
ChatGPT 프로그래밍 정확도가 13% 감소했습니다! UIUC 및 NTU의 새로운 벤치마크로 AI 코드가 실제 형태로 나타남

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-17 14:58:131637검색

ChatGPT로 코드를 작성하는 것은 많은 프로그래머에게 일상적인 작업이 되었습니다.
Δ"최소 3~5배 더 빠르다"
하지만 ChatGPT에서 생성된 많은 코드가 단지 "정확해 보인다"고 생각한 적이 있나요?
일리노이 대학교 어바나-샴페인 캠퍼스와 난징 대학교의 최신 연구에 따르면 다음과 같습니다.
ChatGPT 및 GPT-4에서 생성된 코드의 정확성은 이전에 평가된 것보다 최소 13% 낮습니다!

일부 네티즌들은 "SOTA"를 잠깐 달성하기 위해 모델을 평가하기 위해 문제가 있거나 제한된 벤치마크를 사용하는 ML 논문이 너무 많다고 한탄했습니다. 결과적으로 평가 방법을 바꾸면 원래의 모습이 드러납니다.

일부 네티즌들은 이는 또한 대형 모델에서 생성된 코드에 여전히 수동 감독이 필요하다는 점을 보여준다며 "AI 코드 작성의 전성기는 아직 도래하지 않았다"고 말했습니다.

그럼 논문에서는 어떤 새로운 평가 방법을 제안하는 걸까요?
AI 코드 테스트 질문을 더 어렵게 만듭니다
이 새로운 방법은 EvalPlus라고 하며 자동화된 코드 평가 프레임워크입니다.
구체적으로는 기존 평가 데이터 세트의 입력 다양성과 문제 설명 정확도를 향상하여 이러한 평가 벤치마크를 더욱 엄격하게 만들 것입니다.
한편에는 입력의 다양성이 있습니다. EvalPlus는 먼저 ChatGPT를 사용하여 표준 답변을 기반으로 일부 시드 입력 샘플을 생성합니다(ChatGPT의 프로그래밍 능력을 테스트해야 하지만 이를 사용하여 시드 입력을 생성하는 것이 일관성이 없는 것 같습니다)
그런 다음 EvalPlus를 사용하여 이러한 사항을 개선합니다. 입력을 시드하고 변경하는 것은 더 어렵고 복잡하며 까다롭습니다.
또 다른 측면은 문제 설명의 정확성입니다. EvalPlus는 코드 요구 사항에 대한 설명을 보다 정확하게 변경하여 입력 조건을 제한하는 동시에 자연어 문제 설명을 보완하여 모델 출력의 정확도 요구 사항을 향상시킵니다.
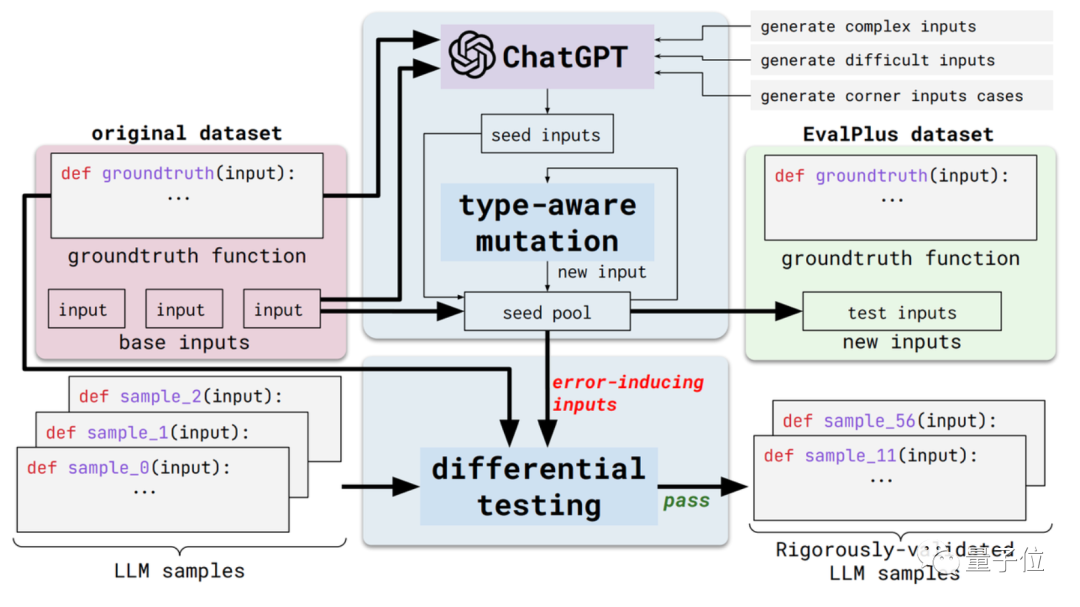
여기서 논문에서는 데모로 HUMANEVAL 데이터 세트를 선택합니다.
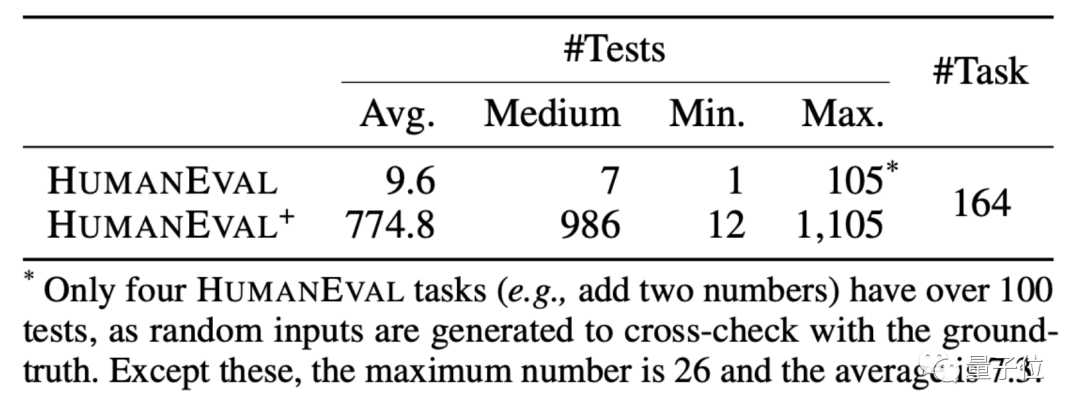
HUMANEVAL은 OpenAI와 Anthropic AI가 공동으로 제작한 코드 데이터 세트입니다. 여기에는 언어 이해, 알고리즘, 수학 및 소프트웨어 인터뷰를 포함한 여러 유형의 질문이 포함된 164개의 독창적인 프로그래밍 질문이 포함되어 있습니다.
EvalPlus는 이러한 데이터 세트의 입력 유형 및 기능 설명을 개선하여 프로그래밍 문제를 더 명확하게 보이게 하며 테스트에 사용되는 입력은 더 "까다롭거나" 어려워집니다.
합집합 프로그래밍 질문 중 하나를 예로 들면 AI는 두 데이터 목록에서 공통 요소를 찾고 이러한 요소를 정렬하는 코드를 작성해야 합니다.
EvalPlus는 이를 사용하여 ChatGPT로 작성된 코드의 정확성을 테스트합니다.
간단한 입력 테스트를 진행한 결과 ChatGPT가 정확한 답변을 출력할 수 있음을 확인했습니다. 하지만 입력을 변경하면 ChatGPT 버전의 코드에서 버그를 발견할 수 있습니다.

AI의 경우 테스트 문제가 더 어려운 것은 사실입니다.

이 방법을 기반으로 EvalPlus는 입력을 추가하는 동안 HUMANEVAL에서 문제가 있는 답변으로 일부 프로그래밍 질문을 수정했습니다.
이 "새로운 테스트 질문 세트"에서 대규모 언어 모델의 정확도는 실제로 얼마나 감소할까요?
LLM 코드 정확도는 평균 15% 감소합니다.
저자는 현재 인기 있는 코드 생성 AI 10개를 테스트했습니다.
GPT-4, ChatGPT, CODEGEN, VICUNA, SANTACODER, INCODER, GPT-J, GPT-NEO, PolyCoder, StableLM-α.
표에 따르면, 엄격한 테스트 후에 이 AI 그룹의 생성 정확도가 감소했습니다.
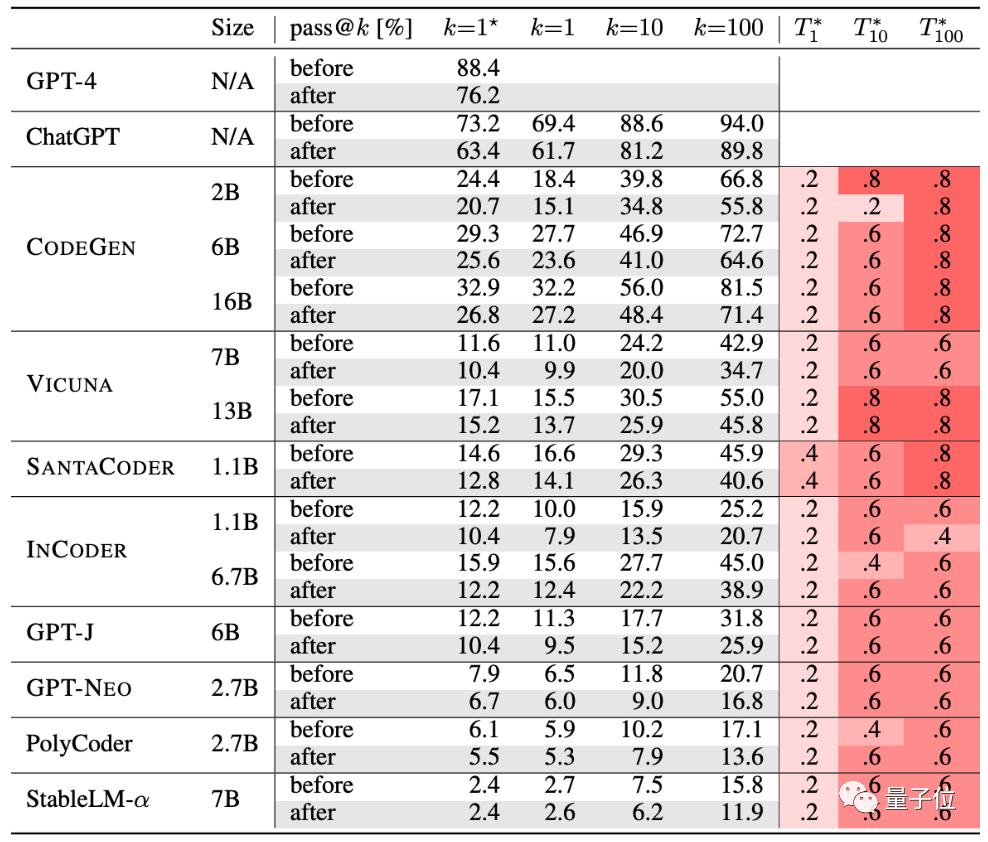
정확도는 여기에서 pass@k라는 메서드를 통해 평가됩니다. 여기서 k는 AI의 수입니다. 대형 모델이 문제를 생성할 수 있도록 하는 프로그램에서 n은 테스트에 사용되는 입력 수이고 c는 올바른 입력 수입니다.
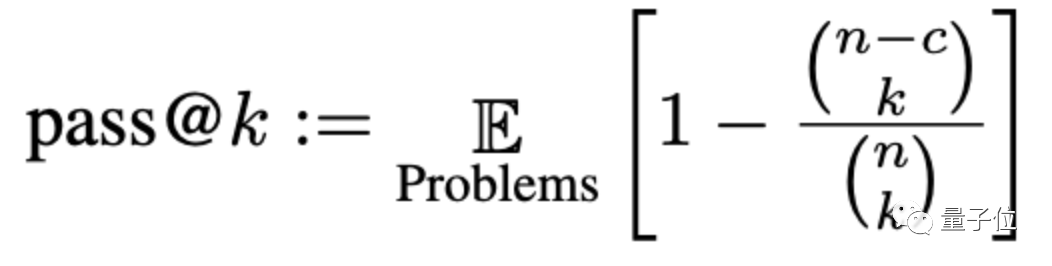
이 새로운 평가 기준 세트에 따르면 대형 모델의 평균 정확도는 이는 15% 감소했고, 더 널리 연구된 CODEGEN-16B는 18% 이상 감소했습니다.
ChatGPT 및 GPT-4 생성 코드의 성능도 최소 13% 감소했습니다.
그러나 일부 네티즌들은 대형 모델이 생성한 코드가 그다지 좋지 않다는 것은 '잘 알려진 사실'이며, 연구해야 할 것은 '왜 대형 모델이 작성한 코드를 사용할 수 없는가'라고 말했다.
위 내용은 ChatGPT 프로그래밍 정확도가 13% 감소했습니다! UIUC 및 NTU의 새로운 벤치마크로 AI 코드가 실제 형태로 나타남의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!