
Python 이미지를 저장하고 액세스하는 세 가지 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-16 21:08:301793검색
Foreword
ImageNet은 객체 분류, 감지, 분할과 같은 작업을 위한 모델을 훈련하는 데 사용되는 잘 알려진 공개 이미지 데이터베이스입니다. 여기에는 1,400만 개가 넘는 이미지가 포함되어 있습니다.
예를 들어 Python에서 이미지 데이터를 처리할 때 컨볼루션 신경망(CNN이라고도 함)과 같은 알고리즘을 적용하면 수많은 이미지 데이터 세트를 처리할 수 있으며 여기서 가장 간단한 방법으로 데이터를 저장하고 읽는 방법을 배워야 합니다.
이미지 데이터 처리, 파일을 읽고 쓰는 데 걸리는 시간, 디스크 메모리 사용량을 비교하는 정량적 방법이 있어야 합니다.
다양한 방법을 사용하여 이미지 저장 및 성능 최적화 문제를 처리하고 해결하세요.
데이터 준비
가지고 놀 수 있는 데이터세트
우리에게 친숙한 이미지 데이터세트인 CIFAR-10은 개, 고양이, 비행기와 같은 다양한 개체 범주에 속하는 60,000개의 32x32 픽셀 컬러 이미지로 구성됩니다. CIFAR은 비교적 큰 데이터세트는 아니지만 전체 TinyImages 데이터세트를 사용하려면 약 400GB의 여유 디스크 공간이 필요합니다.
기사 내 코드에서 사용한 데이터셋 다운로드 주소는 CIFAR-10 데이터셋입니다.
이 데이터는 cPickle을 사용하여 직렬화되어 일괄 저장됩니다. 피클 모듈은 추가 코드나 변환 없이 Python의 모든 객체를 직렬화할 수 있습니다. 그러나 대량의 데이터를 처리하면 평가할 수 없는 보안 위험이 발생할 수 있습니다.
이미지는 NumPy 배열에 로드됩니다.
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")이미지 저장을 위한 설정
이미지 처리를 위해 타사 라이브러리 Pillow를 설치합니다.
pip install Pillow
LMDB
"Lightning 메모리 매핑 데이터베이스"(LMDB)는 속도와 메모리 매핑 파일 사용으로 인해 "Lightning 데이터베이스"라고도 알려져 있습니다. 관계형 데이터베이스가 아닌 키-값 저장소입니다.
이미지 처리를 위해 타사 라이브러리 lmdb를 설치하세요.
pip install lmdb
HDF5
HDF5는 HDF4 또는 HDF5라는 파일 형식인 Hierarchical Data Format을 나타냅니다. 이 휴대 가능하고 컴팩트한 과학 데이터 형식은 국립 슈퍼컴퓨팅 응용 센터에서 제공됩니다.
이미지 처리를 위해 타사 라이브러리 h6py를 설치하세요.
pip install h6py
단일 이미지 저장
데이터 읽기 작업을 수행하는 3가지 방법
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")동시에 로드된 데이터는 생성되어 폴더에 별도로 저장할 수 있습니다.
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
디스크에 저장
필로우를 사용하여 입력을 완료하는 것은 단일입니다. image image , NumPy 배열로 메모리에 저장되고 고유한 이미지 ID image_id로 이름이 지정됩니다.
디스크에 저장된 단일 이미지
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])LMDB에 저장
LMDB는 각 항목이 바이트 배열로 저장되는 키 값 쌍 저장 시스템입니다. 키는 각 이미지의 고유 식별자가 되고 값은 이미지가 됩니다. 그 자체.
키와 값 모두 문자열이어야 합니다. 일반적인 사용법은 값을 문자열로 직렬화한 다음 다시 읽을 때 역직렬화하는 것입니다.
재구성에 사용되는 이미지 크기. 일부 데이터 세트에는 다양한 크기의 이미지가 포함될 수 있으며 이 방법이 사용됩니다.
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)LMDB에 저장된 단일 이미지
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()Storing HDF5
하나의 HDF5 파일에는 여러 데이터세트가 포함될 수 있습니다. 두 개의 데이터 세트(이미지용 하나, 메타데이터용 하나)를 생성할 수 있습니다.
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()저장소 비교
단일 이미지를 저장하는 세 가지 기능을 모두 사전에 넣어보세요.
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)첫 번째 이미지를 CIFAR에 저장하고 해당 태그를 세 가지 방법으로 저장하세요.
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")비교를 살펴보겠습니다.
| 저장 방법 | 저장 시간 | 메모리 사용 |
|---|---|---|
| Disk | 2.1ms | 8K |
| LMDB | 1.7ms | 32K |
| HDF5 | 8.1ms | 8K |
여러 이미지 저장
단일 이미지 저장 방식과 유사하게, 여러 이미지 데이터를 저장하도록 코드를 수정합니다.
다중 이미지 조정 코드
여러 이미지를 .png 파일로 저장하는 것은 store_single_method() 메서드를 여러 번 호출하는 것으로 볼 수 있습니다. 각 이미지가 다른 데이터베이스 파일에 존재하기 때문에 LMDB 또는 HDF5에서는 이 접근 방식이 불가능합니다.
이미지 세트를 디스크에 저장
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label])이미지 세트를 LMDB에 저장
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()이미지 세트를 HDF5에 저장
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()데이터 세트 비교 준비
테스트용으로 100,000개의 이미지 사용
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
비교를 위한 계산 생성
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
print(f"Method: {method}, Time usage: {t}")PLOT 여러 데이터 세트와 일치하는 범례가 포함된 단일 플롯 표시
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
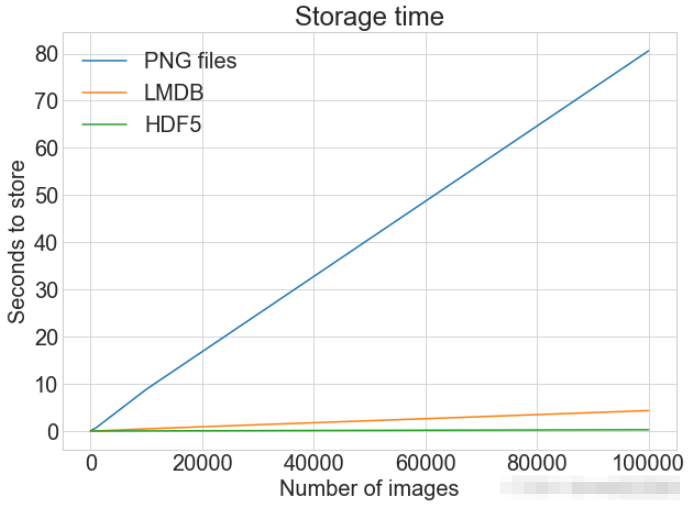
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
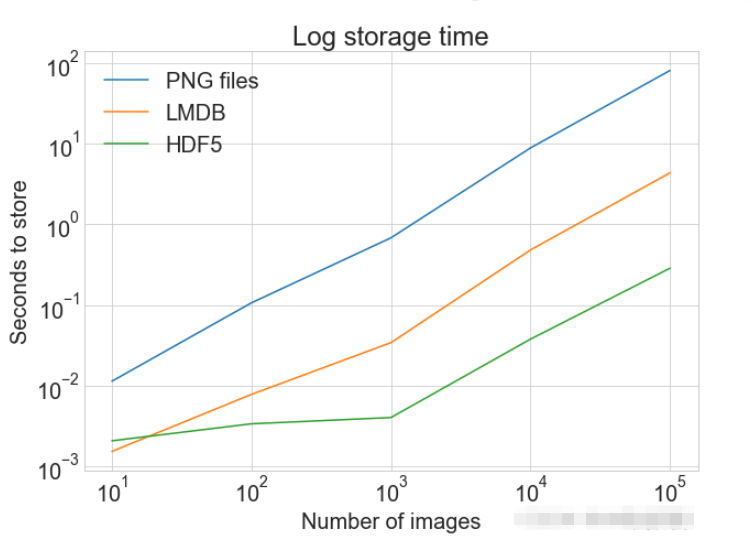
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)
단일 이미지 읽기
디스크에서 읽기
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, labelLMDB에서 읽기
def read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, labelHDF5에서 읽기
def read_single_hdf5(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, label 읽는 방법 비교
from timeit import timeit
read_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_single_funcs[method](0)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
read_single_timings[method] = t
print(f"读取方法: {method}, 使用耗时: {t}")| 저장 방법 | 저장 시간 |
|---|---|
| Disk | 1.7ms |
| LMDB | 4.4ms |
| HDF5 | 2.3ms |
多个图像的读取
可以将多个图像保存为.png文件,这等价于多次调用 read_single_method()。这并不适用于 LMDB 或 HDF5,因为每个图像都储存在不同的数据库文件中。
多图像调整代码
从磁盘中读取多个都图像
def read_many_disk(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 循环遍历所有ID,一张一张地读取每张图片
for image_id in range(num_images):
images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for row in reader:
labels.append(int(row[0]))
return images, labels从LMDB中读取多个都图像
def read_many_lmdb(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 在一个事务中读取,也可以拆分成多个事务分别读取
for image_id in range(num_images):
data = txn.get(f"{image_id:08}".encode("ascii"))
# CIFAR_Image 对象,作为值存储
cifar_image = pickle.loads(data)
# 检索相关位
images.append(cifar_image.get_image())
labels.append(cifar_image.label)
env.close()
return images, labels从HDF5中读取多个都图像
def read_many_hdf5(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "r+")
images = np.array(file["/images"]).astype("uint8")
labels = np.array(file["/meta"]).astype("uint8")
return images, labels
_read_many_funcs = dict(
disk=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)准备数据集对比
创建一个计算方式进行对比
from timeit import timeit
read_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_many_funcs[method](num_images)",
setup="num_images=cutoff",
number=1,
globals=globals(),
)
read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"读取方法: {method}, No. images: {cutoff}, 耗时: {t}")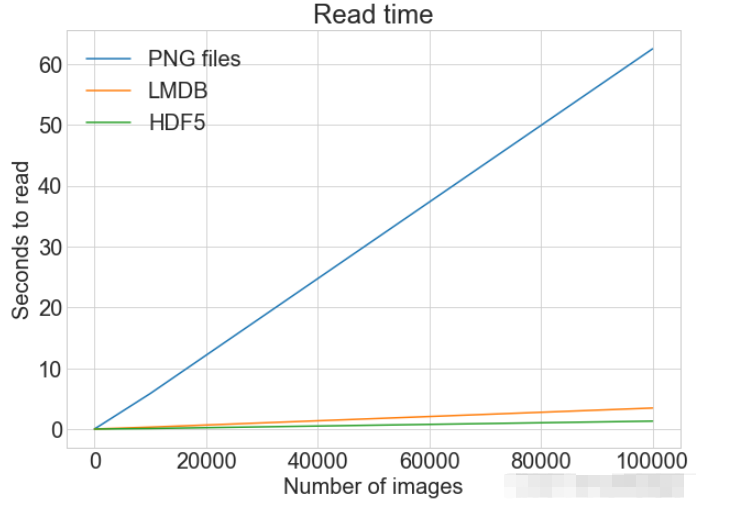
读写操作综合比较
数据对比
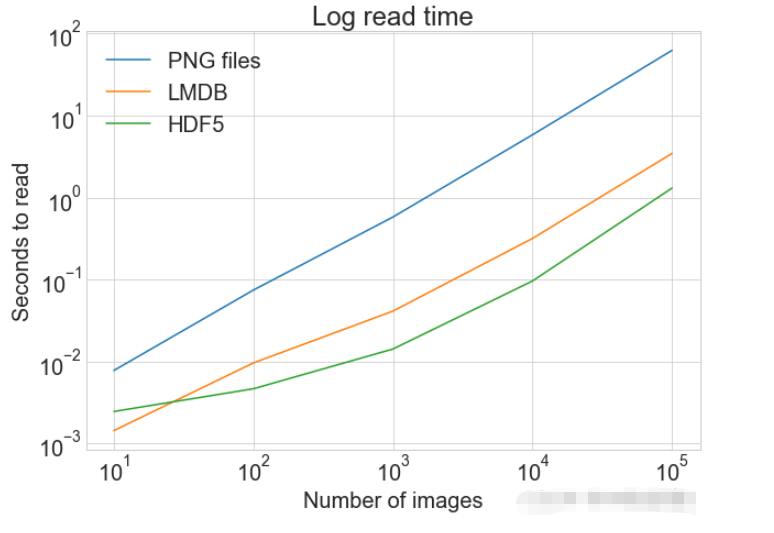
同一张图表上查看读取和写入时间
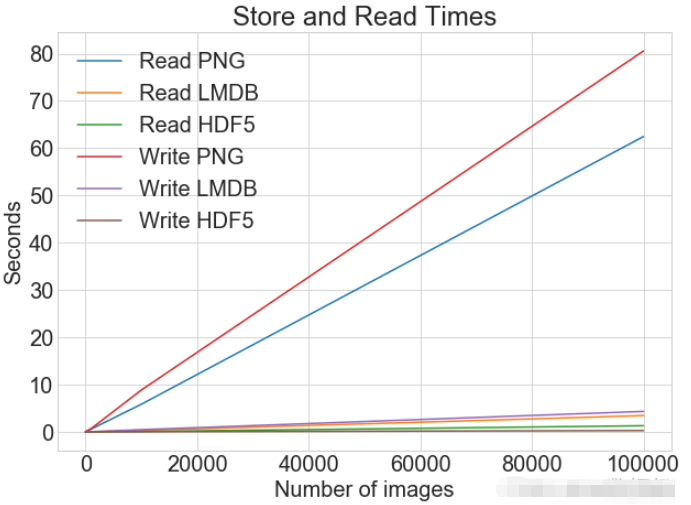
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[
"Read PNG",
"Read LMDB",
"Read HDF5",
"Write PNG",
"Write LMDB",
"Write HDF5",
],
"Number of images",
"Seconds",
"Log Store and Read Times",
log=False,
)
各种存储方式使用磁盘空间
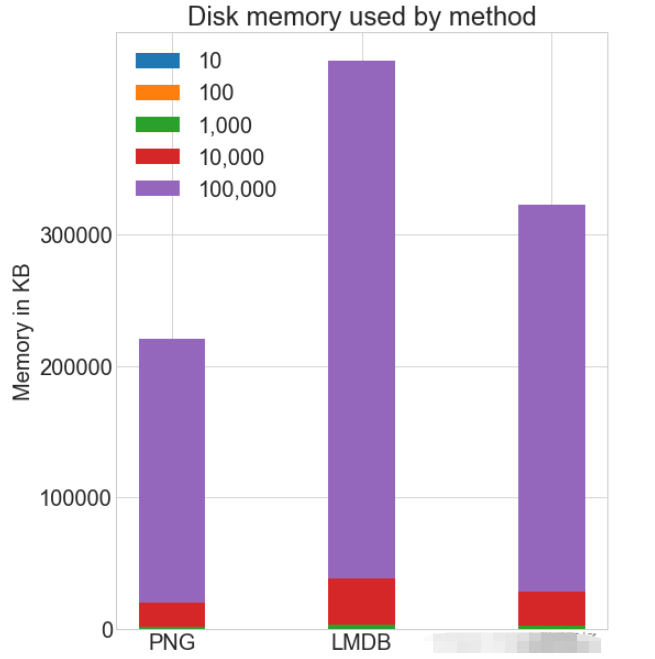
虽然 HDF5 和 LMDB 都占用更多的磁盘空间。需要注意的是 LMDB 和 HDF5 磁盘的使用和性能在很大程度上取决于各种因素,包括操作系统,更重要的是存储的数据大小。
并行操作
通常对于大的数据集,可以通过并行化来加速操作。 也就是我们经常说的并发处理。
作为.png 文件存储到磁盘实际上允许完全并发。可通过使用不同的图像名称,实现从多个线程读取多个图像,或一次性写入多个文件。
如果将所有 CIFAR 分成十组,那么可以为一组中的每个读取设置十个进程,并且相应的处理时间可以减少到原来的10%左右。
위 내용은 Python 이미지를 저장하고 액세스하는 세 가지 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!