
GPT-4의 32k 입력 상자가 아직 충분하지 않습니까? Unlimiformer는 컨텍스트 길이를 무한 길이로 늘립니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-19 15:19:061501검색
Transformer는 현재 가장 강력한 seq2seq 아키텍처입니다. 사전 학습된 변환기에는 일반적으로 512(예: BERT) 또는 1024(예: BART) 토큰의 컨텍스트 창이 있으며, 이는 많은 현재 텍스트 요약 데이터 세트(XSum, CNN/DM)에 대해 충분히 깁니다.
그러나 16384는 책 요약(Krys-'cinski et al., 2021) 또는 서술형 질문 및 답변(Kociský et al. , 2018), 100,000개 이상의 토큰을 입력해야 하는 경우가 많습니다. Wikipedia 기사(Liu* et al., 2018)에서 생성된 챌린지 세트에는 500,000개 이상의 토큰 입력이 포함되어 있습니다. 생성적 질문 답변의 오픈 도메인 작업은 Wikipedia에 있는 모든 생존 작가의 기사 집계 속성에 대한 질문에 답변하는 등 더 큰 입력으로부터 정보를 합성할 수 있습니다. 그림 1은 일반적인 컨텍스트 창 길이에 대한 여러 인기 요약 및 Q&A 데이터세트의 크기를 보여줍니다. 가장 긴 입력은 Longformer의 컨텍스트 창보다 34배 이상 깁니다.
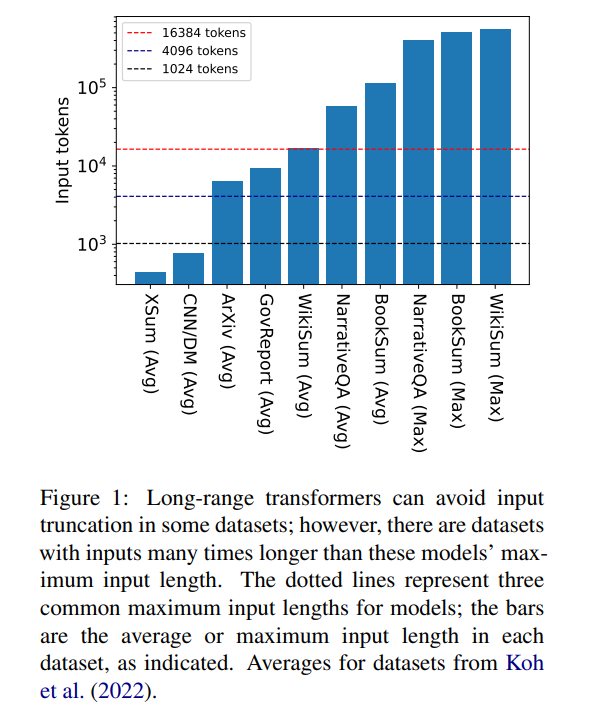
이렇게 매우 긴 입력의 경우 네이티브 어텐션 메커니즘이 2차 복잡성을 갖기 때문에 바닐라 변환기는 확장할 수 없습니다. 긴 입력 변환기는 표준 변환기보다 효율적이지만 컨텍스트 창 크기가 증가함에 따라 증가하는 상당한 계산 리소스가 필요합니다. 또한 컨텍스트 창을 늘리려면 새로운 컨텍스트 창 크기로 모델을 처음부터 다시 학습해야 하는데, 이는 계산적으로나 환경적으로 비용이 많이 듭니다.
카네기멜론대학교 연구진은 "Unlimiformer: Long-Range Transformers with Unlimited Length Input"이라는 기사에서 Unlimiformer를 소개했습니다. 이는 테스트 시 무한 길이의 입력을 허용하도록 사전 훈련된 언어 모델을 강화하는 검색 기반 접근 방식입니다.

문서 링크: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer는 기존 인코더-디코더 변환기에 주입할 수 있으며 무제한 길이의 입력을 처리할 수 있습니다. . 긴 입력 시퀀스가 주어지면 Unlimiformer는 모든 입력 토큰의 숨겨진 상태에 데이터 저장소를 구축할 수 있습니다. 그러면 디코더의 표준 교차 주의 메커니즘이 데이터 저장소를 쿼리하고 상위 k개 입력 토큰에 집중할 수 있습니다. 데이터 저장소는 GPU 또는 CPU 메모리에 저장될 수 있으며 하위 선형적으로 쿼리될 수 있습니다.
Unlimiformer는 훈련된 모델에 직접 적용할 수 있으며 추가 훈련 없이 기존 체크포인트를 개선할 수 있습니다. Unlimiformer는 성능을 더욱 향상시키기 위해 미세 조정되었습니다. 이 논문은 Unlimiformer가 가중치를 추가하거나 재교육하지 않고도 BART(Lewis et al., 2020a) 또는 PRIMERA(Xiao et al., 2022)와 같은 여러 기본 모델에 적용될 수 있음을 보여줍니다. 다양한 장거리 seq2seq 데이터 세트에서 Unlimiformer는 Longformer(Beltagy et al., 2020b), SLED(Ivgi et al., 2022) 및 Memorizing Transformer(Wu et al., 2021)와 같은 장거리 Transformer보다 강력할 뿐만 아니라 ) 이러한 데이터 세트에서 성능이 더 좋아졌으며, 이 기사에서는 Longformer 인코더 모델 위에 Unlimiform을 적용하여 추가 개선이 가능하다는 사실도 발견했습니다.
Unlimiformer 기술 원리
인코더 컨텍스트 창의 크기가 고정되어 있으므로 Transformer의 최대 입력 길이가 제한됩니다. 그러나 디코딩 중에는 다양한 정보가 관련될 수 있습니다. 더욱이 다양한 주의 헤드가 다양한 유형의 정보에 집중할 수 있습니다(Clark et al., 2019). 따라서 고정된 컨텍스트 창은 주의가 덜 집중되는 토큰에 노력을 낭비할 수 있습니다.
각 디코딩 단계에서 Unlimiformer의 각 어텐션 헤드는 모든 입력에서 별도의 컨텍스트 창을 선택합니다. 이는 Unlimiformer 조회를 디코더에 주입하여 달성됩니다. 교차 주의 모듈에 들어가기 전에 모델은 외부 데이터 저장소에서 kNN(k-nearest neighbor) 검색을 수행하고 각 디코더 계층의 각 주의 헤드 세트를 선택합니다. 참여 토큰.
인코딩
모델의 컨텍스트 창 길이보다 긴 입력 시퀀스를 인코딩하기 위해 이 기사에서는 Ivgi et al.(2022)(Ivgi et al., 2022)의 방법에 따라 입력 중첩 블록을 인코딩하고 각 블록만 유지합니다. 인코딩 프로세스 전후에 충분한 컨텍스트를 보장하기 위해 출력의 중간 절반을 청크합니다. 마지막으로 이 기사에서는 Faiss(Johnson et al., 2019)와 같은 라이브러리를 사용하여 데이터 저장소의 인코딩된 입력을 색인화합니다(Johnson et al., 2019).
향상된 교차 주의 메커니즘 검색
표준 교차 주의 메커니즘에서 변환기의 디코더는 인코더의 최종 숨겨진 상태에 초점을 맞추고 인코더는 일반적으로 입력을 자르고 첫 번째 k 토큰이 인코딩됩니다.
이 기사는 입력의 첫 번째 k 토큰에만 초점을 맞추는 것이 아니라 각 교차 주의 헤드에 대해 더 긴 입력 계열의 첫 번째 k 숨겨진 상태를 검색하고 첫 번째 k에만 초점을 맞춥니다. 이를 통해 키워드를 자르지 않고 전체 입력 시퀀스에서 키워드를 검색할 수 있습니다. 우리의 접근 방식은 모든 입력 토큰을 처리하는 것보다 계산 및 GPU 메모리 측면에서 저렴하면서도 일반적으로 주의 성능을 99% 이상 유지합니다.
그림 2는 seq2seq 변환기 아키텍처에 대한 이 기사의 변경 사항을 보여줍니다. 전체 입력은 인코더를 사용하여 블록 인코딩되고 데이터 저장소에 저장되며, 인코딩된 잠재 상태 데이터 저장소는 디코딩 시 쿼리됩니다. kNN 검색은 비모수적이며 아래에 설명된 대로 사전 훈련된 seq2seq 변환기에 주입될 수 있습니다.
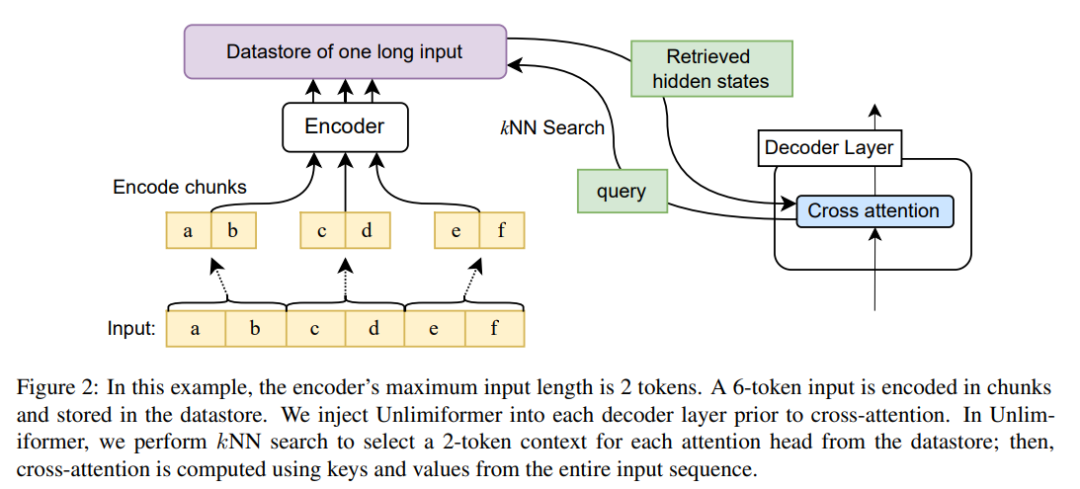
실험 결과
긴 문서 요약
표 3은 긴 텍스트(4k 및 16k 토큰 입력) 요약 데이터 세트의 결과를 보여줍니다.
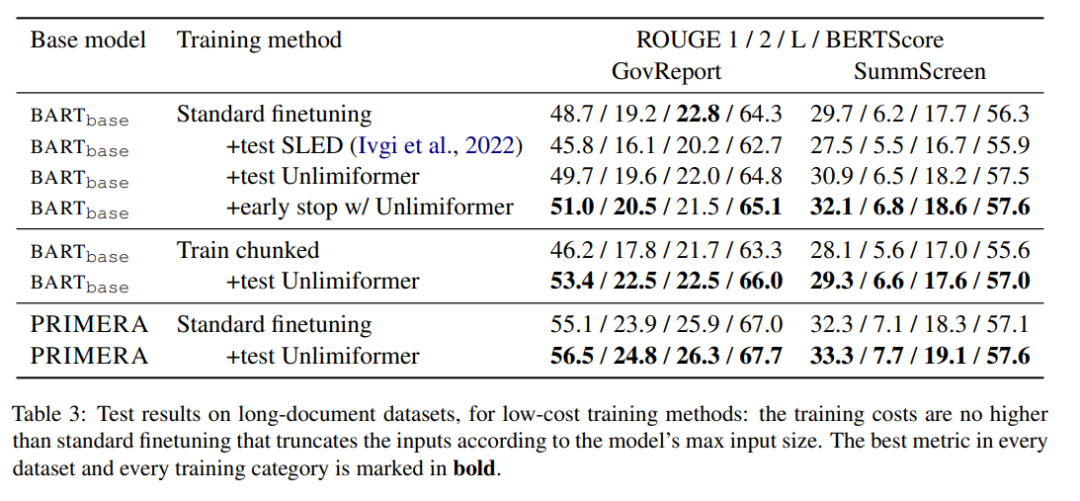
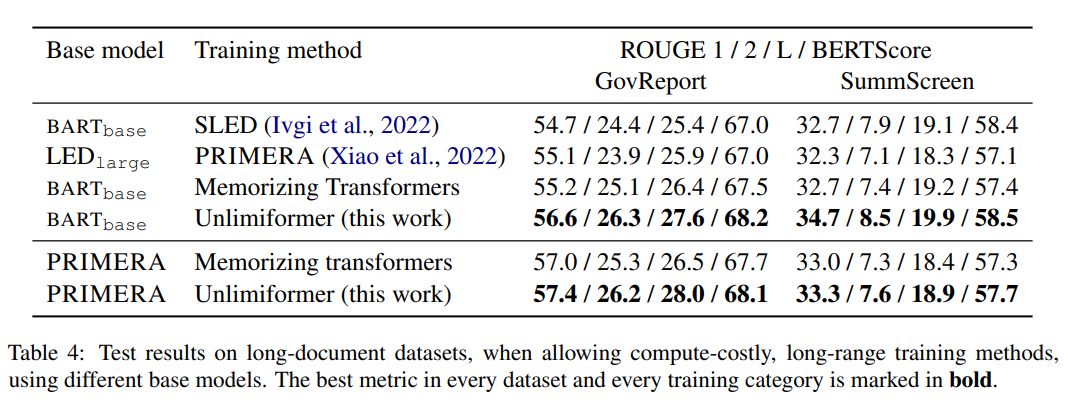
표 4의 훈련 방법 중 Unlimiformer는 다양한 지표에서 가장 좋은 결과를 얻을 수 있습니다.
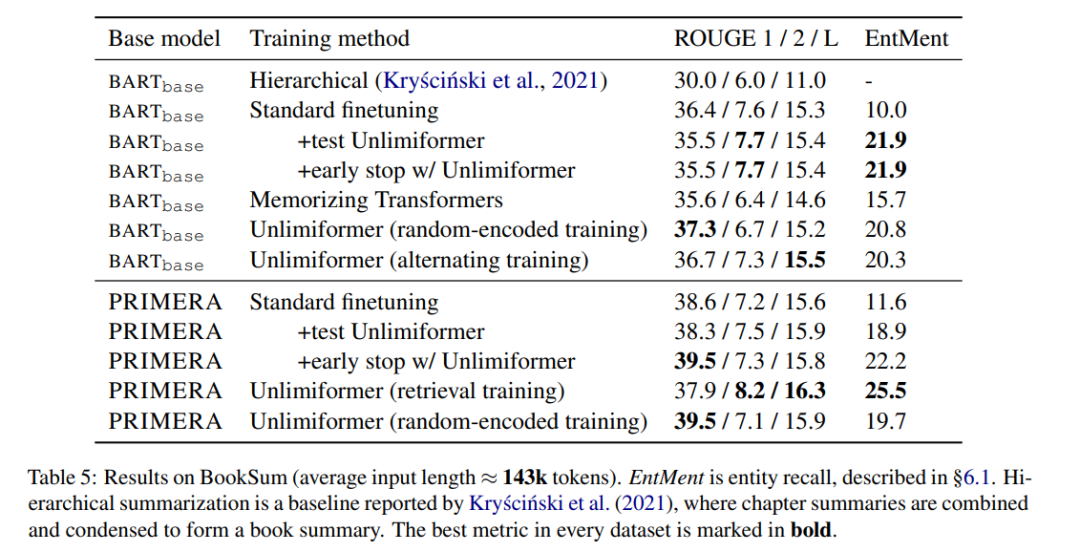
도서 요약
표 5는 도서 요약 결과를 보여줍니다. BARTbase와 PRIMERA를 기반으로 Unlimiformer를 적용하면 확실한 개선 결과를 얻을 수 있음을 알 수 있습니다.
위 내용은 GPT-4의 32k 입력 상자가 아직 충분하지 않습니까? Unlimiformer는 컨텍스트 길이를 무한 길이로 늘립니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!