
Google과 MIT의 '반복적 공동 인증' 동영상 질의응답 모델: SOTA 성능, 80% 적은 컴퓨팅 성능 사용

- PHPz앞으로
- 2023-05-16 18:37:061173검색
비디오는 사람들의 일상 생활의 다양한 측면에 영향을 미치는 미디어 콘텐츠의 유비쿼터스 소스입니다. 비디오 자막, 콘텐츠 분석, 비디오 질문 답변(VideoQA) 등 점점 더 많은 실제 비디오 애플리케이션이 비디오 콘텐츠를 텍스트나 자연어에 연결할 수 있는 모델에 의존하고 있습니다.
그 중에서도 영상 질의응답 모델은 장면 속 대상 등의 의미적 정보와 사물이 어떻게 움직이고 상호작용하는지 등의 시간적 정보를 동시에 파악해야 하기 때문에 특히 까다롭습니다. 두 가지 유형의 정보 모두 특정 의도를 가진 자연어 질문의 맥락에 배치되어야 합니다. 또한 비디오에는 많은 프레임이 있으므로 시공간 정보를 학습하기 위해 모든 프레임을 처리하는 것은 계산적으로 불가능할 수 있습니다.

문서 링크: https://arxiv.org/pdf/2208.00934.pdf 이 문제를 해결하려면 "반복적 비디오-텍스트 공동 토큰화를 사용한 비디오 질문 답변" 기사를 참조하세요. , MIT의 Google 연구원은 비디오 질문과 답변의 정보 처리를 위해 공간적, 시간적, 언어적 정보를 효과적으로 융합할 수 있는 "반복적 공동 라벨링"이라는 새로운 비디오-텍스트 학습 방법을 도입했습니다.

이 접근 방식은 멀티 스트림으로, 독립적인 백본 모델을 사용하여 다양한 규모의 비디오를 처리하고 높은 공간 해상도 또는 장시간 비디오와 같은 다양한 특성을 포착하는 비디오 표현을 생성합니다. 이 모델은 "공동 인증" 모듈을 적용하여 비디오 스트림과 텍스트의 융합으로부터 효과적인 표현을 학습합니다. 이 모델은 계산상 매우 효율적이어서 이전 방법보다 최소 50% 더 낮은 67 GFLOP만 필요하며 다른 SOTA 모델보다 성능이 좋습니다.
비디오-텍스트 반복
이 모델의 주요 목표는 해당 입력이 상호 작용할 수 있도록 비디오와 텍스트(예: 사용자 질문)에서 기능을 생성하는 것입니다. 두 번째 목표는 이를 효율적인 방법으로 수행하는 것입니다. 이는 수십에서 수백 개의 입력 프레임을 포함하는 비디오에 매우 중요합니다.
모델은 공동 비디오 언어 입력을 더 작은 레이블 세트로 레이블 지정하여 두 양식을 공동으로 효율적으로 표현하는 방법을 학습합니다. 토큰화할 때 연구원은 두 모드를 모두 사용하여 결합 압축 표현을 생성하며, 이는 다음 수준 표현을 생성하기 위해 변환 레이어에 공급됩니다.
교차 모달 학습의 일반적인 문제이기도 한 여기서의 과제는 비디오 프레임이 관련 텍스트와 직접적으로 일치하지 않는 경우가 많다는 것입니다. 연구원들은 토큰화 전에 시각적 및 텍스트적 특징 차원을 통합하는 두 개의 학습 가능한 선형 레이어를 추가하여 이 문제를 해결했습니다. 이를 통해 연구원들은 비디오 태그가 학습되는 방법에 대해 비디오와 텍스트 조건을 모두 가질 수 있었습니다.
또한 단일 토큰화 단계에서는 두 모드 간의 추가 상호 작용이 허용되지 않습니다. 이를 위해 연구원들은 이 새로운 기능 표현을 사용하여 비디오 입력 기능과 상호 작용하고 또 다른 토큰화된 기능 세트를 생성한 후 다음 변환기 레이어에 공급합니다. 이 반복 프로세스는 두 모드의 공동 표현의 지속적인 개선을 나타내는 새로운 기능 또는 마커를 생성합니다. 마지막으로 이러한 기능은 텍스트 출력을 생성하는 디코더에 제공됩니다.

비디오 품질 평가의 일반적인 관행과 마찬가지로 연구원들은 개별 비디오 품질 평가 데이터 세트에서 모델을 미세 조정하기 전에 모델을 사전 교육했습니다. 이 연구에서 연구원들은 대규모 VideoQA 데이터 세트에 대한 사전 교육 대신 HowTo100M 데이터 세트를 사용하여 음성 인식 기반 텍스트로 비디오에 자동으로 주석을 달았습니다. 이 약한 사전 훈련 데이터 덕분에 연구원의 모델은 여전히 비디오 텍스트 기능을 학습할 수 있었습니다.
효율적인 영상 질의 응답 구현
연구원들은 영상 언어 반복 공동 인증 알고리즘을 3가지 주요 VideoQA 벤치마크인 MSRVTT-QA, MSVD-QA, IVQA에 적용하여 이 방식이 다른 수준의 성능을 능가함을 입증했습니다. 최첨단 모델 모델을 너무 크게 만들지 않고도 더 나은 결과를 얻을 수 있습니다. 또한, 반복적인 공동 라벨 학습에는 비디오 텍스트 학습 작업에 대한 컴퓨팅 성능도 더 낮아야 합니다.
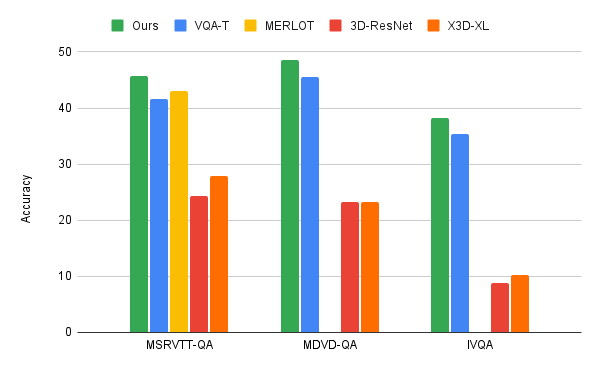
이 모델은 67GFLOPS의 컴퓨팅 성능만 사용합니다. 이는 3D-ResNet 비디오 모델 및 텍스트에 필요한 컴퓨팅 성능(360GFLOP)의 6분의 1에 해당하며 X3D 모델보다 효율성이 2배 이상 높습니다. . 최첨단 방법을 능가하는 매우 정확한 결과를 산출했습니다.
멀티 스트림 비디오 입력
VideoQA 또는 비디오 입력과 관련된 다른 작업의 경우 연구원들은 멀티 스트림 입력이 공간적, 시간적 관계에 대한 질문에 더 정확하게 대답하는 데 중요하다는 것을 발견했습니다.
연구원들은 해상도와 프레임 속도가 서로 다른 세 가지 비디오 스트림을 사용했습니다. 저해상도, 높은 프레임 속도 입력 비디오 스트림(초당 32프레임, 공간 해상도 64x64, 32x64x64로 표시됨); 프레임 속도 비디오(8x224x224)와 그 사이(16x112x112).
세 가지 데이터 스트림으로 처리해야 할 정보가 분명히 더 많지만, 반복적인 공동 라벨링 방법 덕분에 매우 효율적인 모델을 얻을 수 있습니다. 동시에 이러한 추가 데이터 스트림을 통해 가장 관련성이 높은 정보를 추출할 수 있습니다.
예를 들어 아래 그림에 표시된 것처럼 특정 활동과 관련된 질문은 해상도는 낮지만 프레임 속도는 높은 비디오 입력에서 더 높은 활성화를 생성하는 반면, 일반적인 활동과 관련된 질문은 낮은 해상도에서 높은 프레임 속도까지 다양할 수 있습니다. 더 적은 고해상도 입력으로 답변을 얻으세요.

이 알고리즘의 또 다른 이점은 질문에 따라 토큰화가 변경된다는 것입니다.
결론
연구진은 영상-텍스트 양식 전반에 걸친 공동 학습에 초점을 맞춘 새로운 영상 언어 학습 방법을 제안했습니다. 연구자들은 비디오 질문 답변이라는 중요하고 어려운 작업을 다루고 있습니다. 연구원의 접근 방식은 효율적이고 정확하며 더 효율적임에도 불구하고 현재의 최첨단 모델보다 성능이 뛰어납니다.
Google 연구원의 접근 방식은 모델 크기가 적당하며 더 큰 모델과 데이터를 사용하면 성능을 더욱 향상시킬 수 있습니다. 연구원들은 이 연구가 시각적 언어 학습에 대한 더 많은 연구를 촉발하여 시각적 기반 미디어와의 보다 원활한 상호 작용을 가능하게 하길 바라고 있습니다.
위 내용은 Google과 MIT의 '반복적 공동 인증' 동영상 질의응답 모델: SOTA 성능, 80% 적은 컴퓨팅 성능 사용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!