
대형 모델이 '오픈 소스 시즌'을 맞이하고 있으며 지난달 오픈 소스 LLM 및 데이터 세트를 보유하고 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-18 16:31:131756검색
얼마 전 유출된 Google 내부 문서에는 표면적으로는 OpenAI와 Google이 대규모 AI 모델을 놓고 서로를 쫓는 것처럼 보이지만 제3자가 있기 때문에 이 둘에서 진정한 승자가 나오지 않을 수도 있다는 견해가 표명되었습니다. 조용히 일어섰다. 이 힘은 "오픈 소스"입니다.
Meta의 LLaMA 오픈 소스 모델을 중심으로 전체 커뮤니티는 OpenAI 및 Google의 대규모 모델과 유사한 기능을 갖춘 모델을 빠르게 구축하고 있습니다. 또한 오픈 소스 모델은 더 빠르게 반복되고, 더 많은 사용자 정의가 가능하며, 더 비공개적입니다.
최근 Wisconsin-Madison 대학의 전 조교수이자 스타트업 Lightning AI의 최고 AI 교육 책임자인 Sebastian Raschka는 오픈 소스의 경우 지난 한 달이 정말 좋았습니다라고 말했습니다.
그러나 너무 많은 대형 언어 모델(LLM)이 속속 등장하고 있으며, 모든 모델을 확고히 파악하는 것은 쉽지 않습니다. 따라서 이 기사에서 Sebastian은 최신 오픈 소스 LLM 및 데이터 세트에 대한 리소스와 연구 통찰력을 공유합니다. ㅋㅋㅋ Sebastian은 단순히 더 강력한 모델을 보여주는 것보다 추가적인 통찰력을 제공하는 논문을 선호합니다. 이런 점에서 그가 가장 먼저 주목한 것은 일루서 AI(Eleuther AI)와 예일대 등 여러 기관의 연구진이 공동 집필한 피티아(Pythia) 논문이었다.
문서 주소: https://arxiv.org/pdf/2304.01373.pdf
 Pythia: 대규모 교육에서 통찰력 얻기
Pythia: 대규모 교육에서 통찰력 얻기
오픈소스 Pythia 시리즈 이 모델은 실제로 다른 자동 회귀 디코더 스타일 모델(예: GPT 유사 모델)에 대한 흥미로운 대안입니다. 이 논문은 훈련 메커니즘에 대한 몇 가지 흥미로운 통찰력을 보여주고 70M에서 12B 매개변수 범위의 해당 모델을 소개합니다.
Pythia 모델 아키텍처는 GPT-3과 유사하지만 Flash attention(예: LLaMA) 및 회전 위치 임베딩(예: PaLM)과 같은 몇 가지 개선 사항이 포함되어 있습니다. 동시에 Pythia는 800GB의 다양한 텍스트 데이터 세트 Pile(일반 파일의 1 에포크, 중복 제거 파일의 1.5 에포크)에서 3000억 개의 토큰으로 훈련되었습니다.
다음은 Pythia 논문의 몇 가지 통찰과 생각입니다.
반복되는 데이터에 대한 교육(예: 교육 epoch>1)이 영향을 미치나요? 결과에 따르면 데이터 중복 제거는 성능을 향상하거나 손상시키지 않습니다.
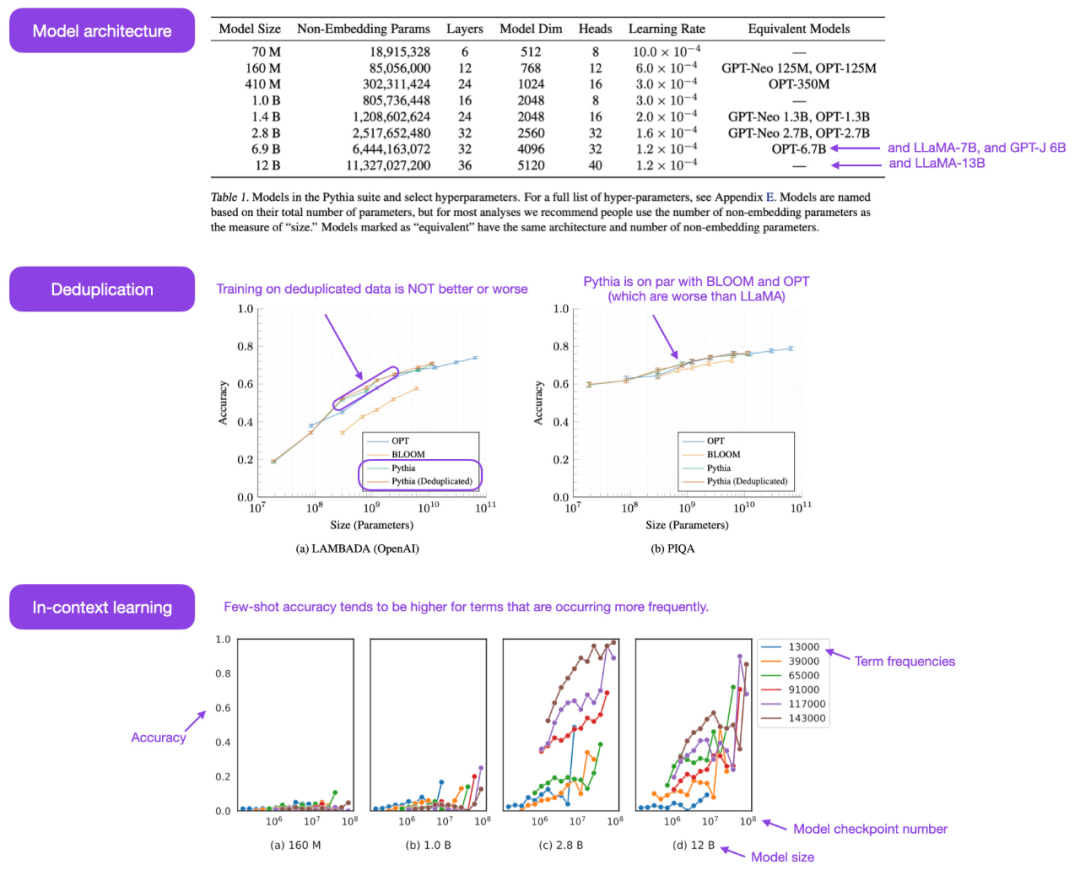
배치 크기를 두 배로 늘리면 수렴을 손상시키지 않고 훈련 시간을 절반으로 줄일 수 있습니다.
- 오픈 소스 데이터
- 지난 한 달은 LLM의 여러 오픈 소스 구현과 대규모 오픈 소스 데이터 세트의 등장으로 오픈 소스 AI에 특히 흥미로웠습니다. 이러한 데이터 세트에는 Databricks Dolly 15k, 명령 미세 조정을 위한 OpenAssistant Conversations(OASST1) 및 사전 훈련을 위한 RedPajama가 포함됩니다. 데이터 수집 및 정리가 실제 기계 학습 프로젝트의 90%를 차지하지만 이 작업을 즐기는 사람은 거의 없기 때문에 이러한 데이터 세트 노력은 특히 칭찬할 만합니다.
Databricks-Dolly-15 데이터 세트
Databricks-Dolly-15는 수천 명의 DataBricks 직원이 작성한 15,000개 이상의 명령 쌍이 포함된 LLM 미세 조정용 데이터 세트입니다(InstructGPT 교육 포함). ChatGPT와 같은 시스템과 유사 ).
OASST1 데이터 세트
OASST1 데이터 세트는 35개 언어로 작성된 161,443개의 메시지와 461,292개의 품질 평가를 포함하여 사람이 만들고 주석을 추가한 ChatGPT 도우미와 같은 대화 모음에서 사전 훈련된 LLM을 미세 조정하는 데 사용됩니다. . 이는 완전히 주석이 달린 10,000개가 넘는 대화 트리로 구성되어 있습니다.
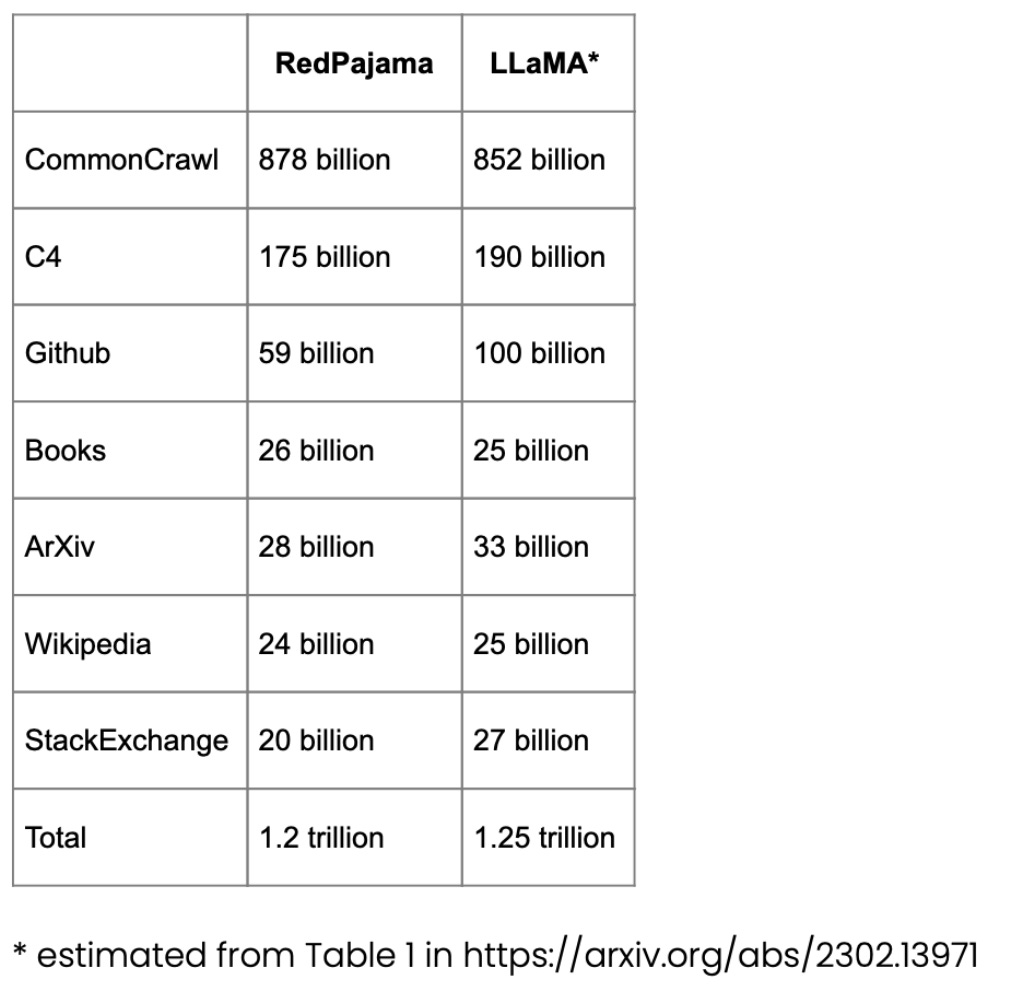
사전 훈련을 위한 RedPajama 데이터 세트

RedPajama는 Meta의 SOTA LLaMA 모델과 유사한 LLM 사전 교육을 위한 오픈 소스 데이터 세트입니다. 이 데이터 세트는 현재 폐쇄 소스 비즈니스 모델이거나 부분적으로만 오픈 소스인 가장 인기 있는 LLM에 대한 오픈 소스 경쟁자를 만드는 것을 목표로 합니다.
RedPajama의 대부분은 영어로 사이트를 필터링하는 CommonCrawl로 구성되어 있지만 Wikipedia 기사는 20개 언어를 다루고 있습니다.
LongForm Dataset
논문 "The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction"에서는 C4 및 Wikipedia와 같은 기존 말뭉치를 기반으로 수동으로 생성된 문서 모음을 소개합니다. 및 이러한 문서에 대한 지침을 제공하여 긴 텍스트 생성에 적합한 지침 조정 데이터세트를 생성합니다. T Paper 주소: https: //arxiv.org/abs/2304.08460
alPaca Libre Projects
Alpaca Libre 프로젝트는 MIT 라이선스 데모를 Alpaca 호환 형식으로 변환하여 Alpaca 프로젝트를 재현하는 것을 목표로 합니다.
오픈 소스 데이터 세트 확장
명령 미세 조정은 GPT-3과 같은 사전 훈련된 기본 모델에서 더욱 강력한 ChatGPT와 같은 대규모 언어 모델로 발전할 수 있는 핵심 방법입니다. Databricks-Dolly-15와 같은 오픈 소스 인간 생성 명령 데이터 세트가 이를 달성하는 데 도움이 됩니다. 하지만 어떻게 더 확장할 수 있을까요? 추가 데이터를 수집하지 않는 것이 가능한가요? 한 가지 접근 방식은 자체 반복에서 LLM을 부트스트랩하는 것입니다. Self-Instruct 방법은 5개월 전에 제안되었지만(오늘날 기준으로는 오래되었지만) 여전히 매우 흥미로운 방법입니다. 주석이 거의 필요하지 않은 방법인 Self-Instruct 덕분에 사전 훈련된 LLM을 지침에 맞게 정렬할 수 있다는 점을 강조할 가치가 있습니다.
어떻게 작동하나요? 간단히 말해서 다음 네 단계로 나눌 수 있습니다.
첫 번째는 수동으로 작성된 지침(이 경우 175개)과 샘플 지침이 포함된 시드 작업 풀입니다. 두 번째는 사용하는 것입니다. 작업 범주를 결정하기 위한 사전 훈련된 LLM(예: GPT-3) 작업 풀에 지침을 추가하기 전에.
- 실제로는 ROUGE 점수를 기반으로 한 작업이 더 효과적입니다. 예를 들어 Self-Instruct 미세 조정 LLM은 GPT-3 기본 LLM보다 성능이 뛰어나며 수동으로 작성된 대규모 LLM과 경쟁할 수 있습니다. 지시 세트. 동시에 자가 교육은 수동 지침에 따라 미세 조정된 LLM의 이점을 누릴 수도 있습니다.
- 물론, LLM 평가의 최적 기준은 인간 평가자에게 물어보는 것입니다. 인간의 평가를 기반으로 Self-Instruct는 기본 LLM뿐만 아니라 감독 방식으로 인간 교육 데이터 세트에 대해 훈련된 LLM(예: SuperNI, T0 Trainer)보다 성능이 뛰어납니다. 그러나 흥미롭게도 Self-Instruct는 인간 피드백을 통한 강화 학습(RLHF)으로 훈련된 방법보다 더 나은 성능을 발휘하지 못합니다.
인공적으로 생성된 훈련 데이터 세트 vs 합성 훈련 데이터 세트
인공적으로 생성된 명령 데이터 세트 또는 자체 명령 데이터 세트 중 어느 것이 더 유망합니까? Sebastian은 두 가지 모두에서 미래를 봅니다. 수동으로 생성된 명령 데이터 세트(예: 15k 명령의 databricks-dolly-15k)로 시작한 다음 자체 명령을 사용하여 확장하면 어떨까요? "확산 모델의 합성 데이터로 ImageNet 분류 개선" 논문에서는 실제 이미지 훈련 세트와 AI 생성 이미지를 결합하면 모델 성능을 향상시킬 수 있음을 보여줍니다. 이것이 텍스트 데이터에도 적용되는지 살펴보는 것은 흥미로울 것입니다.
논문 주소: https://arxiv.org/abs/2304.08466
최근 논문 "자기 개선을 통한 더 나은 언어 모델 코드"는 이러한 방향의 연구에 관한 것입니다. 연구원들은 사전 훈련된 LLM이 자체 생성 데이터를 사용하면 코드 생성 작업이 향상될 수 있음을 발견했습니다.
논문 주소: https://arxiv.org/abs/2304.01228
Less is more(Less is more)?
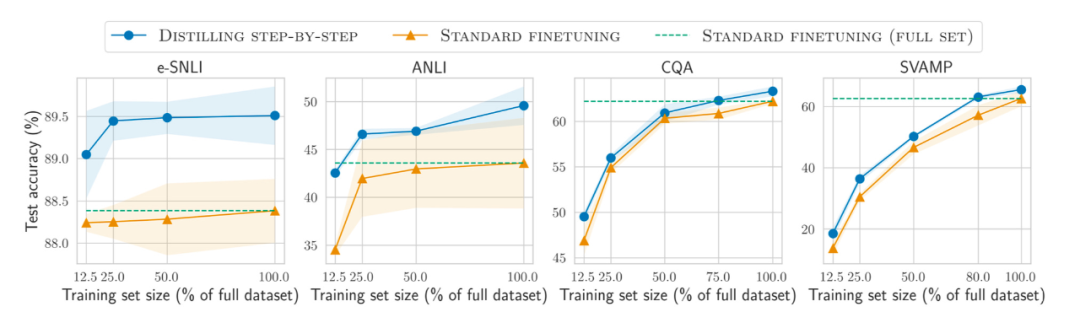
그리고 점점 더 많아지는 데이터에 더해 세트의 모델을 사전 훈련하고 미세 조정하는 방법, 더 작은 데이터 세트의 효율성을 향상시키는 방법은 무엇입니까? "단계별 증류! 더 적은 훈련 데이터와 더 작은 모델 크기로 더 큰 언어 모델 성능 향상"이라는 논문에서는 더 적은 훈련 데이터를 사용하지만 표준 미세 조정 성능을 초과하는 작업별 더 작은 모델을 관리하기 위해 증류 메커니즘을 사용할 것을 제안합니다.
논문 주소: https://arxiv.org/abs/2305.02301
오픈 소스 LLM 추적
오픈 소스 LLM의 수가 폭발적으로 늘어나고 있습니다. 한 손으로 , 이는 매우 좋은 추세이지만(유료 API를 통해 모델을 제어하는 것과 비교하면) 모든 것을 추적하는 것은 번거로울 수 있습니다. 다음 네 가지 리소스는 관계, 기본 데이터 세트 및 다양한 라이선스 정보를 포함하여 가장 관련성이 높은 모델에 대한 다양한 요약을 제공합니다.
첫 번째 리소스는 다음 표와 대화형 종속성 그래프(여기에는 표시되지 않음)를 제공하는 "생태계 그래프: 기초 모델의 사회적 발자국" 논문을 기반으로 한 생태계 그래프 웹사이트입니다.
이 생태계 다이어그램은 Sebastian이 지금까지 본 목록 중 가장 포괄적인 목록이지만 덜 인기 있는 LLM이 많이 포함되어 있기 때문에 다소 혼란스러울 수 있습니다. 해당 GitHub 리포지토리를 확인하면 최소 한 달 동안 업데이트된 것으로 표시됩니다. 새로운 모델을 추가할지 여부도 불분명합니다.
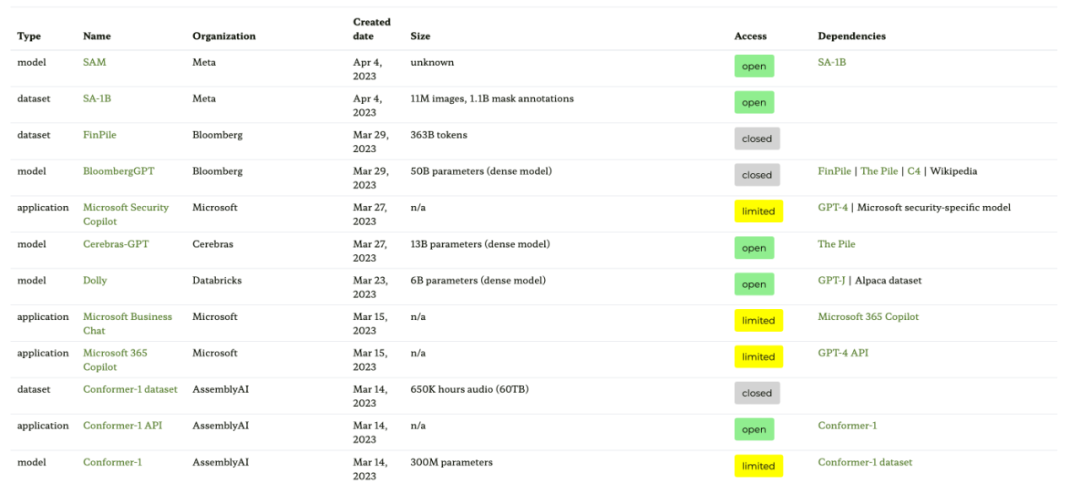
- 논문 주소: https://arxiv.org/abs/2303.15772
- 생태계 그래프 웹사이트 주소: https://crfm.stanford.edu/ecosystem-graphs / index.html?mode=table
두 번째 리소스는 최근 논문 Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond에서 아름답게 그려진 진화 트리입니다. 그들의 관계.
독자들은 매우 아름답고 명확한 시각적 LLM 진화 트리를 보았지만 약간의 의심도 가지고 있습니다. 바닥이 원래 변압기 아키텍처에서 시작되지 않는 이유는 명확하지 않습니다. 또한 오픈 소스 레이블은 그다지 정확하지 않습니다. 예를 들어 LLaMA는 오픈 소스로 나열되어 있지만 오픈 소스 라이선스에서는 가중치를 사용할 수 없습니다(추론 코드만 가능).
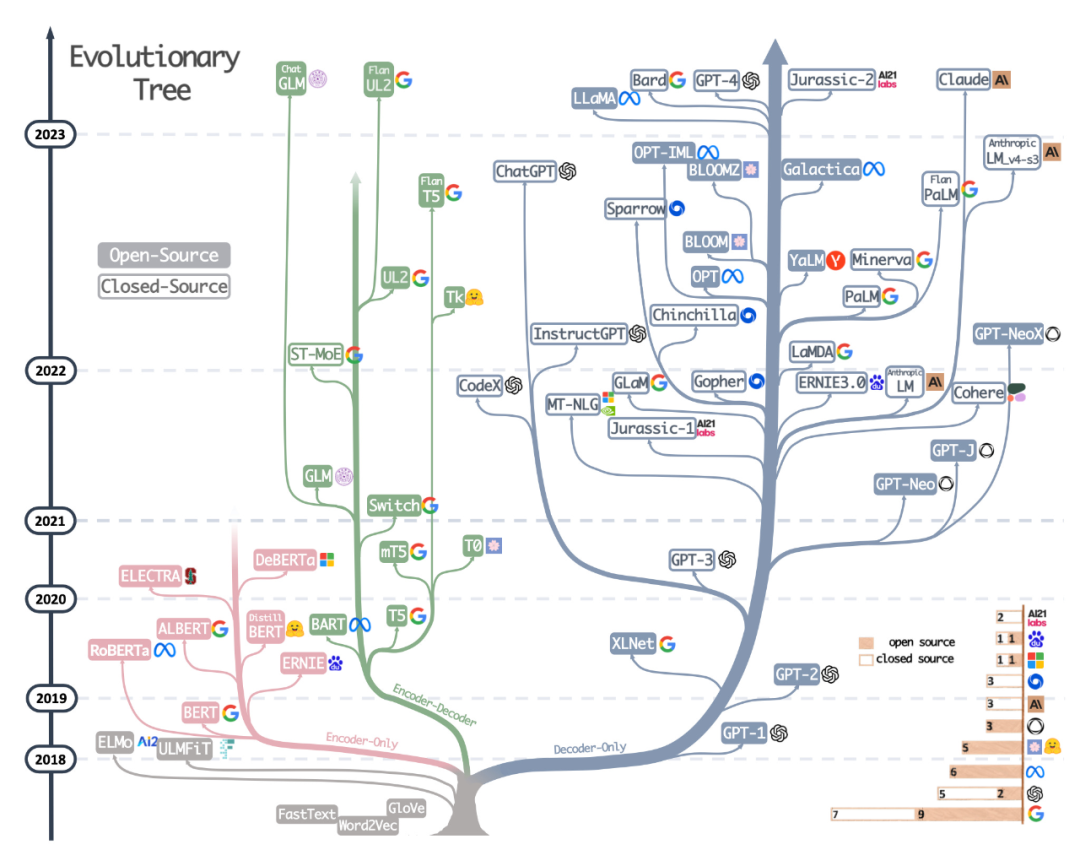
문서 주소: https://arxiv.org/abs/2304.13712
세 번째 리소스는 블로그 "The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs..."에서 Sebastian의 동료 Daniela Dapena가 그린 표입니다.
아래 표는 다른 자료에 비해 크기는 작지만, 모델 치수와 라이센스 정보를 담을 수 있다는 장점이 있습니다. 이 테이블은 모든 프로젝트에서 이러한 모델을 사용하려는 경우 매우 유용합니다.
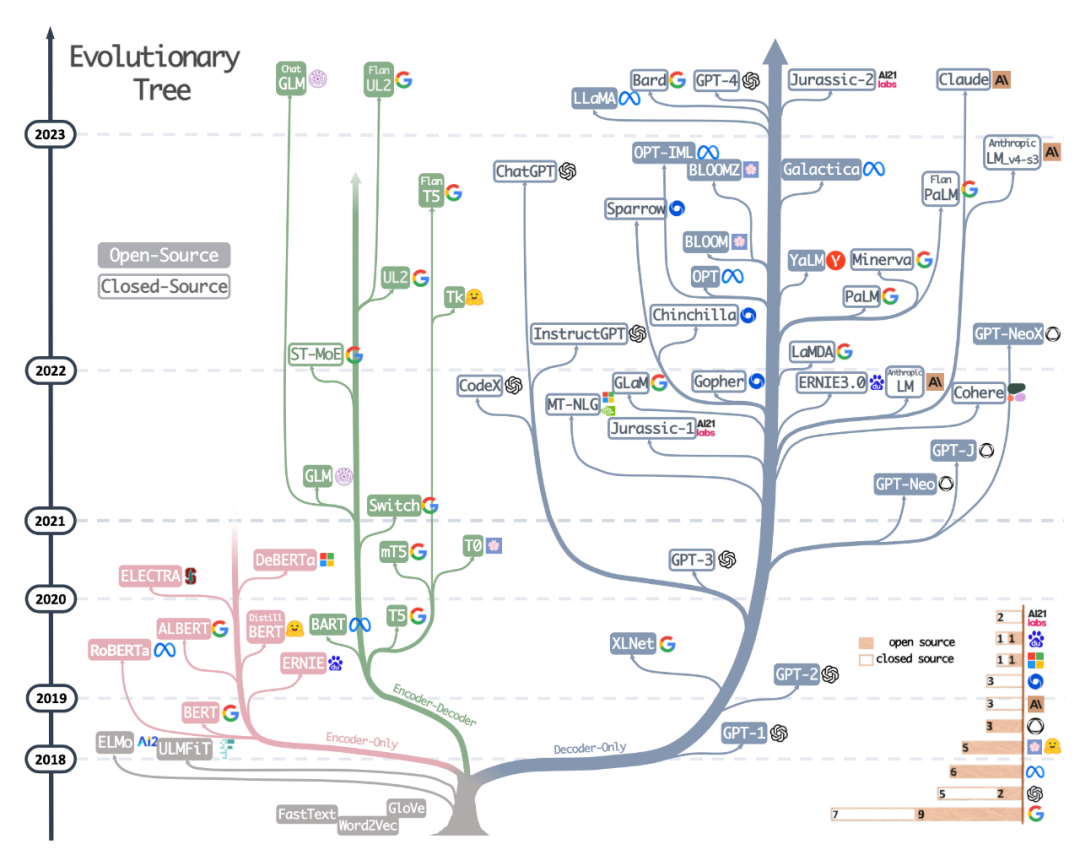
블로그 주소: https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of-언어-models-lit-llama-vs-gpt3.5-vs -bloom-vs/
네 번째 리소스는 미세 조정 방법 및 하드웨어 비용에 대한 추가 정보를 제공하는 LLaMA-Cult-and-More 개요 표입니다.
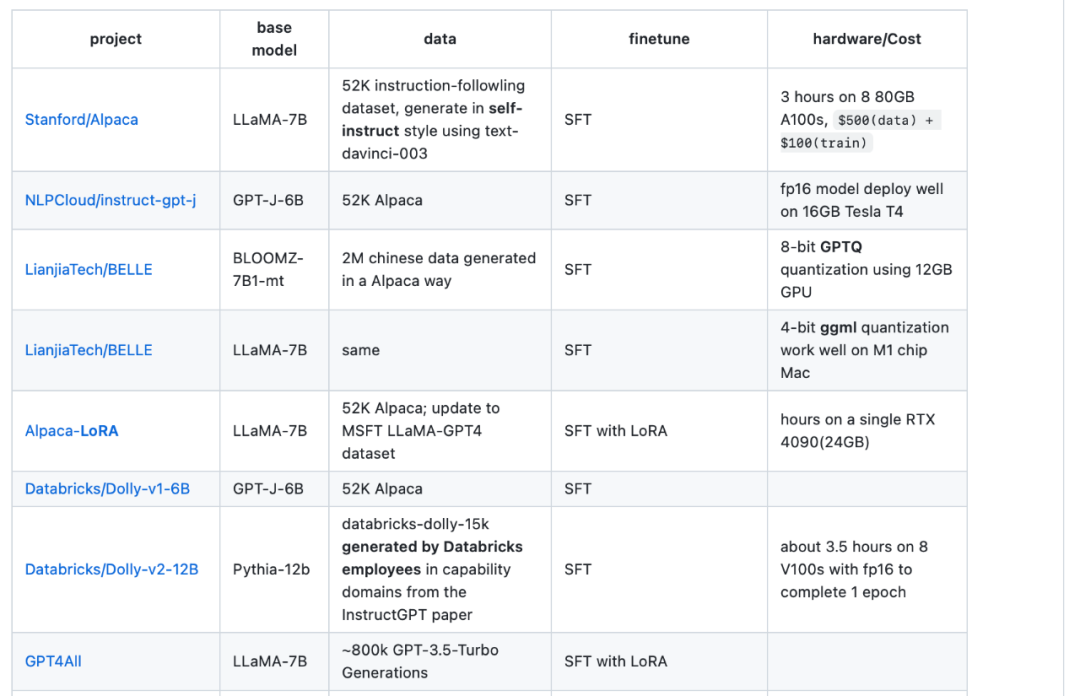
개요 테이블 주소: https://github.com/shm007g/LLaMA-Cult-and-More/blob/main/chart.md
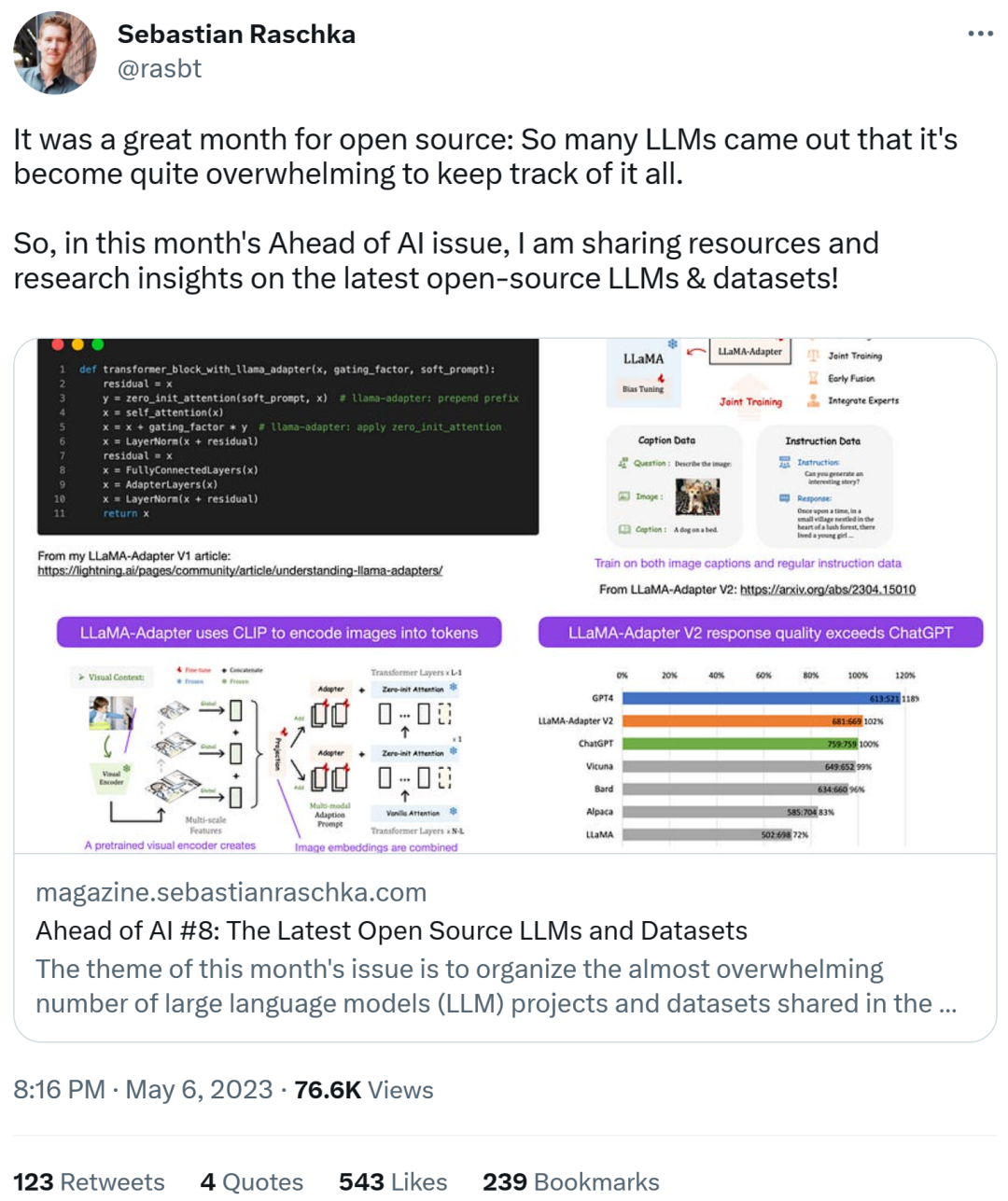
LLaMA-Adapter V2 사용 Fine-tuning multi-modal LLM
Sebastian은 이번 달에 더 많은 다중 모드 LLM 모델을 보게 될 것이라고 예측했습니다. 그래서 우리는 아직 발표되지 않은 "LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model" 논문에 대해 이야기해야 합니다. 오래전. 먼저 LLaMA-Adapter가 무엇인지 살펴보겠습니다. 이는 이전 변환기 블록을 수정하고 훈련을 안정화하기 위해 게이팅 메커니즘을 도입하는 매개변수 효율적인 LLM 미세 조정 기술입니다.
논문 주소: https://arxiv.org/abs/2304.15010
연구원들은 LLaMA-Adapter 방법을 사용하여 단 1시간 만에 52,000개의 명령 쌍을 달성할 수 있었습니다(A100 GPU 8개). -7B 매개변수 LLaMA 모델 조정. 새로 추가된 1.2M 매개변수(어댑터 레이어)만 미세 조정되었지만 7B LLaMA 모델은 여전히 동결된 상태입니다.
LLaMA-Adapter V2는 다중 양식, 즉 이미지 입력을 받을 수 있는 시각적 명령 모델을 구축하는 데 중점을 둡니다. 원래 V1은 텍스트 토큰과 이미지 토큰을 받을 수 있었지만 이미지는 완전히 탐색되지 않았습니다.
LLaMA-Adapter V1에서 V2까지 연구자들은 다음 세 가지 주요 기술을 통해 어댑터 방식을 개선했습니다.
- 초기 시각적 지식 융합: 각 적응 레이어에서 시각적 및 적응형 큐를 융합하는 대신 시각적 토큰을 첫 번째 변환기 블록의 단어 토큰과 연결합니다.
- 더 많은 매개변수 사용: 모든 정규화 레이어를 고정 해제하고 추가합니다. 변환기 블록의 각 선형 레이어에 대한 바이어스 단위 및 스케일링 계수
- 연속 매개변수를 사용한 공동 학습: 자막 데이터의 경우 시각적 투영만 학습됩니다. 계층은 적응 레이어(및 위에 새로 추가된 매개변수)만 학습됩니다. 데이터에 대한 지침이 따릅니다.
LLaMA V2(14M)는 LLaMA V1(1.2M)보다 더 많은 매개변수를 가지고 있지만 여전히 가볍기 때문에 65B LLaMA 전체 매개변수의 0.02%만을 차지합니다. 특히 인상적인 점은 65B LLaMA 모델의 14M 매개변수만 미세 조정함으로써 결과 LLaMA-Adapter V2가 ChatGPT(GPT-4 모델을 사용하여 평가할 때)와 동등한 성능을 발휘한다는 것입니다. LLaMA-Adapter V2는 또한 전체 미세 조정 방법을 사용하여 13B Vicuna 모델보다 성능이 뛰어납니다.
안타깝게도 LLaMA-Adapter V2 논문에는 V1 논문에 포함된 계산 성능 벤치마크가 생략되어 있지만 완전히 미세 조정된 방법보다 V2가 여전히 훨씬 빠르다고 가정할 수 있습니다.

기타 오픈 소스 LLM
대형 모델의 개발 속도가 너무 빨라서 모두 나열할 수 없습니다. 이번 달에 출시된 유명한 오픈 소스 LLM 및 챗봇으로는 Open-Assistant, Baize, StableVicuna, ColossalChat, 모자이크의 MPT 등이 있습니다. 또한 아래에는 특히 흥미로운 두 가지 다중 모드 LLM이 있습니다.
OpenFlamingo
OpenFlamingo는 Google DeepMind가 작년에 출시한 Flamingo 모델의 오픈 소스 복사본입니다. OpenFlamingo는 사람들이 텍스트와 이미지 입력을 인터리브할 수 있도록 LLM을 위한 다중 모드 이미지 추론 기능을 제공하는 것을 목표로 합니다.
MiniGPT-4
MiniGPT-4는 시각적 언어 기능을 갖춘 또 다른 오픈 소스 모델입니다. 이는 BLIP-27 고정된 시각적 인코더와 고정된 Vicuna LLM을 기반으로 합니다.
NeMo Guardrails
이러한 대규모 언어 모델이 등장하면서 많은 기업에서는 이를 배포하는 방법과 여부를 고민하고 있으며 보안 문제가 특히 두드러집니다. 아직 좋은 솔루션은 없지만 유망한 접근 방식이 하나 이상 더 있습니다. NVIDIA는 LLM 환각 문제를 해결하기 위한 툴킷을 오픈 소스로 제공했습니다.
간단히 말해서 이 방법의 작동 방식은 수동으로 관리해야 하는 하드 코딩된 프롬프트에 대한 데이터베이스 링크를 사용한다는 것입니다. 그런 다음 사용자가 프롬프트를 입력하면 해당 콘텐츠가 먼저 해당 데이터베이스의 가장 유사한 항목과 일치됩니다. 그런 다음 데이터베이스는 LLM에 전달되는 하드코딩된 프롬프트를 반환합니다. 따라서 하드코딩된 프롬프트를 주의 깊게 테스트하면 상호 작용이 허용된 주제 등에서 벗어나지 않는지 확인할 수 있습니다.
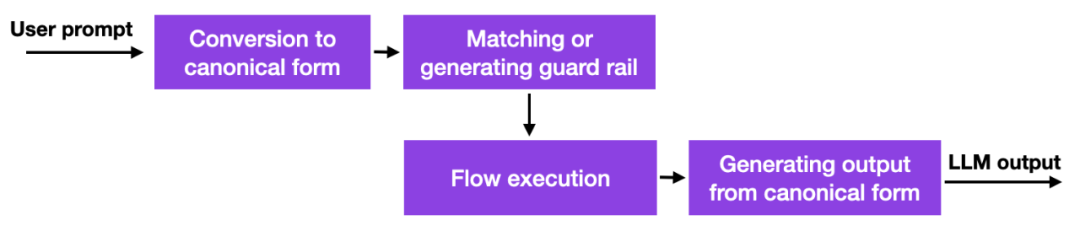
이는 LLM에 더 좋거나 새로운 기능을 제공하지 않고 사용자가 LLM과 상호 작용할 수 있는 범위를 제한하기 때문에 흥미롭지만 획기적인 접근 방식은 아닙니다. 그럼에도 불구하고 연구자들이 LLM에서 환각 문제와 부정적인 행동을 완화할 수 있는 대안을 찾을 때까지는 이것이 실행 가능한 접근 방식이 될 수 있습니다.
가드레일 접근 방식은 저자가 Ahead of AI의 이전 호에서 소개한 인기 있는 인간 피드백 강화 학습 훈련 패러다임과 같은 다른 정렬 기술과 결합될 수도 있습니다.
일관성 모델
LLM 이외의 흥미로운 모델에 대해 이야기하는 것은 좋은 시도입니다. OpenAI는 마침내 일관성 모델의 코드를 오픈소스화했습니다: https://github.com/openai/consistency_models.
일관성 모델은 확산 모델에 대한 실행 가능하고 효율적인 대안으로 간주됩니다. 일관성 모델 문서에서 자세한 정보를 얻을 수 있습니다.
위 내용은 대형 모델이 '오픈 소스 시즌'을 맞이하고 있으며 지난달 오픈 소스 LLM 및 데이터 세트를 보유하고 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!