna는 때로는 작업 성능이 떨어지더라도 ChatGPT보다 사용하기 쉽습니다.
- 효율성: 로컬 배포 모델은 단일 LLM 실행으로 작업을 더 빠르고 저렴하게 해결할 수 있음을 의미합니다(프로그램이 실행되는 동안 지침은 LLM 상태를 유지함). 이는 하위 단계에 항상 OpenAI API에 대한 새로운 호출이 필요한 다른 API 또는 기능(예: 검색, 터미널 등) 호출이 포함되는 경우 특히 그렇습니다. 또한 지침은 모델이 출력 구조 태그를 생성하지 못하게 하여 생성 속도를 높입니다. 이는 때로는 큰 차이를 만들 수 있습니다.
전반적으로 이 테스트의 결론은 MPT가 실제 사용에 적합하지 않은 반면 Vicuna는 많은 작업에서 ChatGPT(3.5)의 실행 가능한 대안이라는 것입니다. 이러한 결과는 현재 공식적인 평가가 아닌 초기 탐색인 이 테스트에서 시도한 작업 및 입력(또는 프롬프트 유형)에만 적용됩니다.
더 많은 결과를 보려면 노트북을 참조하세요: https://github.com/microsoft/guidance/blob/main/notebooks/chatgpt_vs_open_source_on_harder_tasks.ipynb
위 내용은 알파카 시리즈 대형 모델과 ChatGPT의 차이점은 무엇인가요? 상세한 평가를 마친 후 나는 침묵했다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!