
증류는 단계별로 수행할 수도 있습니다. 새로운 방법을 사용하면 소형 모델을 2000배 더 큰 대형 모델과 비교할 수 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-18 18:31:30876검색
대규모 언어 모델은 놀라운 기능을 갖추고 있지만 규모가 크기 때문에 배포에 필요한 비용이 막대한 경우가 많습니다. 워싱턴대학교는 Google Cloud Computing Artificial Intelligence Research Institute 및 Google Research와 함께 이 문제를 더욱 해결하고 모델 훈련에 도움이 되는 Distilling Step-by-Step 패러다임을 제안했습니다. LLM에 비해 이 방법은 소규모 모델을 훈련하고 이를 특정 작업에 적용하는 데 더 효과적이며 기존의 미세 조정 및 증류보다 훈련 데이터가 덜 필요합니다. 벤치마크 작업에서 770M T5 모델이 540B PaLM 모델보다 성능이 뛰어났습니다. 놀랍게도 그들의 모델은 사용 가능한 데이터의 80%만 사용했습니다.

대형 언어 모델(LLM)은 인상적인 소수 학습 기능을 보여주었지만 이러한 대규모 모델을 실제 애플리케이션에 배포하는 것은 어렵습니다. 1,750억 매개변수 규모의 LLM을 제공하는 전용 인프라에는 최소 350GB의 GPU 메모리가 필요합니다. 게다가 오늘날의 최첨단 LLM은 5,000억 개가 넘는 매개변수로 구성되어 있으며, 이는 더 많은 메모리와 컴퓨팅 리소스가 필요하다는 것을 의미합니다. 이러한 컴퓨팅 요구 사항은 짧은 대기 시간이 필요한 애플리케이션은 물론이고 대부분의 제조업체에서도 감당할 수 없는 수준입니다.
대형 모델의 이러한 문제를 해결하기 위해 배포자는 종종 더 작은 특정 모델을 대신 사용합니다. 이러한 작은 모델은 미세 조정 또는 증류와 같은 일반적인 패러다임을 사용하여 학습됩니다. 미세 조정은 사람이 주석을 추가한 다운스트림 데이터를 사용하여 사전 훈련된 소규모 모델을 업그레이드합니다. Distillation은 더 큰 LLM에서 생성된 레이블을 사용하여 똑같이 더 작은 모델을 교육합니다. 불행하게도 이러한 패러다임은 모델 크기를 줄이는 동시에 비용이 발생합니다. LLM과 비슷한 성능을 달성하려면 미세 조정에 값비싼 인적 레이블이 필요한 반면, 증류에는 얻기 어려운 레이블이 없는 대량의 데이터가 필요합니다.
"Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes"라는 제목의 논문에서 워싱턴 대학과 Google의 연구원들은 새로운 간단한 메커니즘을 소개했습니다. ——Distilling step-by-step, 더 적은 훈련 데이터를 사용하여 더 작은 모델을 훈련하는 데 사용됩니다. 이 메커니즘은 LLM을 미세 조정하고 정제하는 데 필요한 훈련 데이터의 양을 줄여 모델 크기를 더 작게 만듭니다.

문서 링크: https://arxiv.org/pdf/2305.02301v1.pdf
이 메커니즘의 핵심은 관점을 바꾸고 LLM을 다음과 같은 것으로 간주하는 것입니다. 시끄러운 라벨의 소스가 아닌 추론 에이전트가 될 수 있습니다. LLM은 모델에서 예측한 레이블을 설명하고 지원하는 데 사용할 수 있는 자연어 근거를 생성할 수 있습니다. 예를 들어, "신사가 골프 장비를 갖고 있는데, 그가 갖고 있는 것은 무엇입니까? (a) 클럽, (b) 강당, (c) 명상 센터, (d) 컨퍼런스, (e) 교회"라고 질문하면 LLM은 "(a) ) 클럽'을 CoT(사상연쇄) 추론을 통해 설명하고, '답은 골프를 치는 데 사용되는 것이 틀림없다'고 설명하여 이 라벨을 합리화합니다. 위의 선택 중 골프에는 클럽만 사용됩니다. 우리는 이러한 정당화를 다중 작업 훈련 설정에서 더 작은 모델을 훈련하고 레이블 예측 및 정당화 예측을 수행하기 위한 추가적인 풍부한 정보로 사용합니다.
그림 1에서 볼 수 있듯이 단계적 증류는 특정 작업에 대한 작은 모델을 학습할 수 있으며 이러한 모델의 매개변수 수는 LLM의 1/500 미만입니다. 또한 단계적 증류는 기존의 미세 조정이나 증류보다 훨씬 적은 수의 훈련 예제를 사용합니다.

실험 결과에 따르면 4가지 NLP 벤치마크 중 세 가지 유망한 실험 결론이 있습니다.
- 먼저, 미세 조정 및 증류에 비해 단계적 증류 모델은 다양한 데이터 세트에서 더 나은 성능을 달성하여 훈련 인스턴스를 평균 50% 이상(최대 85% 이상) 줄입니다.
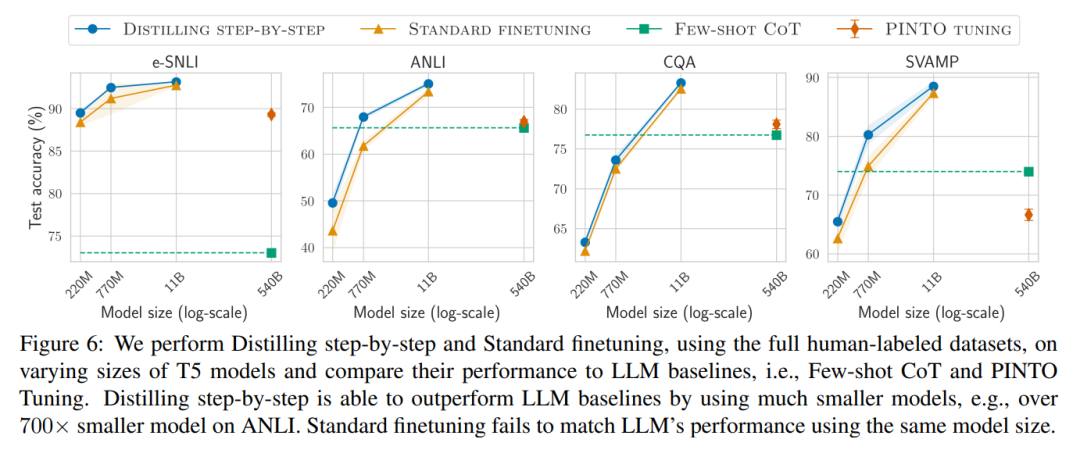
- 둘째, 우리 모델은 더 작은 모델 크기(최대 2000배 더 작음)에서 LLM보다 성능이 뛰어나 모델 배포에 필요한 계산 비용을 크게 줄입니다.
- 셋째, 이 연구는 모델의 크기를 줄이는 동시에 LLM을 능가하는 데 필요한 데이터의 양도 줄였습니다. 연구진은 770M T5 모델을 사용해 540B 매개변수로 LLM의 성능을 능가했다. 이 작은 모델은 기존 미세 조정 방법의 레이블이 지정된 데이터 세트의 80%만 사용합니다.
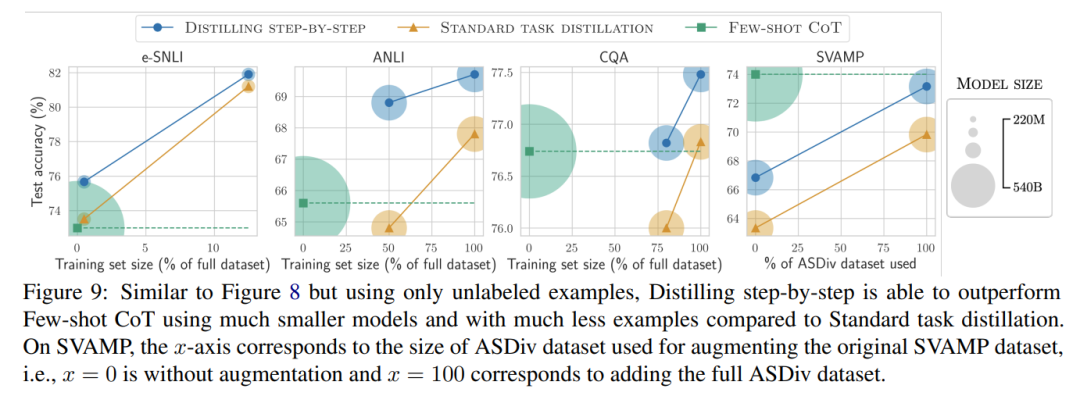
레이블이 지정되지 않은 데이터만 있는 경우에는 소형 모델의 성능이 LLM보다 여전히 좋습니다. 11B T5 모델만 사용해도 540B PaLM의 성능을 초과합니다.
이 연구에서는 더 작은 모델이 LLM보다 성능이 떨어지는 경우 단계적 증류가 표준 증류 방법보다 레이블이 지정되지 않은 추가 데이터를 더 효과적으로 활용하여 더 작은 모델을 LLM의 성능과 비교할 수 있음을 보여줍니다.
단계적 증류
연구원들은 LLM의 추론 능력을 사용하여 예측을 예측하여 데이터 효율적인 방식으로 더 작은 모델을 훈련시키는 단계적 증류의 새로운 패러다임을 제안했습니다. 전체 프레임워크는 그림 2에 나와 있습니다.
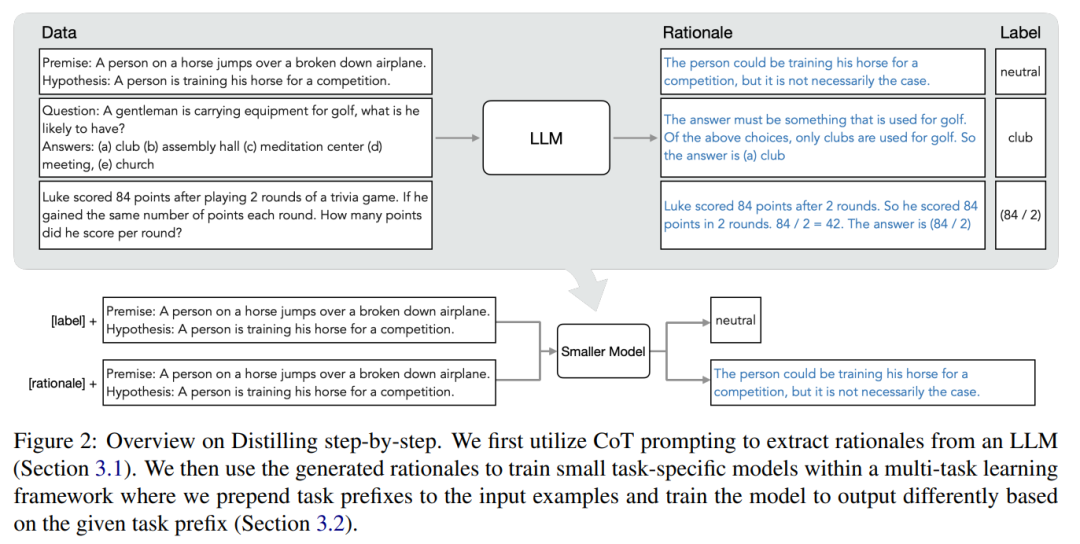
패러다임에는 두 가지 간단한 단계가 있습니다. 첫째, LLM과 레이블이 지정되지 않은 데이터세트가 주어지면 LLM이 출력 레이블과 레이블에 대한 정당성을 생성하도록 요청합니다. 이론적 근거는 자연어로 설명되며 모델에서 예측한 레이블에 대한 지원을 제공합니다(그림 2 참조). 정당화는 현재 자체 감독 LLM의 새로운 행동 속성입니다.
그런 다음 작업 레이블 외에도 이러한 이유를 사용하여 더 작은 다운스트림 모델을 교육합니다. 직설적으로 말하면 이유는 입력이 특정 출력 레이블에 매핑되는 이유를 설명하기 위해 더 풍부하고 자세한 정보를 제공할 수 있습니다.
실험 결과
연구진은 실험을 통해 단계적 증류의 효과를 검증했습니다. 첫째, 표준 미세 조정 및 작업 증류 방법과 비교하여 단계적 증류는 훨씬 적은 수의 훈련 예제로 더 나은 성능을 달성하는 데 도움이 되며 작은 작업별 모델 학습의 데이터 효율성을 크게 향상시킵니다. ㅋㅋㅋ
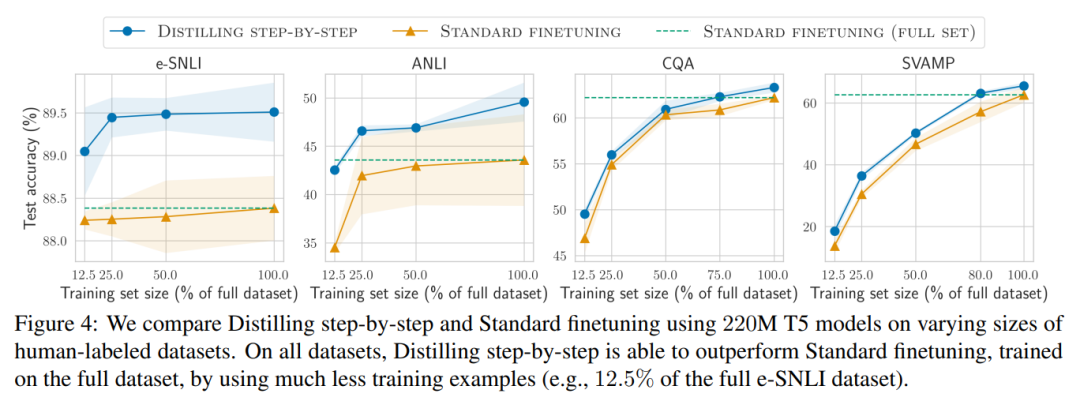
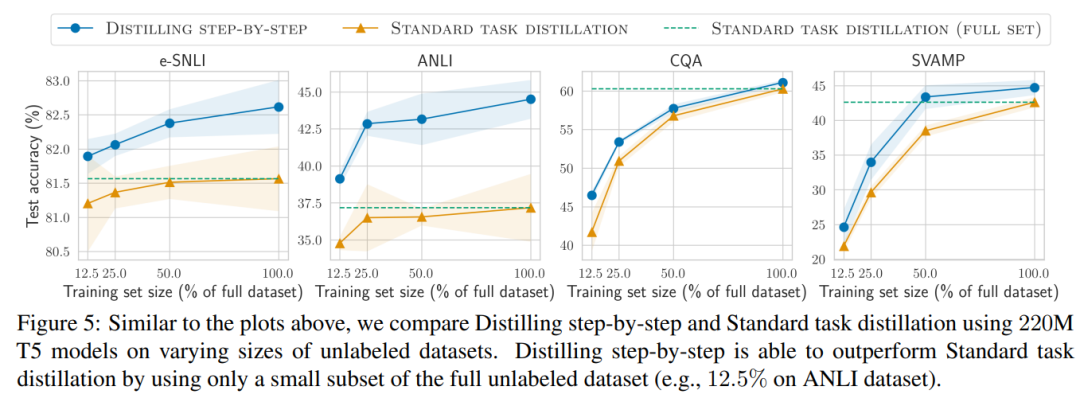
마지막으로 학습 예제 수와 모델 크기를 포함하여 LLM을 초과하는 성능 측면에서 단계적 증류 방법에 필요한 최소 리소스를 조사했습니다. 그들은 단계적 증류 접근 방식이 더 적은 데이터와 더 작은 모델을 사용하여 데이터 효율성과 배포 효율성을 모두 향상시킨다는 것을 보여줍니다.
위 내용은 증류는 단계별로 수행할 수도 있습니다. 새로운 방법을 사용하면 소형 모델을 2000배 더 큰 대형 모델과 비교할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!