
Google 내부 문서 유출: 오픈 소스 대형 모델은 너무 무서워서 OpenAI도 참을 수 없습니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-16 19:53:361569검색
오늘 구글이 "우리에겐 해자가 없고 OpenAI도 마찬가지다"라는 문서를 유출했다는 기사를 봤는데, 오픈소스 AI에 대한 특정 구글 직원(구글이 아닌 회사)의 견해가 아주 흥미롭습니다. , 일반적인 의미는 다음과 같습니다.
ChatGPT가 인기를 얻은 후 모든 주요 제조업체가 LLM으로 모여들고 미친 듯이 투자하고 있습니다.
구글도 재기를 바라며 열심히 노력하고 있지만, 제3자가 조용히 이 큰 케이크를 먹고 있기 때문에 누구도 이 군비 경쟁에서 이길 수 없습니다.
이 제3자는 대규모 오픈 소스 모델입니다.
오픈 소스 대형 모델에서는 이미 이 작업을 수행했습니다.
1. Pixel 6에서 초당 5개의 토큰 속도로 기본 모델을 실행합니다.
2. 하룻밤 만에 PC에서 개인화된 AI를 미세 조정할 수 있습니다.
OpenAI와 Google의 모델은 품질상의 이점이 있지만 그 격차는 놀라운 속도로 줄어들고 있습니다.
오픈 소스 모델 더 빠르고, 사용자 정의가 가능하며, 더 비공개적이고 더 강력합니다.
오픈소스 대형 모델은 $100와 130억 매개변수로 작업을 수행하고 몇 주 안에 완료하는 반면 Google은 몇 달 안에 $1000만 달러와 5400억 매개변수로 어려움을 겪습니다.
무료이고 제한되지 않은 대안이 품질 면에서 폐쇄형 모델과 비슷할 때 사람들은 확실히 폐쇄형 모델을 버릴 것입니다.
이 모든 것은 Facebook이 LLaMA를 오픈 소스로 공개하면서 시작되었습니다. 오픈 소스 커뮤니티는 지침, 대화 조정 또는 RLHF가 없었지만 즉시 이 기능의 중요성을 깨달았습니다.
다음 혁신은 며칠 단위로 측정해도 정말 미친 짓입니다.
2-24: Facebook은 LLaMA를 출시합니다. 현재는 연구 기관, 정부 기관에만 사용이 허가되어 있습니다.
3-03: LLaMA가 다음에서 유출됩니다. 인터넷은 비록 상업적인 이용은 허용되지 않았지만 갑자기 누구나 플레이할 수 있게 되었습니다.
3-12: Raspberry Pi에서 LLaMA를 실행하는 것은 매우 느리고 비실용적입니다.
3-13: Stanford는 LLaMA에 대한 명령 튜닝을 추가한 Alpaca를 출시했습니다. 더욱 "무서운" 점은 Stanford의 Eric J. Wang이 RTX를 사용한다는 것입니다. 4090 그래픽 카드를 사용하는 경우 Alpaca와 동등한 모델을 훈련하는 데 단 5시간이 걸렸으며, 이러한 모델의 컴퓨팅 성능 요구 사항을 소비자 수준으로 줄였습니다.
3-18: 5일 후 Georgi Gerganov는 4비트 양자화 기술을 사용하여 최초의 "GPUless" 솔루션인 MacBook CPU에서 LLaMA를 실행합니다.
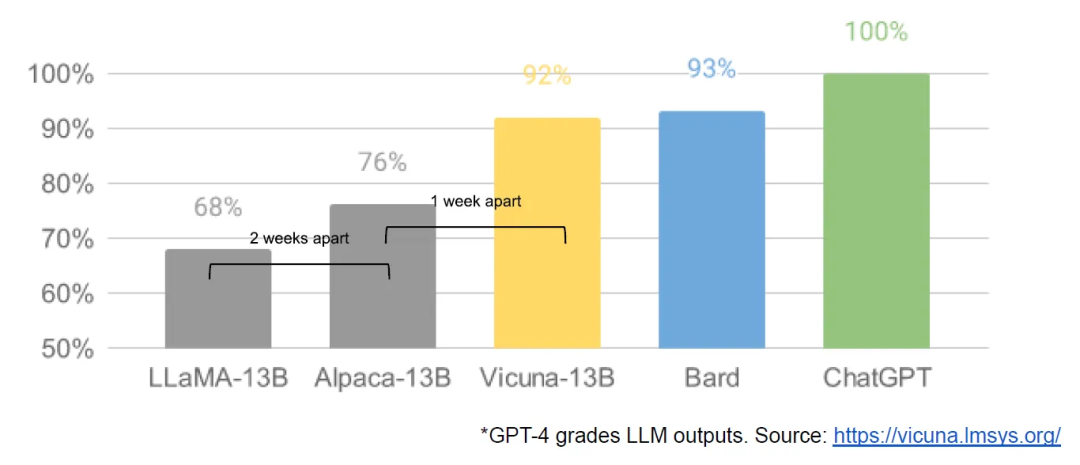
3-19: 단 하루 후, 버클리 캘리포니아 대학교, CMU, 스탠포드 대학교, 샌디에이고 캘리포니아 대학교의 연구원들이 공동으로 Vicuna를 출시했습니다. Vicuna는 90% 이상의 품질을 달성했다고 주장합니다. OpenAI ChatGPT와 Google Bard, 그리고 동시에 LLaMA, Stanford Alpaca 등 다른 모델보다 90% 이상의 품질을 달성했습니다.
3-25: Nomic은 모델이자 생태계인 GPT4all을 만들었습니다. 처음으로 여러 모델이 한 곳에 모인 모습을 볼 수 있습니다
...
단 한 달 만에 명령어 튜닝, 양자화, 품질 개선, 인간 평가, 다중 양식, RLHF 등이 모두 나타났습니다.
더 중요한 것은 오픈소스 커뮤니티가 확장성 문제를 해결했고, 교육의 문턱이 대기업에서 1인 1박, 강력한 개인용 컴퓨터로 낮아졌다는 점입니다.
그래서 저자는 마지막에 이렇게 말했습니다. OpenAI도 우리처럼 실수를 했고, 오픈소스의 영향을 견딜 수 없습니다. 오픈소스가 Google에서 작동하도록 생태계를 구축해야 합니다.
Google은 이미 Android와 Chrome에서 이 패러다임을 큰 성공으로 구현했습니다. 대형 모델 오픈소스 분야의 리더로 자리매김하고 사고 리더, 리더로서의 입지를 계속 확고히 해야 합니다.
솔직히 지난 한 달 정도의 대형 언어 모델 개발은 정말 눈부시고 압도적이어서 매일 포격을 받고 있습니다.
이것은 인터넷이 막 시작되던 초기 시절을 생각나게 합니다. 오늘 하나의 흥미로운 웹사이트가 나타나고, 내일 또 다른 웹사이트가 나타납니다. 그리고 모바일 인터넷이 폭발적으로 성장하면 오늘 한 앱이 인기가 있고, 내일 또 다른 앱이 인기를 끌게 되는데...
개인적으로 저는 이러한 거대 언어 모델이 거대 기업에 의해 제어되는 것을 원하지 않습니다. 우리는 이러한 거대 모델을 "기생화"하고 해당 API를 호출하고 일부 애플리케이션을 개발할 수만 있는데 이는 매우 불쾌합니다. 백 송이의 꽃을 피우고 대중이 접근할 수 있도록 하여 모든 사람이 자신만의 개인 모델을 만들 수 있도록 하는 것이 가장 좋습니다.
이제 소규모 기업에도 교육 비용이 저렴해야 합니다. 프로그래머에게 교육 능력이 있다면 특정 산업 및 분야와 결합된 좋은 기회가 될 수 있습니다.
프로그래머가 사유화된 대형 모델을 능숙하게 마스터하려면 원칙 외에도 여전히 스스로 연습해야 합니다. 오픈 소스 커뮤니티를 통해 비용이 크게 절감되었지만 지구상에는 수십 명의 사람들이 연습하고 있습니다. 하지만 유용한 모델을 학습시키려면 여전히 하드웨어 환경에 대한 요구 사항이 너무 높습니다. RTX4090은 아무리 비싸도 GPU를 임대하는 데 드는 비용이 수만 달러입니다. 훈련을 위한 클라우드는 더욱 통제하기 어렵습니다. 훈련이 실패하면 돈이 낭비될 것입니다. 이는 언어나 프레임워크를 배우는 것과 다르며 몇 가지 설치 패키지를 다운로드하는 것과도 다르며 비용도 거의 들지 않습니다.
문턱이 더 낮아졌으면 좋겠습니다!
위 내용은 Google 내부 문서 유출: 오픈 소스 대형 모델은 너무 무서워서 OpenAI도 참을 수 없습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!