
시계열을 분류 문제로 변환

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-18 22:12:201288검색
이 글에서는 주식 거래를 예로 들어보겠습니다. 우리는 AI 모델을 사용하여 다음날 주식이 상승할지 하락할지 예측합니다. 이러한 맥락에서 XGBoost, Random Forest 및 Logistic Classifier의 세 가지 분류 알고리즘을 비교합니다. 이 기사의 또 다른 초점은 데이터 준비입니다. 모델이 데이터를 처리할 수 있도록 데이터를 어떻게 변환해야 합니까?

이 기사에서는 CRISP-DM 프로세스 모델의 단계를 따르고 구조화된 접근 방식을 사용하여 비즈니스 사례를 해결합니다. CRISP-DM은 잠재 분석에서 널리 사용되는 방법이며 데이터 과학 프로젝트 구축에 자주 사용됩니다.
또 다른 점은 Python 패키지 openbb를 사용한다는 것입니다. 이 패키지에는 금융 부문의 일부 데이터 소스가 포함되어 있으며 사용이 매우 쉽습니다.
첫 번째 단계는 필요한 라이브러리를 설치하는 것입니다.
<code>pip install pandas numpy “openbb[all]” swifter scikit-learn</code>
비즈니스 이해
먼저 우리가 해결하려는 문제를 이해해야 합니다. 이 예에서 문제는 다음과 같이 정의될 수 있습니다.
<code>预测股票代码 AAPL 的股价第二天会上涨还是下跌。</code>
그런 다음 무엇을 고려해야 합니다. 우리가 가지고 있는 기계의 종류 모델 학습의 문제. 우리는 주가가 다음날 상승할지 하락할지 예측하고 싶습니다. 따라서 여기서 다루는 것은 다음 날 주식이 상승(값 1)할지 하락(값 0)할지 예측하려는 이진 분류 문제입니다. 분류 문제에서는 클래스를 예측합니다. 우리의 경우 클래스 0과 1의 이진 분류입니다.
데이터 이해 및 준비
데이터 이해 단계에서는 데이터 세트를 식별, 수집 및 분석하는 데 중점을 둡니다. 첫 번째 단계로 Apple 주식 데이터를 다운로드합니다. openbb를 사용하여 수행하는 방법은 다음과 같습니다.
<code>data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False) data</code>
이 코드는 2023-01-01과 2023-04-01 사이의 데이터를 다운로드합니다. 다운로드된 데이터에는 다음 정보가 포함됩니다.
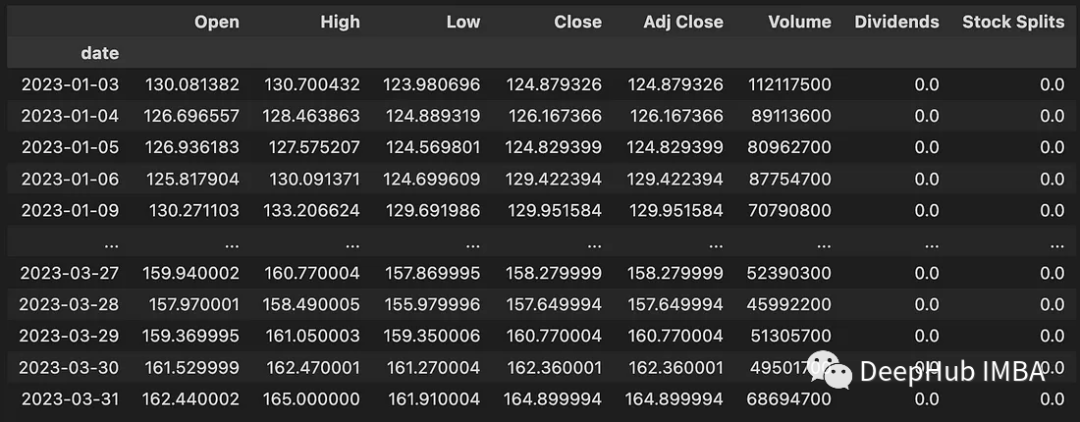
- Open: 일일 개장가(USD)
- High: 당일 최고 가격(USD)
- Low: 당일 최저 가격(USD)
- Close: 매일 USD의 종가
- Adj Close: 배당금 또는 주식 분할과 관련된 조정된 종가
- Volume: 거래된 주식 수
- Dividends: 배당금 지급
- Stock Splits: 주식 분할 실행
데이터를 다운로드했지만 데이터가 아직 제공되지 않습니다. 분류 모델 모델링에 적합하지 않습니다. 따라서 모델링을 위해 데이터를 준비해야 합니다. 따라서, 데이터를 다운로드한 후 모델링을 위해 데이터를 변환하는 기능의 개발이 필요하다. 다음 코드는 이 함수를 보여줍니다.
<code>def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10): data = openbb.stocks.load( symbol = symbol, start_date = start_date, end_date = end_date, monthly = monthly_bool) data = get_label(data) data_up_down = data['up_down'].to_numpy() training_data = get_sequence_data(data_up_down, lookback) return training_data</code>
여기에 포함된 첫 번째 함수는 get_label()입니다.
<code>def encoding(n): if n > 0: return 1 else: return 0 def get_label(data): data['Delta'] = data['Close'] - data['Open'] data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d)) return data</code>
그의 주요 업무는 종가와 시가의 차이를 계산하는 것입니다. 주가가 상승한 날은 모두 1로, 주가가 하락한 날은 모두 0으로 표시합니다. 추가 up_down 열에는 특정 날짜에 주가가 상승 또는 하락했는지 여부가 포함됩니다. 여기서는 Swifter가 멀티 코어 지원을 제공하므로 pandas apply() 대신 Swifter.apply() 함수가 사용됩니다.
두 번째 함수는 get_sequence_data()입니다. 매개변수 전환은 예측에 포함되는 과거 일수를 지정합니다. get_sequence_data() 코드는 다음과 같습니다:
<code>def get_sequence_data(data_up_down, lookback): shape = (data_up_down.shape[0] - lookback + 1, lookback) strides = data_up_down.strides + (data_up_down.strides[-1],) return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)</code>
이 함수는 data_up_down 및 Lookback이라는 두 가지 매개변수를 허용합니다. 이는 Lookback 인수에 의해 결정된 지정된 창 크기를 사용하여 data_up_down 배열의 슬라이딩 창 보기를 나타내는 새로운 NumPy 배열을 반환합니다. 이 함수의 작동 방식을 설명하기 위해 작은 예를 살펴보겠습니다.
<code>get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)</code>
결과는 다음과 같습니다.
<code>array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])</code>
아래에서는 Apple 주식에 대한 데이터를 다운로드하여 모델링용으로 변환합니다. 우리는 10일의 전환 확인 기간을 사용합니다.
<code>data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10) pd.DataFrame(data).to_csv("data/data_aapl.csv")</code>
데이터가 준비되었습니다. 모델 모델링 및 평가를 시작하겠습니다.
Modeling
데이터를 읽고 테스트 및 교육 데이터를 생성합니다.
<code>data = pandas.read_csv("./data/data_aapl.csv") X=data.iloc[:,:-1] Y=data.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)</code>
로지스틱 회귀:
이 분류자는 선형 기반 모델이며 기준 모델로 자주 사용됩니다. 우리는 scikit-learn의 구현을 사용합니다:
<code>model_lr = LogisticRegression(random_state = 42) model_lr.fit(X_train,y_train) y_pred = model_lr.predict(X_test)</code>
XGBoost:
XGBoost는 속도와 성능을 위해 설계된 그래디언트 강화 결정 트리의 구현입니다. 다수의 약한 트리 분류기를 순차적으로 연결하는 트리 부스팅 알고리즘에 속합니다.
<code>model_xgb = XGBClassifier(random_state = 42) model_xgb.fit(X_train, y_train) y_pred = model_xgb.predict(X_test)</code>
랜덤 포레스트:
랜덤 포레스트는 여러 의사결정 트리를 구축합니다. 배깅 방법은 상호 연결된 여러 학습자를 학습에 활용하기 때문에 일종의 앙상블 학습이라고 합니다. "배깅"이라는 약어는 부트스트랩 집계를 나타냅니다. scikit-learn 구현은 여기에서도 사용됩니다.
<code>model_rf = RandomForestClassifier(random_state = 42) model_rf.fit(X_train, y_train) y_pred = model_rf.predict(X_test)</code>
Evaluation
모델을 모델링하고 훈련한 후에는 테스트 데이터에 대한 성능을 평가해야 합니다. Recall, Precision 및 F1-Score는 메트릭을 측정하는 데 사용됩니다. 아래 표는 결과를 보여줍니다.
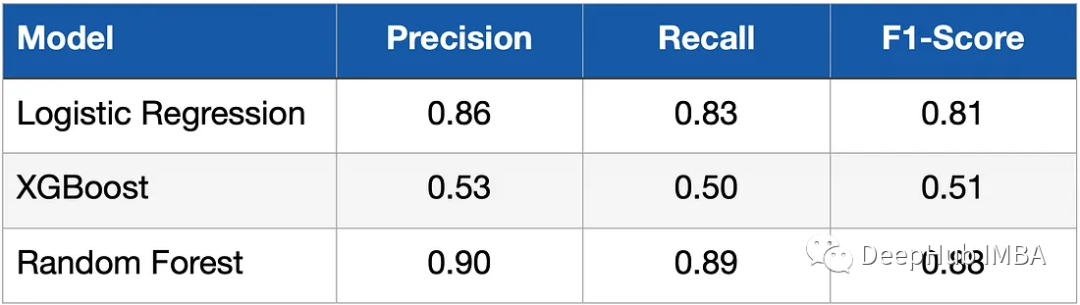
로지스틱 분류기(로지스틱 회귀)와 랜덤 포레스트가 XGBoost 모델보다 훨씬 좋은 결과를 얻었음을 알 수 있는 이유는 무엇인가요? 이는 데이터가 상대적으로 단순하고 특성의 차원이 적고 데이터 길이도 매우 작으며 모든 모델이 조정되지 않았기 때문입니다.
요약
저희 글의 주요 목적은 주가의 시계열을 분류 문제로 변환하는 방법을 소개하고, 데이터 처리 중에 윈도우 기능을 사용하여 시계열을 시퀀스로 변환하는 방법을 보여주는 것입니다. 단순한 모델이 성능 평가를 더 잘 수행할 수 있도록 튜닝이 많이 수행되지 않습니다.
위 내용은 시계열을 분류 문제로 변환의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!