
Java의 힙과 스택이란 무엇입니까?

- PHPz앞으로
- 2023-05-16 21:32:271177검색
Java 프로그램 실행 방법
Java 프로그램은 JVM(Java Virtual Machine)에서 실행됩니다. JVM은 실행 시 Java 애플리케이션에 필요한 모든 리소스에 대한 관리자를 제공합니다. 즉, 개발자가 작성하거나 만든 애플리케이션은 JVM이 이러한 리소스를 제공할 수 없는 한 시스템 리소스(하드웨어든 소프트웨어든)를 직접 얻을 수 있는 기능이 없습니다. 따라서 Java에서 프로그램 실행 순서는 다음과 같습니다.

JVM 계층을 사용하면 Java 플랫폼이 독립적으로 실행될 수 있습니다. C/C++와 같은 다른 프로그래밍 언어는 JVM 계층과 유사한 것을 사용하지 않습니다. 이식 가능한 언어이기는 하지만 크로스 플랫폼 언어는 아닙니다. 아래 그림과 같습니다.

두 가지 형태 모두 장단점이 있으며 Java에는 이미 자체 생태계가 있습니다. 동시에 C/C++와 같은 프로그래밍 언어는 시스템 리소스에 직접 액세스할 수 있으므로 코어 유닛의 사용을 최적화하는 데 더 도움이 되므로 매우 빠르고 효율적인 프로그램이 생성됩니다. 그러나 둘 다 소프트웨어 개발 세계에서 용도가 있습니다.
모든 프로그래밍 언어는 컴파일 및 실행 과정에서 많은 유사점을 가지고 있습니다. 가장 중요한 점은 메모리 관리입니다. 어떤 언어를 사용하든 메모리 관리는 프로그램의 전반적인 효율성에 중요한 영향을 미칩니다. 메모리 자원을 잘 관리해야만 애플리케이션 성능을 잘 관리할 수 있기 때문입니다.
Java에서 메모리 실행
기본 플랫폼은 애플리케이션에 필요한 메모리를 제공하는데, 이는 애플리케이션 간에 일반적인 상황이므로 각 애플리케이션이 최적으로 작동할 수 있습니다. Java에서 운영 체제는 JVM에서 제공하는 메모리 리소스를 사용하려면 인증이 필요합니다. Java에서 JVM 메모리는 메소드 영역, 힙, 스택, PC 레지스터 및 로컬 메소드 스택을 포함하여 5개의 주요 부분으로 나뉩니다.
이 글은 주로 힙과 스택에 초점을 맞췄습니다. 메모리는 빈 종이가 아닙니다. 프로그래머는 마음대로 데이터를 기록할 수 없습니다. 사용하기 전에 구조화되어야 합니다. 스택(Stack)과 힙(Heap)은 메모리를 사용할 때 따르는 데이터 구조로, 프로그램이 실행되는 동안 저장된 데이터는 프로그램의 목적에 따라 다양한 용도로 사용됩니다.
JVM은 프로그램 실행 중에 사용되는 런타임 데이터 영역을 결정합니다. 일부 데이터 영역은 JVM에 종속적입니다. 즉, JVM이 시작될 때 생성되고 JVM 라이프사이클 전체에서 지속됩니다. 그러나 각 스레드는 다른 데이터 영역을 생성하고 파괴합니다. JVM은 동시에 여러 실행 스레드를 실행할 수 있습니다. 즉, 각 스레드에는 실행 중인 현재 명령의 위치를 유지하기 위한 자체 PC(프로그램 카운터, 프로그램 카운터)와 정적 메모리 할당을 저장하기 위한 스택 프레임이 있습니다.
Stack
스택은 개발자가 스택 상단에서만 데이터를 검색할 수 있는 방식으로 요소를 저장하는 메모리 구조입니다. 흔히 FILO 또는 LIFO라고 합니다. 각 스레드에는 정적 메모리 할당과 관련된 변수를 저장하는 전용 JVM 스택이 있습니다. 실제로 우리 코드에서 선언하고 사용하는 메소드에는 특정 기본 변수가 스택 영역에 저장됩니다. 또한 실제로 힙 메모리에 저장된 객체에 대한 참조도 스택 영역에 저장됩니다. 따라서 로컬로 할당된 메모리는 스택에 저장됩니다.
스택 메모리의 기본 크기는 JVM 매개변수 -Xss를 사용하여 변경할 수 있습니다. 때로는 너무 많은 변수가 할당되거나 메서드가 자신을 재귀적으로 호출하는 경우 스택이 오버플로될 수 있습니다. 모든 Java 프로그래머에게 알려진 일반적인 오류는 스택 메모리가 부족할 때 나타나는 Java.lang.stackoverflowerror입니다. Java의 각 메서드 호출은 스택에 메모리 일부를 할당합니다. 따라서 잘못 설계된 재귀 메서드 호출은 쉽게 모든 스택 메모리를 차지하여 스택 메모리 오버플로 오류를 일으킬 수 있습니다. Java.lang.stackoverflowerror,当栈内存不足时提示该错误。Java中的每个方法调用都会在栈中分配一块内存,因此,设计糟糕的递归方法调用很容易占用所有栈内存,导致栈内存溢出错误。
堆
堆是JVM一启动就创建的内存区域,它会一直存在,直到JVM被销毁。与栈不同的是,栈是单个线程的属性(因为每个线程都有自己的栈),堆实际上是由JVM本身管理的全局内存,此内存在运行时用于为对象分配内存。因此,对象的实例化可以是用户定义的类、JDK或其他库类。简而言之,使用new关键字创建的任何对象都存储在堆内存中。堆内存中的对象可被JVM运行的所有线程访问。访问管理非常复杂,使用了非常复杂的算法,这就是JVM垃圾收集器发挥作用的地方。
堆的默认大小可以使用JVM参数-Xms和-Xmx来更改。随着对象的创建和销毁,堆的大小也会增加或减少,如果达到最大内存限制后并尝试进一步分配内存,则抛出java.lang.OutOfMemoryError
new 키워드를 사용하여 생성된 모든 개체는 힙 메모리에 저장됩니다. 힙 메모리의 객체는 JVM을 실행하는 모든 스레드에서 액세스할 수 있습니다. 액세스 관리는 매우 복잡하고 매우 복잡한 알고리즘을 사용하며, 여기서 JVM 가비지 수집기가 작동합니다. 🎜🎜힙의 기본 크기는 JVM 매개변수 -Xms 및 -Xmx를 사용하여 변경할 수 있습니다. 객체가 생성되고 소멸됨에 따라 힙 크기가 증가하거나 감소합니다. 최대 메모리 한도에 도달하여 추가로 메모리 할당을 시도하면 java.lang.OutOfMemoryError가 발생합니다. 🎜힙
Java.lang.String 클래스의 String Pool(StringPool)은 Java에서 가장 많이 사용되는 클래스이므로 효율성에 특별한 주의를 기울여야 합니다. 기본 데이터 형식에 비해 문자열의 작업 효율성은 항상 매우 느립니다. 따라서 이러한 목적을 달성하려면 문자열 개체 작업의 효율성과 편의성을 기본 데이터 형식과 유사하게 만드는 방법을 사용해야 합니다. heap JVM에는 특수 메모리 영역(StringPool)이 할당되고 생성된 모든 문자열 개체는 JVM에 의해 StringPool에 저장됩니다. 이는 힙에 생성된 다른 개체에 비해 성능을 향상시킵니다. Java.lang.String类是Java中使用最多的类,因此,应该特别注意它的效率问题。与基本数据类型相比,字符串的操作效率总是很慢,所以,必须采用某种方式使得字符串对象操作的效率和便利性方面类似或者接近于基本数据类型,为了达到这个目的就在堆中分配了一块特殊内存区域(StringPool),创建的任何字符串对象都由JVM存储在StringPool中。与堆中创建的其他对象相比,这提高了性能。
从代码示例说明堆和栈
为了更好地说明在Java中堆和栈内存的使用,让我们写一个简单的程序,并决定哪个分配分配到哪个内存——堆或栈:
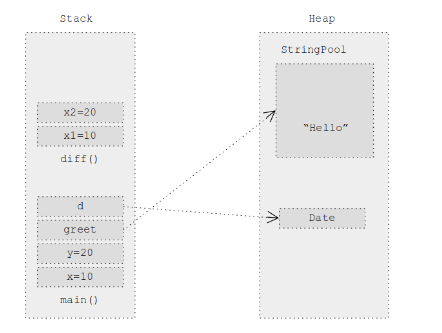
public class HeapAndStackTest {
public static void main(String[] args) {
int x=10;
int y=20;
String greet = "Hello";
Date d = new Date();
diff(x, y);
}
public static int diff(int x1, int x2) {
return x2-x1;
}
}这段代码运行方式如下:
程序启动,JVM将Java运行时环境(JRE)类加载到堆中。
在遇到
main()方法时,会创建一个栈帧。局部变量
x和y存储在栈中。字符串
greet分配在堆的StringPool区域中。-
Date对象分配在堆区,而它的引用d코드 예제에서 설명하는 힙과 스택
Java에서 힙과 스택 메모리의 사용을 더 잘 설명하기 위해 간단한 프로그램을 작성하고 어떤 할당이 어떤 메모리에 할당되는지 결정해 보겠습니다—&mdash ;힙 또는 스택 : rrreee
-
 프로그램이 시작되고 JVM은 JRE(Java Runtime Environment) 클래스를 힙에 로드합니다. 🎜
프로그램이 시작되고 JVM은 JRE(Java Runtime Environment) 클래스를 힙에 로드합니다. 🎜 - 🎜
main()메소드를 만나면 스택 프레임이 생성됩니다. 🎜🎜 - 🎜지역 변수
x와y는 스택에 저장됩니다. 🎜🎜 - 🎜
greet문자열은 힙의 StringPool 영역에 할당됩니다. 🎜🎜 - 🎜
Date객체는 힙 영역에 할당되고 해당 참조d는 스택에 저장됩니다. 🎜🎜🎜🎜🎜🎜
 프로그램이 시작되고 JVM은 JRE(Java Runtime Environment) 클래스를 힙에 로드합니다. 🎜
프로그램이 시작되고 JVM은 JRE(Java Runtime Environment) 클래스를 힙에 로드합니다. 🎜위 내용은 Java의 힙과 스택이란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!