
Java의 I/O 입력 및 출력 예제 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-13 15:40:061678검색
머리말
변수, 배열, 객체에 저장된 데이터는 일시적이며 프로그램이 종료되면 손실됩니다. 생성된 데이터를 영구적으로 저장하려면 다른 프로그램에서 사용할 수 있도록 디스크 파일로 저장해야 합니다. Java의 I/O 기술은 데이터를 텍스트 파일, 바이너리 파일, ZIP 압축 파일로 저장할 수 있어 영구 데이터 저장 요구 사항을 충족합니다. I/O 처리 기술을 익히면 데이터 처리 능력이 향상됩니다.
1. 스트림 개요
스트림은 작업 유형에 따라 입력 스트림과 출력 스트림의 두 가지 유형으로 나눌 수 있습니다. I/O(입력/출력) 스트림은 소스에서 대상으로 일련의 바이트를 보내는 데 사용할 수 있는 채널 프로그램을 제공합니다. I/O 스트림은 일반적으로 디스크 파일 액세스와 연관되어 있지만 프로그램의 소스와 대상은 키보드, 마우스, 메모리 또는 모니터 창이 될 수도 있습니다.
Java는 데이터 스트림별로 입력/출력 모드를 처리합니다. 소스는 파일, 네트워크, 압축 패키지 또는 기타 데이터 소스일 수 있습니다.
출력 스트림은 데이터가 도달할 대상을 가리키고, 프로그램은 출력 스트림에 데이터를 기록하여 대상으로 정보를 전송합니다.
2. 입력/출력 스트림
Java 언어는 다양한 형태의 입력/출력을 담당하는 많은 클래스를 정의합니다. 이러한 클래스는 java.io 패키지에 있습니다. 그 중 모든 입력 스트림 클래스는 추상 클래스 InputStream(바이트 입력 스트림) 또는 추상 클래스 Reader(문자 입력 스트림)의 하위 클래스이고 모든 출력 스트림은 추상 클래스 OutputStream(바이트 출력 스트림) 또는 추상 클래스 Writer(문자의 하위 클래스)입니다. 출력 스트림).
1. 입력 스트림
InputStream 클래스는 바이트 입력 스트림의 추상 클래스이자 모든 바이트 입력 스트림의 상위 클래스입니다. InputStream 클래스의 구체적인 계층 구조는 다음과 같습니다.
이 클래스의 모든 메소드는 오류가 발생하면 IOException을 발생시킵니다. 다음은 이 클래스의 일부 메소드에 대한 간략한 설명입니다.
read() 메서드: 입력 스트림에서 데이터의 다음 바이트를 읽습니다. 0-255 범위의 int 바이트 값을 반환합니다. 스트림 끝에 도달하여 사용할 수 있는 바이트가 없는 경우 반환 값은 -1입니다.
read(byte[] b): 입력 스트림에서 특정 길이의 바이트를 읽고 정수 형식으로 바이트 수를 반환합니다.
mark(int readlimit) 메서드: 입력 스트림의 현재 위치에 표시를 배치합니다. readlimit 매개변수는 이 입력 스트림에 표시 위치가 만료되기 전에 읽을 수 있는 바이트 수를 알려줍니다.
reset() 메서드: 입력 포인터를 현재 표시로 되돌립니다.
skip(long n) 메서드: 입력 스트림에서 n 바이트를 건너뛰고 건너뛴 실제 바이트 수를 반환합니다.
markSupported() 메서드: 현재 스트림이 mark()/reset() 작업을 지원하는 경우 true를 반환합니다.
close 메서드: 이 입력 스트림을 닫고 스트림과 관련된 모든 시스템 리소스를 해제합니다.
Java의 문자는 유니코드로 인코딩되며 더블바이트입니다. InputStream은 바이트를 처리하는 데 사용되며 문자 텍스트 처리에는 적합하지 않습니다. Java는 문자 텍스트 입력을 위해 별도의 Reader 클래스 세트를 제공합니다. 그러나 Reader 클래스는 문자열을 처리할 때 프로그래밍을 단순화합니다. Reader 클래스는 문자 입력 스트림의 추상 클래스이며 문자 입력 스트림의 모든 구현은 해당 하위 클래스입니다.
Reader 클래스의 메서드는 InputStream 클래스의 메서드와 유사합니다. 독자는 필요할 때 JDK 문서를 확인할 수 있습니다.
2. 출력 스트림
OutputStream 클래스는 바이트 출력 스트림의 추상 클래스입니다. 이 추상 클래스는 출력 바이트 스트림을 나타내는 모든 클래스의 상위 클래스입니다.
OutputStream 클래스의 모든 메서드는 void를 반환하고 오류가 발생하면 IoException이 발생합니다. 다음은 OutputStream 클래스의 메서드에 대한 간략한 소개입니다.
write(int b) 메서드: 지정된 바이트를 이 출력 스트림에 씁니다.
write(byte[] b) 메서드: 지정된 바이트 배열의 b 바이트를 이 출력 스트림에 씁니다.
write(byte[] b,int off, int len) 방법: 지정된 바이트 배열의 오프셋 off에서 시작하는 len 바이트를 이 출력 스트림에 씁니다.
flush() 메서드: 출력을 완전히 완료하고 캐시 영역을 지웁니다.
close() 메서드: 출력 스트림을 닫습니다.
3. File 클래스
File 클래스는 디스크 파일 자체를 나타내는 java.io 패키지의 유일한 개체입니다. File 클래스는 파일을 작동하기 위한 일부 플랫폼 독립적인 메소드를 정의하며 File 클래스의 메소드를 호출하여 파일을 생성, 삭제, 이름 바꾸기 및 기타 작업을 수행할 수 있습니다. File 클래스의 객체는 주로 파일이 있는 디렉터리, 파일 길이, 파일 읽기 및 쓰기 권한 등과 같은 파일 자체에 대한 일부 정보를 얻는 데 사용됩니다. 데이터 스트림은 데이터를 파일에 쓸 수 있으며 파일은 데이터 스트림에 가장 일반적으로 사용되는 데이터 미디어이기도 합니다.
1. 파일 생성 및 삭제
File 클래스를 사용하여 파일 개체를 만들 수 있습니다. 파일 객체를 생성하는 데에는 일반적으로 다음 3가지 구성 방법이 사용됩니다.
1.File(String pathname)
이 생성자는 주어진 경로명 문자열을 추상 경로명으로 변환하여 새 File 인스턴스를 생성합니다.
구문은 다음과 같습니다.
new File(String pathname);
이 중 pathname은 경로 이름(파일 이름 포함)을 지정합니다. 예:
파일 파일 = 새 파일(“d:/1.txt”);
2.File(String parent,String child)
이 생성자는 정의된 상위 경로 및 하위 경로 문자열(파일 이름 포함)을 기반으로 새 File 객체를 생성합니다.
구문은 다음과 같습니다:
new File(String parent,String child);
3.File(File f,String child)
이 생성자는 Parent 추상 경로 이름을 기반으로 새 파일을 생성하고 하위 경로 이름 문자열 파일 인스턴스입니다.
구문은 다음과 같습니다:
new File(File f,String child);
2. 파일 정보 가져오기
File 클래스는 파일 자체에 대한 일부 정보를 가져오는 다양한 메서드를 제공합니다. 다음 표와 같이
1. FillInputStream 및 FileOutputStream 클래스 FileInputStream 클래스와 FileOUTputStream 클래스는 모두 디스크 파일을 작동하는 데 사용됩니다. 사용자의 파일 읽기 요구 사항이 상대적으로 간단한 경우에는 InputString 클래스에서 상속된 FileInputString 클래스를 사용할 수 있습니다. FileOutputStream 클래스는 FileInputStream 클래스에 해당하며 기본 파일 쓰기 기능을 제공합니다. FileOutputStream 클래스는 OutputStream 클래스의 하위 클래스입니다.메소드 | 반환 값 | 설명
------- -----
getName() | 파일 이름 가져오기
canReda() | 파일을 읽을 수 있는지 확인
canWrite()| boolean | 파일을 쓸 수 있는지 확인
exits()|boolean | 파일이 존재하는지 확인
length()|long | getAbsolutePath() | String | 파일의 절대 경로 가져오기
isFile() | boolean | 파일이 있는지 확인 | 디렉토리입니다
isHidden() | boolean | 파일이 숨겨진 파일인지 확인
lastModified() | long | 파일의 마지막 수정 시간을 가져옵니다
4. 파일 실행 중 프로그램이 종료되거나 종료되면 대부분의 데이터는 메모리에서 연산됩니다. 데이터를 영구적으로 저장해야 하는 경우 파일 입/출력 스트림을 사용하여 지정된 파일과 연결을 설정하고 필요한 데이터를 파일에 영구적으로 저장할 수 있습니다.
FileInputStream 클래스의 일반적으로 사용되는 생성 방법은 다음과 같습니다.
FileInputStream(문자열 이름)FileInputStream(파일 파일)
2 FileReader 및 FileWriter 클래스FileReader 및 FileWriter 문자 스트림은 FileInputStream 및 FileOutputStream 클래스에 해당합니다. FileReader 스트림은 스트림이 닫히지 않는 한 read() 메서드를 호출할 때마다 소스 끝이나 스트림이 닫힐 때까지 나머지 소스 내용을 순차적으로 읽습니다. 5. 캐시를 사용한 입출력 스트림캐시는 I/O의 성능 최적화입니다. 캐시 스트림은 I/O 스트림에 메모리 캐시 영역을 추가합니다. 버퍼 영역을 사용하면 스트림에서 Skip(), mark() 및 Reset() 메서드를 실행할 수 있습니다. 1. BufferedInputStream 및 BufferedOutputStream 클래스 BufferedInputStream 클래스는 성능을 최적화하기 위해 모든 InputStream 클래스를 버퍼로 래핑할 수 있습니다. BufferedInputStream 클래스에는 두 가지 구성 방법이 있습니다.
FileOutputStream 클래스를 사용하여 파일에 데이터를 쓰고 파일에서 데이터를 읽으려면 FileInputStream 클래스를 사용하십시오. 내용을 읽는 데에는 한 가지 단점이 있습니다. 즉, 두 클래스 모두 바이트 또는 바이트 배열을 읽는 방법만 제공한다는 것입니다. Hanzi는 파일에서 2바이트를 차지하므로 바이트 스트림을 사용하면 읽기가 좋지 않을 경우 문자가 깨져 보일 수 있습니다. 이 경우 문자 스트림 Reader 또는 Writer 클래스를 사용하면 이러한 현상을 피할 수 있습니다.
BufferedInputStream(InputStream in)
BufferedInputStream(InputStream in, int size)첫 번째 구성 방법은 32바이트의 버퍼 영역을 생성하고 두 번째 구성 방법은 Create로 시작합니다. 지정된 크기의 버퍼.BufferedReader 클래스와 BufferedWriter 클래스는 각각 Reader 클래스와 Writer 클래스를 상속합니다. 두 클래스 모두 내부 캐싱 메커니즘을 갖고 있으며 라인 단위로 입출력을 수행할 수 있습니다. 6. 데이터 입력/출력 스트림데이터 입력/출력 스트림(DataInputStream 클래스 및 DataOutputStream 클래스)을 사용하면 애플리케이션이 기계 독립적인 방식으로 기본 입력 스트림에서 기본 Java 데이터 유형을 읽을 수 있습니다. 즉, 데이터 조각을 읽을 때 더 이상 값이 어떤 종류의 바이트여야 하는지 걱정할 필요가 없습니다. 7. ZIP 압축 입출력 스트림ZIP 압축 관리 파일(ZIP 아카이브)은 저장 공간을 절약할 수 있는 매우 일반적인 파일 압축 형태입니다. ZIP 압축의 I/O 구현과 관련하여 Java의 내장 클래스는 매우 유용한 관련 클래스를 제공하므로 구현이 매우 간단합니다. 이 섹션에서는 파일 압축/압축 해제를 달성하기 위해 java.util.zip 패키지의 ZipOutputStream 및 ZipInputStream 클래스 사용을 소개합니다. ZIP으로 압축된 관리 파일에서 파일을 읽으려면 먼저 해당 파일의 "디렉터리 진입점"(ZIP 파일의 파일 위치를 알 수 있음)을 찾아야 내용을 읽을 수 있습니다. 파일의. 파일 내용을 ZIP 파일로 쓰려면 먼저 해당 파일에 해당하는 "디렉터리 진입점"을 작성하고, 파일 내용이 기록될 위치를 이 진입점이 가리키는 위치로 이동해야 하며, 그런 다음 파일 내용을 작성합니다.
2. BufferedReader 및 BufferedWriter 클래스
Java实现了I/O数据流与网络数据流的单一接口,因此数据的压缩、网络传输和解压缩的实现比较容易。ZipEntry类产生的对象,是用来代表一个ZIP压缩文件内的进入点(entry)。ZipInputStream用来写出ZIP压缩格式的文件,所支持的包括已压缩及未压缩的进入点(entry)。
ZipOutputStream类用来写出ZIp压缩格式的文件,而且所支持的包括已压缩及未压缩的进入点(entry)。下面介绍利用ZipEntry、
ZipInputStream和ZipOutputStream3个Java类实现ZIP数据压缩方式的编程方法。
1、压缩文件
利用ZipOutputStream类对象,可将文件压缩为.zip文件。ZipOutputStream类的构造方法如下:
ZipOutputStram(OutputStream out);
ZipOutputStream类的常用方法如表所示:
| 方法 | 返回值 | 说明 |
|---|---|---|
| putNextEntry(ZipEntry e) | void | 开始写一个新的ZipEntry,并将流内的位置移至此entry所指数据的开头 |
| write(byte[] b,int off,int len) | void | 将字节数组写入当前ZIP条目数据 |
| finish() | void | 完成写入ZIP输出流的内容,无须关闭它所配合的OutputStream |
| setComment(String comment) | void | 可设置此ZIP文件的注释文字 |
2、解压缩ZIP文件
ZipInputStream类可读取ZIP压缩格式的文件,包括已压缩和未压缩的条目(entry)。ZipInputStream类的构造方法如下:
ZipInputStream(InputStream in)
ZipInputStream类的常用方法如下表所示:
| 方法 | 返回值 | 说明 |
|---|---|---|
| read(byte[] b, int off , int len) | int | 读取目标b数组内off偏移量的位置,长度是len字节 |
| available() | int | 判断是否已读完目前entry所指定的数据。已读完返回0,否则返回1 |
| closeEntry() | void | 关闭当前ZIP条目并定位流以读取下一个条目 |
| skip(long n) | long | 跳过当前ZIP条目中指定的字节数 |
| getNextEntry() | ZipEntry | 读取下一个ZipEntry,并将流内的位置移至该entry所指数据的开头 |
| createZipEntry(String name) | ZipEntry | 以指定的name参数新建一个ZipEntry对象 |
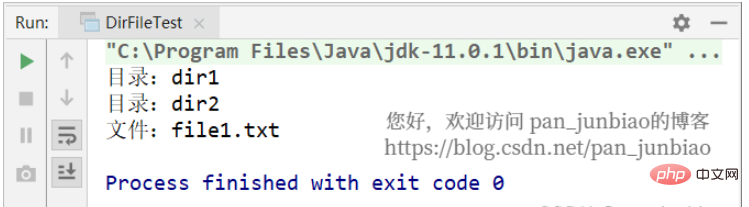
补充:获取目录下的所有目录和文件
示例:假设目录“D:\TestDir1”下有两个文件夹(dir1 和 dir2)和一个文件 file1.txt 。
File[] listFiles()方法:获取该目录下的所有子目录和文件,返回File类数组。
import java.io.File;
/**
* 获取目录下的所有目录和文件
* @author pan_junbiao
**/
public class DirFileTest
{
public static void main(String[] args)
{
File file = new File("D:\\TestDir1");
//判断目录是否存在
if (!file.exists())
{
System.out.println("目录不存在");
return;
}
//获取文件数组
File[] fileList = file.listFiles();
for (int i = 0; i < fileList.length; i++)
{
//判断是否为目录
if (fileList[i].isDirectory())
{
System.out.println("目录:" + fileList[i].getName());
}
else
{
System.out.println("文件:" + fileList[i].getName());
}
}
}
}执行结果:
위 내용은 Java의 I/O 입력 및 출력 예제 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!