
URL 입력부터 페이지 콘텐츠의 최종 브라우저 렌더링까지 프로세스 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-16 11:28:121658검색
준비
브라우저에 URL(예: www.coder.com)을 입력하고 Enter 키를 누르면 브라우저가 가장 먼저 해야 할 일은 coder.com의 IP 주소를 얻는 것입니다. UDP 패킷을 DNS 서버로 전송하면 DNS 서버는 coder.com의 IP를 반환합니다. 이때 브라우저는 일반적으로 다음 액세스가 더 빨라지도록 IP 주소를 캐시합니다.
예를 들어 Chrome에서는 chrome://net-internals/#dns를 통해 볼 수 있습니다.
서버의 IP로 브라우저는 HTTP 요청을 시작할 수 있지만 HTTP 요청/응답은 TCP의 "가상 연결"에서 보내고 받아야 합니다.
"가상" TCP 연결을 설정하려면 TCP Postman은 4가지 정보(로컬 IP, 로컬 포트, 서버 IP, 서버 포트)를 알아야 합니다. 이제 로컬 IP, 서버 IP 및 두 개의 포트만 알고 있습니다. 하다?
로컬 포트는 매우 간단합니다. 서버 포트는 훨씬 더 간단합니다. HTTP 서비스는 80입니다. 우리는 TCP Postman에 직접 알립니다. .
3방향 핸드셰이크 후에 클라이언트와 서버 사이에 TCP 연결이 설정됩니다! 마지막으로 HTTP 요청을 보낼 수 있습니다.

TCP 연결을 점선으로 그린 이유는 이 연결이 가상이기 때문입니다
웹 서버
HTTP GET 요청은 수천 개의 산과 강을 거쳐 여러 라우터에 의해 전달되고 마침내 (HTTP 데이터 패킷은 하위 계층에 의해 조각화되어 전송될 수 있으며 이는 생략됩니다.)
웹 서버는 처리를 시작해야 합니다. 이를 처리하는 방법에는 세 가지가 있습니다.
(1) 하나의 스레드를 사용하여 모든 요청을 처리할 수 있으며 동시에 하나만 처리할 수 있습니다. 구현하지만 심각한 성능 문제가 발생합니다.
(2) 각 요청마다 프로세스/스레드를 할당할 수 있지만 연결이 너무 많으면 서버 측 프로세스/스레드가 많은 메모리 리소스를 소비하고 프로세스/스레드 전환도 부담이 됩니다. CPU.
(3) I/O를 재사용하기 위해 많은 웹 서버는 재사용 구조를 채택합니다. 예를 들어 모든 연결은 연결 상태가 변경되면(데이터를 읽을 수 있는 경우) 프로세스/스레드가 하나만 처리합니다. 해당 연결을 처리한 후 계속 모니터링하면서 다음 상태 변경을 기다립니다. 이런 방식으로 수천 개의 연결 요청을 소수의 프로세스/스레드로 처리할 수 있습니다.
아래 이야기를 계속하기 위해 매우 인기 있는 웹 서버인 Nginx를 사용합니다.
HTTP GET 요청의 경우 Nginx는 epoll을 사용하여 이를 읽습니다. 다음으로 Nginx는 이것이 정적 요청인지 동적 요청인지 확인해야 합니다.
정적 요청(HTML 파일, JavaScript 파일, CSS 파일, 그림 등)인 경우 직접 처리할 수도 있습니다(물론 Nginx 구성에 따라 다르며 다른 캐시 서버로 전달될 수 있음). 로컬 하드 디스크를 읽으면 관련 파일이 직접 반환됩니다.
반환되기 전에 백엔드 서버(예: Tomcat)에서 처리해야 하는 동적 요청인 경우 백엔드에 Tomcat이 두 개 이상 있으면 Tomcat으로 전달해야 합니다. 특정 전략에 따라 선택해야 합니다.
예를 들어 Ngnix에서는 다음과 같은 유형을 지원합니다.
Polling: 백엔드 서버에 하나씩 순서대로 전달
Weight: 각 백엔드 서버에 가중치를 할당합니다. 이는 백엔드 서버로 전달될 확률과 동일합니다. .
ip_hash: IP를 기반으로 해시 작업을 수행한 다음 이를 전달할 서버를 찾습니다. 이렇게 하면 항상 동일한 클라이언트 IP가 동일한 백엔드 서버로 전달됩니다.
fair: 백엔드 서버의 응답 시간을 기준으로 요청을 할당하고 응답 시간의 우선순위를 지정합니다.
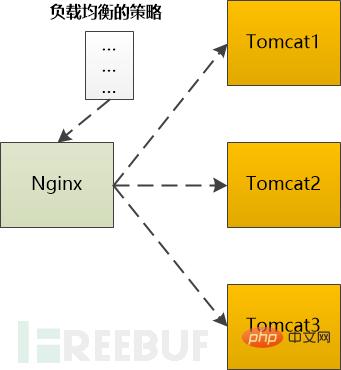
어떤 알고리즘을 사용하든 결국 백엔드 서버가 선택되고 Nginx는 HTTP 요청을 백엔드 Tomcat에 전달하고 Tomcat의 HttpResponse 출력을 브라우저에 전달해야 합니다.
이 시나리오에서는 Nginx가 에이전트 역할을 하는 것을 볼 수 있습니다.

Application Server
Http 요청이 마침내 Tomcat에 왔습니다. Tomcat은 Servlet/JSP를 처리할 수 있는 Java로 작성된 컨테이너입니다.
웹 서버와 마찬가지로 Tomcat은 처리할 각 요청에 대해 일반적으로 BIO 모드(Blocking I/O 모드)로 알려진 스레드를 할당할 수도 있습니다.
I/O 다중화 기술을 사용하고 몇 개의 스레드만 사용하여 모든 요청을 처리하는 것, 즉 NIO 모드도 가능합니다.
어떤 방법을 사용하든 Http 요청은 처리를 위해 서블릿으로 전달됩니다. 이 서블릿은 Http 요청을 프레임워크에서 사용하는 매개변수 형식으로 변환한 다음 이를 컨트롤러에 배포합니다(사용하는 경우). Spring) 또는 Action(Struts를 사용하는 경우).
나머지 이야기는 상대적으로 간단합니다(아니, 코더 입장에서는 실제로 가장 복잡한 부분입니다). 이 과정에서 코더가 자주 작성하는 추가, 삭제, 수정 및 검색 로직을 실행하는 것이 매우 어렵습니다. 캐시, 데이터베이스 등과 상호 작용할 가능성이 높습니다. 백엔드 구성 요소는 서로 처리하고 궁극적으로 HTTP 응답을 반환하므로 세부 사항은 비즈니스 논리에 따라 다르므로 생략됩니다.
우리의 예에 따르면 이 HTTP 응답은 HTML 페이지여야 합니다.
Homecoming
Tomcat이 Ngnix에 기쁜 마음으로 Http Response를 보냈습니다.
Ngnix는 또한 브라우저에 Http Response를 보내는 것을 기쁘게 생각합니다.

전송 후 TCP 연결을 닫을 수 있나요?
HTTP1.1을 사용하는 경우 이 연결은 기본적으로 연결 유지이므로 닫을 수 없습니다.
HTTP1.0을 사용하는 경우 연결 유지가 있는지 확인해야 합니다. 이전 HTTP 요청 헤더인 경우 닫을 수 없습니다.
브라우저가 다시 작동합니다
브라우저가 Http 응답을 수신하여 HTML 페이지를 읽고 페이지 표시 준비를 시작했습니다.
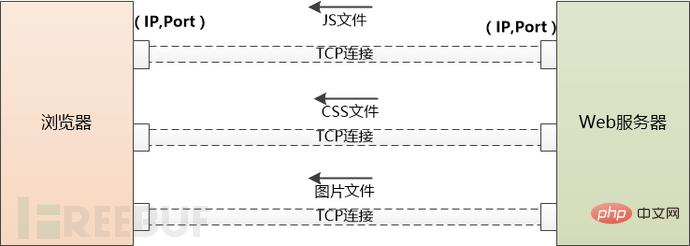
그러나 이 HTML 페이지는 js 파일, CSS 파일, 이미지 등과 같은 많은 다른 리소스를 참조할 수 있습니다. 이러한 리소스는 서버 측에도 있으며 static.coder와 같은 다른 도메인 이름 아래에 있을 수 있습니다. .com.
브라우저는 하나씩 다운로드할 수밖에 없습니다. DNS를 사용하여 IP를 얻는 것부터 시작하여 이전에 수행했던 작업을 다시 수행해야 합니다. 차이점은 더 이상 Tomcat과 같은 애플리케이션 서버의 개입이 없다는 것입니다.
다운로드해야 할 외부 리소스가 너무 많으면 브라우저는 여러 개의 TCP 연결을 생성하여 병렬로 다운로드합니다.
그러나 동시에 동일한 도메인 이름에 대한 요청 수는 너무 많아서는 안 됩니다. 그렇지 않으면 서버 트래픽이 너무 많아 견딜 수 없게 됩니다. 따라서 브라우저는 자체적으로 제한해야 합니다. 예를 들어 Chrome은 Http1.1에서 6개의 리소스만 병렬로 다운로드할 수 있습니다.
서버가 JS 및 CSS 파일을 브라우저에 보낼 때 이러한 파일이 만료되는 시기를 브라우저에 알려줍니다(Cache-Control 또는 Expire 사용). 브라우저는 파일을 로컬로 캐시하고 두 번째 요청을 기다릴 수 있습니다. 동일한 파일의 경우 만료되지 않은 경우 로컬 영역에서 검색하면 됩니다.
만료되면 브라우저는 파일이 수정되었는지 서버에 물어볼 수 있나요? (마지막 서버에서 보낸 Last-Modified 및 ETag를 기준으로) 수정되지 않은 경우(304 Not Modified) 캐싱을 사용할 수도 있습니다. 그렇지 않으면 서버는 최신 파일을 브라우저로 다시 보냅니다.
물론 Ctrl+F5를 누르면 캐시를 완전히 무시하고 강제로 GET 요청이 발생합니다.
참고: Chrome에서는 chrome://view-http-cache/ 명령을 통해 캐시를 볼 수 있습니다.
이제 브라우저는 세 가지 중요한 사항을 얻습니다.
1.HTML, 브라우저는 이를 DOM 트리로 변환합니다.
2. 브라우저는 이를 CSS 규칙 트리로 변환합니다.
3. 수정될 수 있습니다
브라우저는 DOM 트리와 CSS 규칙 트리를 통해 소위 "렌더 트리"를 생성하고 각 요소, 레이아웃의 위치/크기를 계산한 다음 그리기를 위해 운영 체제의 API를 호출합니다. 매우 복잡한 과정은 생략되어 표시되지 않습니다.
지금까지 브라우저에서 마침내 www.coder.com의 콘텐츠를 볼 수 있었습니다.
위 내용은 URL 입력부터 페이지 콘텐츠의 최종 브라우저 렌더링까지 프로세스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!