
Python 기본 모듈을 사용하는 방법

- 王林앞으로
- 2023-05-15 22:04:122009검색
1. 모듈
모듈은 함수의 집합이라고 볼 수 있습니다.
py 파일 안에는 여러 가지 함수가 들어갈 수 있으므로 py 파일을 모듈로 간주할 수 있습니다.
이 py 파일의 파일명이 module.py,模块名则是module.
1. 4가지 형태의 모듈
파이썬에는 총 4가지 형태의 모듈이 있습니다.
커스텀 모듈: py 파일을 직접 작성하고, 그 파일에 함수들을 잔뜩 적는다면, 이를 사용자 정의 모듈이라고 합니다. 즉, Python으로 작성된 .py 파일입니다.
타사 모듈: 요청과 같은 공유 라이브러리 또는 DLL로 컴파일된 C 또는 C++ 확장
내장 모듈: 작성됨 C에서 time
과 같은 Python 인터프리터의 내장 모듈에 연결됩니다. 패키지(폴더): 일련의 모듈을 함께 구성하는 폴더(참고: 폴더 아래에 __init__.py 파일이 있고, 패키지라고 합니다)
2. 왜 모듈을 사용하나요?
타사 또는 내장 모듈을 사용하는 것은 일종의 차용주의이며, 이는 개발 효율성을 크게 향상시킬 수 있습니다.
사용자 정의 모듈은 자체 프로그램에서 사용되는 공용 함수를 Python 파일에 작성한 다음 프로그램의 각 구성 요소를 가져오기를 통해 사용자 정의 모듈의 기능을 참조할 수 있습니다.
2. 모듈 사용 방법
일반적으로 모듈을 가져올 때는 import와 from...import...를 사용합니다.
spam.py의 다음 파일 코드를 예로 들어보세요.
# spam.py print('from the spam.py') money = 1000 def read1(): print('spam模块:', money) def read2(): print('spam模块') read1() def change(): global money money = 0
1. 가져오기 모듈 이름
의 구문은 다음과 같습니다.
import module1[, module2[,... moduleN]
가져온 모듈은 접두사를 사용하여 액세스해야 합니다.
처음으로 모듈을 가져올 때 세 가지 일이 발생합니다.
모듈을 기반으로 모듈의 네임스페이스를 생성합니다.
모듈에 해당하는 파일을 실행하고, 실행 중에 생성된 모든 이름을 모듈의 네임스페이스
현재 실행 파일에서 모듈 이름 가져오기
참고: 모듈을 반복적으로 가져오면 이전에 생성된 결과를 직접 참조하며 모듈의 파일은 반복적으로 실행되지 않습니다.
# run.py import spam # from the spam.py import spam money = 111111 spam.read1() # 'spam模块:1000' spam.change() print(spam.money) # 0 print(money) # 111111
가져오기 이름 바꾸기: smt 변수는 스팬 모듈의 네임스페이스를 가리킵니다.
# run.py import spam as sm money = 111111 sm.money sm.read1() # 'spam模块:1000' sm.read2 sm.change() print(money) # 1000
다중 모듈 가져오기
import spam, time, os # 推荐使用下述方式 import spam import time import os
2. from module name import 특정 함수
구문은 다음과 같습니다.
from modname import name1[, name2[, ... nameN]]
이 문은 그렇지 않습니다. 전체 모듈 가져오기 모듈에서 현재 네임스페이스로 하나 이상의 함수만 도입합니다.
...import...에서 가져온 모듈은 접두사를 사용하여 액세스할 필요가 없습니다.
from...import...처음으로 모듈을 가져올 때 세 가지 일이 발생합니다.
모듈을 기반으로 모듈 네임스페이스를 생성합니다.
모듈에 해당하는 파일을 실행하고 실행 중에 생성된 이름 모듈의 네임스페이스에 모두 던집니다
현재 실행 파일의 네임스페이스에서 이름을 가져옵니다. 이는 모듈의 이름을 직접 가리키므로 추가하지 않고도 직접 사용할 수 있습니다. prefix
-
장점: 접두사를 추가할 필요가 없으며 코드가 더 간소화됩니다.
단점: 현재 실행 파일의 네임스페이스에 있는 이름과 충돌하기 쉽습니다
# run.py from spam import money from spam import money,read1 money = 10 print(money) # 10
rom &hellip ; import * 문: 파일의 모든 함수 가져오기:
# spam.py __all__ = ['money', 'read1'] # 只允许导入'money'和'read1' # run.py from spam import * # 导入spam.py内的所有功能,但会受限制于__all__ money = 111111 read1() # 'spam模块:1000' change() read1() # 'spam模块:0' print(money) # 111111
3. 순환 가져오기
다음 상황에서 순환 가져오기가 발생합니다.
# m1.py print('from m1.py') from m2 import x y = 'm1' # m2.py print('from m2.py') from m1 import y x = 'm2'
함수 정의 단계에서 구문만 인식하는 기능을 사용하여 문제를 해결할 수 있습니다. 순환 수입 문제를 해결하거나 근본적으로 순환 수입 문제를 해결하지만 최선의 해결책은 순환 수입이 발생하지 않는 것입니다.
옵션 1:
# m1.py print('from m1.py') def func1(): from m2 import x print(x) y = 'm1' # m2.py print('from m2.py') def func1(): from m1 import y print(y) x = 'm2'
옵션 2:
5、# m1.py print('from m1.py') y = 'm1' from m2 import x # m2.py print('from m2.py') x = 'm2' from m1 import y
4.dir() 함수
내장 함수 dir()은 모듈에 정의된 모든 이름을 찾을 수 있습니다. 문자열 목록 형식으로 반환됨:
dir(sys) ['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags', 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount', 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'thread_info', 'version', 'version_info', 'warnoptions']
매개 변수가 지정되지 않은 경우 dir() 함수는 현재 정의된 모든 이름을 나열합니다.
a = [1, 2, 3, 4, 5] import fibo fib = fibo.fib print(dir()) # 得到一个当前模块中定义的属性列表 # ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] b = 5 # 建立一个新的变量 'a' print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b'] del b # 删除变量名a print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a']
3. 모듈 검색 경로
1. 시퀀스
1. 먼저 메모리에 있는 가져온 모듈부터 검색합니다.
run.py 파일 실행 시 mmm.py 파일을 빠르게 삭제하면 mmm 때문에 오류 보고 없이 파일이 계속 실행되는 것을 볼 수 있습니다. 메모리로 가져왔습니다. run.py를 다시 실행하면 mmm.py가 삭제되었기 때문에 오류가 보고됩니다.
# test.py import m1 # 从m1.py文件中导入的,然后会生成m1模块的名称空间 import time # 删除m1.py文件,m1模块的名称空间仍然存在 time.sleep(10) import m1 # 不报错,一定不是从文件中获取了m1模块,而是从内存中获取的
2. 내장 모듈
확인은 맞춤 time.py 파일이 아닌 내장 모듈에서 먼저 확인됩니다.
# time.py print('from time.py') # run.py import time print(time) #
3 환경 변수 sys.path에서 검색합니다. (강조: sys.path의 첫 번째 값은 현재 실행 파일이 있는 폴더입니다.)
import sys for n in sys.path: print(n) # C:\PycharmProjects\untitled\venv\Scripts\python.exe C:/PycharmProjects/untitled/hello.py # C:\PycharmProjects\untitled # C:\PycharmProjects\untitled # C:\Python\Python38\python38.zip # C:\Python\Python38\DLLs # C:\Python\Python38\lib # C:\Python\Python38 # C:\PycharmProjects\untitled\venv # C:\PycharmProjects\untitled\venv\lib\site-packages
mmm.py가 C:PycharmProjectsuntitledday16 경로에 있는 경우 실행 파일 경로는 C:PycharmProjectsuntitled 입니다. 정상적으로 import되면 오류가 발생합니다. 오류를 방지하기 위해 환경 변수 sys.path 에 C:PycharmProjectsuntitledday16 을 추가하면 됩니다.
# run.py import sys sys.path.append(r'C:\PycharmProjects\untitled\day16') print(sys.path) import mmm mmm.f1()
2. 검색 경로는 실행 파일을 기준으로 합니다.
다음 디렉터리 구조의 파일이 있고 파일의 코드는 다음과 같습니다.
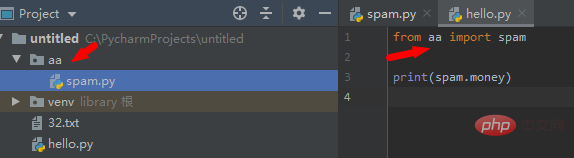
而hello和spam.py不是同目录下的,因此run.py的环境变量无法直接找到m2,需要从文件夹导入
from aa import spam print(spam.money)
四、Python文件的两种用途
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
python文件总共有两种用途,一种是执行文件;另一种是被当做模块导入。
每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
1、当run.py运行的时候,aaa.py被当做引用模块,它的__name__ == 'aaa'(模块名),会执行aaa.py中的f1()。
# aaa.py x = 1 def f1(): print('from f1') f1() # run.py import aaa
2、aaa.py被当做可执行文件时,加上__name__ == '__main__',单独运行aaa.py才会执行aaa.py中的f1()。 run.py运行时可以防止执行f1()。
# aaa.py x = 1 def f1(): print('from f1') if __name__ == '__main__': f1()
五、包
包是一种管理 Python 模块命名空间的形式,包的本质就是一个含有.py的文件的文件夹。
包采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
导入包发生的三件事:
创建一个包的名称空间
由于包是一个文件夹,无法执行包,因此执行包下的.py文件,将执行过程中产生的名字存放于包名称空间中(即包名称空间中存放的名字都是来自于.py)
在当前执行文件中拿到一个名字aaa,aaa是指向包的名称空间的
导入包就是在导入包下的.py,导入m1就是导入m1中的__init__。
1、两种方式导入:
import ... :
import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。from ... import...:
当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
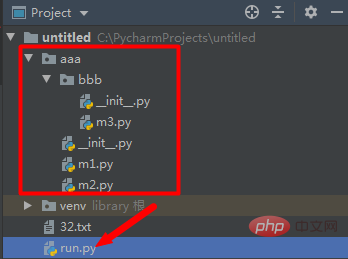
2、import 导入包内的模块
import 可以每次只导入一个包里面的特定模块,他必须使用全名去访问。
import aaa.bbb.m3 print(aaa.bbb.m3.func3())
import方式不能导入函数、变量:import aaa.bbb.m3.f3错误
3、from import方式:
导入模块内具体的模块
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb import m3 print(m3.func3())
导入模块内具体的功能
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb.m3 import func3 print(func3())
4、 绝对导入和相对导入
绝对导入:
# aaa/.py from aaa.m1 import func1 from aaa.m2 import func2
相对导入:
.代表当前被导入文件所在的文件夹
..代表当前被导入文件所在的文件夹的上一级
...代表当前被导入文件所在的文件夹的上一级的上一级
from .m1 import func1 from .m2 import func2
5、from...import *
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
这里有一个例子,在:file:sounds/effects/__init__.py中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
六、软件开发的目录规范
为了提高程序的可读性与可维护性,我们应该为软件设计良好的目录结构,这与规范的编码风格同等重要,简而言之就是把软件代码分文件目录。假设你要写一个ATM软件,你可以按照下面的目录结构管理你的软件代码:
ATM/ |-- core/ | |-- src.py # 业务核心逻辑代码 | |-- api/ | |-- api.py # 接口文件 | |-- db/ | |-- db_handle.py # 操作数据文件 | |-- db.txt # 存储数据文件 | |-- lib/ | |-- common.py # 共享功能 | |-- conf/ | |-- settings.py # 配置相关 | |-- bin/ | |-- run.py # 程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤 | |-- log/ | |-- log.log # 日志文件 | |-- requirements.txt # 存放软件依赖的外部Python包列表,详见https://pip.readthedocs.io/en/1.1/requirements.html |-- README # 项目说明文件
settings.py
# settings.py import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DB_PATH = os.path.join(BASE_DIR, 'db', 'db.txt') LOG_PATH = os.path.join(BASE_DIR, 'log', 'user.log') # print(DB_PATH) # print(LOG_PATH)
common.py
# common.py import time from conf import settings def logger(msg): current_time = time.strftime('%Y-%m-%d %X') with open(settings.LOG_PATH, mode='a', encoding='utf-8') as f: f.write('%s %s' % (current_time, msg))
src.py
# src.py
from conf import settings
from lib import common
def login():
print('登陆')
def register():
print('注册')
name = input('username>>: ')
pwd = input('password>>: ')
with open(settings.DB_PATH, mode='a', encoding='utf-8') as f:
f.write('%s:%s\n' % (name, pwd))
# 记录日志。。。。。。
common.logger('%s注册成功' % name)
print('注册成功')
def shopping():
print('购物')
def pay():
print('支付')
def transfer():
print('转账')
func_dic = {
'1': login,
'2': register,
'3': shopping,
'4': pay,
'5': transfer,
}
def run():
while True:
print("""
1 登陆
2 注册
3 购物
4 支付
5 转账
6 退出
""")
choice = input('>>>: ').strip()
if choice == '6': break
if choice not in func_dic:
print('输入错误命令,傻叉')
continue
func_dic[choice]()run.py
# run.py import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import src if __name__ == '__main__': src.run()
위 내용은 Python 기본 모듈을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!