
Python에서 체인 호출을 구현하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-15 18:28:062116검색
체인콜을 하는 이유는 무엇인가요?
체인 호출 또는 메소드 체이닝이라고도 하는 것은 문자 그대로 일련의 작업 또는 체인과 같은 함수 메소드를 함께 묶는 코드 메소드를 의미합니다.
R 언어의 파이프라인 연산자를 사용하면서 체인콜의 '아름다움'을 처음 깨달았습니다.
library(tidyverse) mtcars %>% group_by(cyl) %>% summarise(meanmeanOfdisp = mean(disp)) %>% ggplot(aes(x=as.factor(cyl), y=meanOfdisp, fill=as.factor(seq(1,3))))+ geom_bar(stat = 'identity') + guides(fill=F)
R 사용자의 경우 이 코드 조각으로 전체 프로세스 단계가 무엇인지 빠르게 이해할 수 있습니다. 모든 것은 %>% 기호(파이프 연산자)로 시작됩니다.
파이프 연산자를 통해 왼쪽에 있는 것을 다음으로 전달할 수 있습니다. 여기서는 mtcars 데이터 세트를 group_by 함수에 전달한 다음 결과를 요약 함수에 전달하고 마지막으로 시각적 그리기를 위해 ggplot 함수에 전달합니다.
연쇄 호출을 배우지 않았다면 처음 R 언어를 배울 때 다음과 같이 썼을 것입니다.
library(tidyverse) cyl4 <p>파이프 연산자를 사용하지 않았다면 불필요한 할당을 하고 원본을 덮어썼을 것입니다. data 객체. 그러나 실제로 생성된 cyl# 및 데이터는 실제로 그래프 그림만 제공하므로 문제는 코드가 중복된다는 것입니다. </p><p>체인 호출은 코드를 크게 단순화할 뿐만 아니라 코드의 가독성도 향상시킵니다. 각 단계가 수행하는 작업을 빠르게 이해할 수 있습니다. 이 방법은 데이터 분석이나 데이터 처리에 매우 유용하며, 불필요한 변수의 생성을 줄이고 빠르고 간단하게 탐색할 수 있습니다. </p><p>체인 콜이나 파이프라인 작업은 여러 곳에서 볼 수 있습니다. 여기서는 R 언어 외에 두 가지 대표적인 예를 들어 보겠습니다. </p><p>첫 번째는 Shell 문입니다. </p><pre class="brush:php;toolbar:false">echo "`seq 1 100`" | grep -e "^[3-4].*" | tr "3" "*"
shell 문에서 "|" 파이프 연산자를 사용하면 체인 호출을 빠르게 구현할 수 있습니다. 여기서는 먼저 1-100의 모든 정수를 인쇄한 다음 이를 grep 메서드에 전달하고 추출합니다. 3 또는 4로 시작하는 모든 부분을 tr 메소드에 전달하고 3이 포함된 숫자 부분을 별표로 바꿉니다. 결과는 다음과 같습니다.
다른 하나는 Scala 언어입니다:
object Test { def main(args: Array[String]): Unit = { val numOfseq = (1 to 100).toList val chain = numOfseq.filter(_%2==0) .map(_*2) .take(10) } }이 예에서는 먼저 numOfseq 변수에 1~100의 모든 정수가 포함되고, 그런 다음 체인 부분부터 먼저 numOfseq 메서드를 기반으로 필터를 호출하여 이 숫자의 짝수 부분을 필터링한 다음 map 메소드를 호출하여 필터링된 숫자에 2를 곱하고 마지막으로 take 메소드를 사용하여 새로 형성된 숫자에서 처음 10개의 숫자를 추출하고 이 숫자를 체인 변수에 공동으로 할당합니다.
위의 설명을 통해 체인 콜에 대한 예비적인 인상을 받을 수 있다고 생각하지만, 체인 콜을 마스터하고 나면 코딩 스타일을 바꾸는 것 외에도 프로그래밍 사고 방식도 달라질 것입니다.
Python의 연쇄 호출
Python에서 간단한 연쇄 호출을 구현하려면 클래스 메서드를 구축하고 객체 자체를 반환하거나 속성이 지정된 클래스(@classmethod)를 반환하는 것입니다(@classmethod)
class Chain: def __init__(self, name): self.name = name def introduce(self): print("hello, my name is %s" % self.name) return self def talk(self): print("Can we make a friend?") return self def greet(self): print("Hey! How are you?") return self if __name__ == '__main__': chain = Chain(name = "jobs") chain.introduce() print("-"*20) chain.introduce().talk() print("-"*20) chain.introduce().talk().greet()여기서 Chain 클래스를 생성합니다. 인스턴스 객체를 생성하기 위해 이름 문자열 매개변수를 전달하기 위해 이 클래스에는 소개, 대화 및 인사라는 세 가지 메소드가 있습니다.
self가 매번 반환되므로 객체가 속한 클래스에서 계속해서 메서드를 호출할 수 있습니다. 결과는 다음과 같습니다.
hello, my name is jobs -------------------- hello, my name is jobs Can we make a friend? -------------------- hello, my name is jobs Can we make a friend? Hey! How are you?
Pandas에서 체인 호출 사용하기
오랜 준비 끝에 드디어 이야기를 나눴습니다. Pandas 체인 호출에 관한 부분
Pandas의 대부분의 메소드는 체인 메소드를 사용하는 작업에 적합합니다. API 처리 후 반환되는 것이 Series 유형 또는 DataFrame 유형인 경우가 많기 때문에 해당 메소드를 직접 호출할 수 있습니다. 여기서는 예를 들어 보겠습니다. 올해 2월경 다른 사람들에게 사례 시연을 할 때 크롤링했던 화농형제 B 방송국의 영상 데이터. 링크를 통해 받으실 수 있습니다.
데이터 필드 정보는 다음과 같습니다. 300개의 데이터와 20개의 필드가 있습니다.
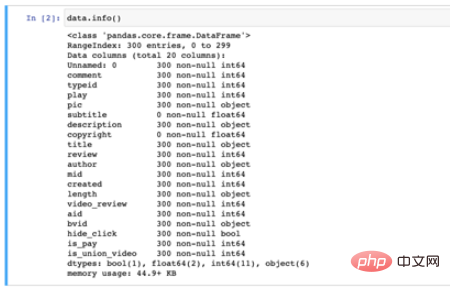
필드 정보
하지만 이 데이터 부분을 사용하기 전에 이 부분을 사전 정리해야 합니다. 데이터에서는 주로 다음 필드를 선택했습니다.
aid: 동영상에 해당하는 av 번호
comment: 댓글 수
play: 재생 볼륨
title: title
video_review : 사격 수 : 업로드 날짜 : 비디오 지속 - 1. 각 필드의 해당 값은 다음과 같습니다. 필드 값
- 우리가 볼 수 있는 데이터:
생성됨 업로드 날짜는 일련의 긴 값으로 표시되는 것처럼 보이지만 실제로는 1970년부터 현재까지의 타임스탬프이므로 읽을 수 있는 연도, 월, 일 형식으로 처리해야 합니다.
length 播放量长度只显示了分秒,但是小时并未用「00」来进行补全,因此这里我们一方面需要将其补全,另一方面要将其转换成对应的时间格式
链式调用操作如下:
import re import pandas as pd # 定义字数统计函数 def word_count(text): return len(re.findall(r"[\u4e00-\u9fa5]", text)) tidy_data = ( pd.read_csv('~/Desktop/huanong.csv') .loc[:, ['aid', 'title', 'created', 'length', 'play', 'comment', 'video_review']] .assign(title = lambda df: df['title'].str.replace("华农兄弟:", ""), title_count = lambda df: df['title'].apply(word_count), created = lambda df: df['created'].pipe(pd.to_datetime, unit='s'), created_date = lambda df: df['created'].dt.date, length = lambda df: "00:" + df['length'], video_length = lambda df: df['length'].pipe(pd.to_timedelta).dt.seconds ) )
这里首先是通过loc方法挑出其中的列,然后调用assign方法来创建新的字段,新的字段其字段名如果和原来的字段相一致,那么就会进行覆盖,从assign中我们可以很清楚地看到当中字段的产生过程,同lambda 表达式进行交互:
1.title 和title_count:
原有的title字段因为属于字符串类型,可以直接很方便的调用str.* 方法来进行处理,这里我就直接调用当中的replace方法将「华农兄弟:」字符进行清洗
基于清洗好的title 字段,再对该字段使用apply方法,该方法传递我们前面实现定义好的字数统计的函数,对每一条记录的标题中,对属于\u4e00到\u9fa5这一区间内的所有 Unicode 中文字符进行提取,并进行长度计算
2.created和created_date:
对原有的created 字段调用一个pipe方法,该方法会将created 字段传递进pd.to_datetime 参数中,这里需要将unit时间单位设置成s秒才能显示出正确的时间,否则仍以 Unix 时间错的样式显示
基于处理好的created 字段,我们可以通过其属于datetime64 的性质来获取其对应的时间,这里 Pandas 给我们提供了一个很方便的 API 方法,通过dt.*来拿到当中的属性值
3.length 和video_length:
原有的length 字段我们直接让字符串00:和该字段进行直接拼接,用以做下一步转换
基于完整的length时间字符串,我们再次调用pipe方法将该字段作为参数隐式传递到pd.to_timedelta方法中转化,然后同理和create_date字段一样获取到相应的属性值,这里我取的是秒数。
2、播放量趋势图
基于前面稍作清洗后得到的tidy_data数据,我们可以快速地做一个播放量走势的探索。这里我们需要用到created这个属于datetime64的字段为 X 轴,播放量play 字段为 Y 轴做可视化展示。
# 播放量走势 %matplotlib inline %config InlineBackend.figure_format = 'retina' import matplotlib.pyplot as plt (tidy_data[['created', 'play']] .set_index('created') .resample('1M') .sum() .plot( kind='line', figsize=(16, 8), title='Video Play Prend(2018-2020)', grid=True, legend=False ) ) plt.xlabel("") plt.ylabel('The Number Of Playing')
这里我们将上传日期和播放量两个选出来后,需要先将created设定为索引,才能接着使用resample重采样的方法进行聚合操作,这里我们以月为统计颗粒度,对每个月播放量进行加总,之后再调用plot 接口实现可视化。
链式调用的一个小技巧就是,可以利用括号作用域连续的特性使整个链式调用的操作不会报错,当然如果不喜欢这种方式也可以手动在每条操作后面追加一个\符号,所以上面的整个操作就会变成这样:
tidy_data[['created', 'play']] \ .set_index('created') \ .resample('1M') .sum() .plot( \ kind='line', \ figsize=(16, 8), \ title='Video Play Prend(2018-2020)', \ grid=True, \ legend=False \ )
但是相比于追加一对括号来说,这种尾部追加\符号的方式并不推荐,也不优雅。
但是如果既没有在括号作用域或未追加\ 符号,那么在运行时 Python 解释器就会报错。
3、链式调用性能
通过前两个案例我们可以看出链式调用可以说是比较优雅且快速地能实现一套数据操作的流程,但是链式调用也会因为不同的写法而存在性能上的差异。
这里我们继续基于前面的tidy_data操作,这里我们基于created_date 来对play、comment和video_review进行求和后的数值进一步以 10 为底作对数化。最后需要得到以下结果:
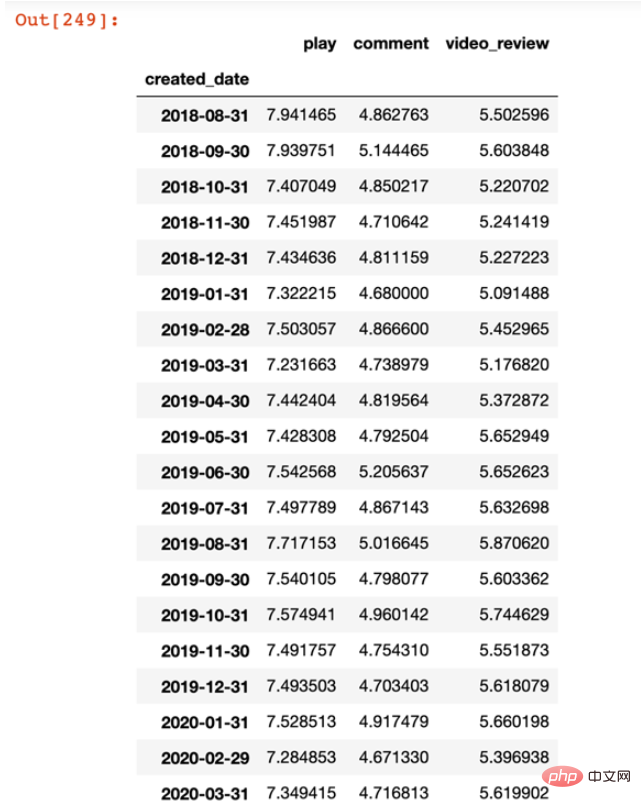
统计表格
写法一:一般写法
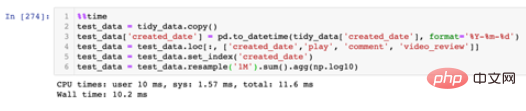
一般写法
这种写法就是基于tidy_data拷贝后进行操作,操作得到的结果会不断地覆盖原有的数据对象
写法二:链式调用写法
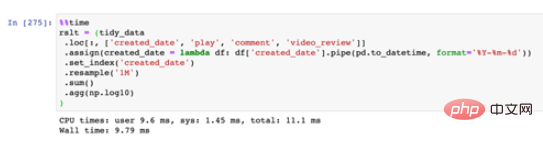
链式调用写法
可以看到,链式调用的写法相比于一般写法而言会快上一点,不过由于数据量比较小,因此二者时间的差异并不大;但链式调用由于不需要额外的中间变量已经覆盖写入步骤,在内存开销上会少一些。
结尾:链式调用的优劣
从本文的只言片语中,你能领略到链式调用使得代码在可读性上大大的增强,同时以尽肯能少的代码量去实现更多操作。
当然,链式调用并不算是完美的,它也存在着一定缺陷。比如说当链式调用的方法超过 10 步以上时,那么出错的几率就会大幅度提高,从而造成调试或 Debug 的困难。比如这样:
(data .method1(...) .method2(...) .method3(...) .method4(...) .method5(...) .method6(...) .method7(...) # Something Error .method8(...) .method9(...) .method10(...) .method11(...) )
위 내용은 Python에서 체인 호출을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!