
ChatGPT 기억상실증을 완전히 해결해보세요! Transformer 입력 제한 돌파: 200만 개의 유효 토큰을 지원하는 것으로 측정됨

- 王林앞으로
- 2023-05-13 14:07:062113검색
ChatGPT 또는 Transformer 클래스 모델에는 잊어버리기가 너무 쉽다는 치명적인 결함이 있습니다. 입력 시퀀스의 토큰이 컨텍스트 창 임계값을 초과하면 후속 출력 콘텐츠가 이전 논리와 일치하지 않습니다.
ChatGPT는 4000개 토큰(약 3000단어)의 입력만 지원할 수 있습니다. 새로 출시된 GPT-4도 최대 32000개의 토큰 창만 지원합니다. 입력 시퀀스의 길이를 계속 늘리면 계산 복잡도가 높아집니다. 이차 성장.
최근 DeepPavlov, AIRI 및 London Institute of Mathematical Sciences의 연구원들은 RMT(Recurrent Memory Transformer)를 사용하여 높은 메모리 검색을 유지하면서 BERT의 유효 컨텍스트 길이를 "전례 없는 200만 토큰"으로 늘리는 기술 보고서를 발표했습니다. 정확성.
문서 링크: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
이 방법은 로컬 및 전역 정보를 저장 및 처리할 수 있으며 루프를 사용하여 입력 시퀀스의 세그먼트 간에 정보가 흐르도록 할 수 있습니다.
실험 섹션에서는 자연어 이해 및 생성 작업에서 장기적인 종속성 처리를 향상하여 메모리 집약적인 애플리케이션에 대한 대규모 컨텍스트 처리를 가능하게 하는 놀라운 잠재력을 가진 이 접근 방식의 효율성을 보여줍니다.
그러나 세상에 공짜 점심은 없습니다. RMT는 메모리 소비를 늘리지 않고 거의 무한한 시퀀스 길이로 확장할 수 있지만 RNN에는 여전히 메모리 감소 문제가 있으며 추론 시간이 더 길어집니다.

그러나 일부 네티즌들이 해결책을 제안했는데, 장기 기억에는 RMT를 사용하고 단기 기억에는 Large context를 사용하고 밤/유지 보수 중에 모델 훈련을 수행하는 것입니다.
Recurrent Memory Transformer
팀은 2022년에 RMT(Recurrent Memory Transformer) 모델을 제안했습니다. 입력 또는 출력 시퀀스에 특수 메모리 토큰을 추가한 후 모델을 학습시켜 메모리 연산 및 시퀀스 표현 처리를 제어하는 방식입니다. 원래 Transformer 모델을 변경하지 않고도 새로운 메모리 메커니즘을 구현할 수 있습니다.

논문 링크: https://arxiv.org/abs/2207.06881
출판 컨퍼런스: NeurIPS 2022
Transformer-XL에 비해 RMT는 메모리가 덜 필요하고 더 긴 시퀀스의 작업을 처리할 수 있습니다.
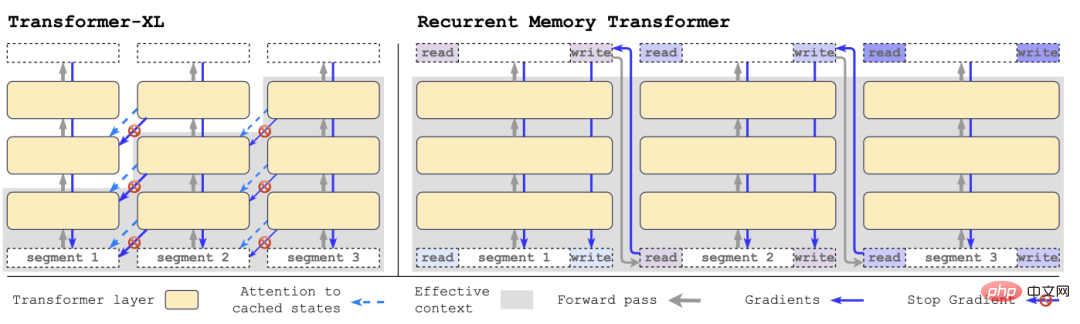
구체적으로 RMT는 m개의 실수 값을 갖는 학습 가능한 벡터로 구성됩니다. 너무 긴 입력 시퀀스는 여러 세그먼트로 나누어집니다. 메모리 벡터는 첫 번째 세그먼트 임베딩으로 사전 설정되어 세그먼트 토큰과 함께 처리됩니다. .
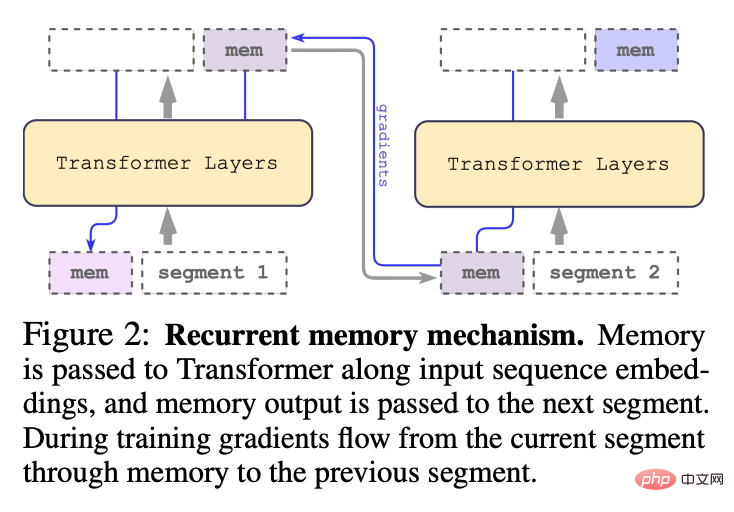
2022년에 제안된 원래 RMT 모델과 달리 BERT와 같은 순수 인코더 모델의 경우 메모리는 세그먼트 시작 부분에 한 번만 추가되며 디코딩 모델은 메모리를 읽기 부분과 쓰기 부분으로 나눕니다.
각 시간 단계와 세그먼트에서 다음과 같이 루프합니다. 여기서 N은 Transformer의 레이어 수, t는 시간 단계, H는 세그먼트입니다
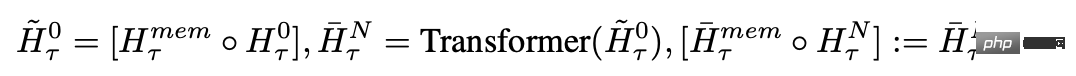
입력 시퀀스의 세그먼트를 순서대로 처리한 후, 재귀적 연결을 달성하기 위해 연구원들은 현재 세그먼트의 메모리 토큰 출력을 다음 세그먼트의 입력으로 전달합니다.
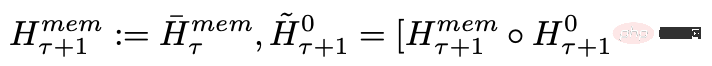
RMT의 메모리와 루프는 전역 메모리 토큰에만 기반을 두고 있습니다. 백본 Transformer 모델을 변경하지 않고 유지하여 RMT 메모리 향상 기능이 모든 Transformer 모델과 호환되도록 합니다.
계산 효율성
공식에 따라 다양한 크기와 시퀀스 길이의 RMT 및 Transformer 모델에 필요한 FLOP를 추정할 수 있습니다.
어휘 크기, 레이어 수, 은닉 크기, 중간 은닉 크기 및 매개변수 구성에 대한 연구 우리는 OPT 모델의 구성을 따르고 RMT 주기의 영향을 고려하여 순방향 전달 후 FLOP 수를 계산했습니다.
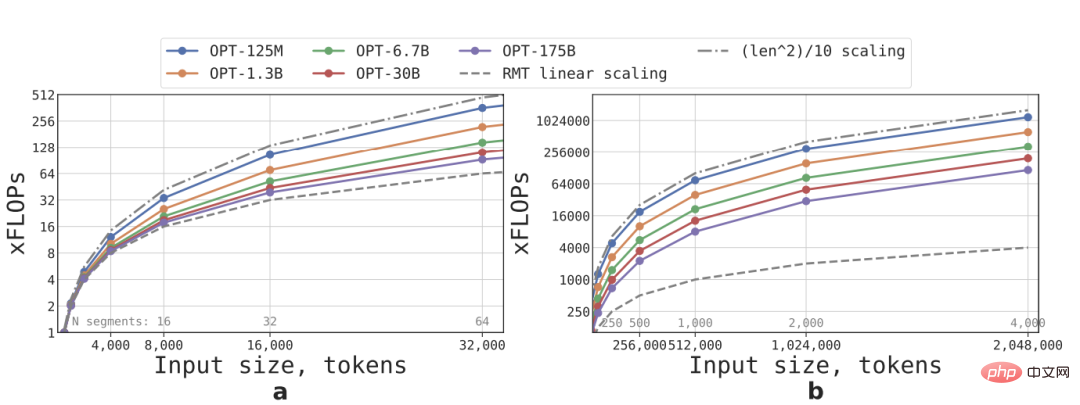
선형 확장은 입력 시퀀스를 여러 세그먼트로 나누고 세그먼트 경계 내에서만 모든 주의 행렬을 계산함으로써 달성됩니다. 결과는 세그먼트 길이가 고정되면 RMT의 추론 속도가 더 좋아진다는 것을 알 수 있습니다. 모든 모델 크기에 대해 모두 선형으로 성장합니다.
FFN 레이어의 계산량이 많기 때문에 더 큰 Transformer 모델은 시퀀스 길이에 비해 2차 성장 속도가 느린 경향이 있습니다. 그러나 길이가 32,000보다 큰 매우 긴 시퀀스에서는 FLOP가 2차 성장 상태로 돌아갑니다. .
2개 이상의 세그먼트(이 연구에서는 512개보다 큼)가 있는 시퀀스의 경우 RMT는 비순환 모델보다 FLOP가 낮습니다. 작은 모델에서는 FLOP의 효율성이 최대 295배 증가할 수 있습니다. OPT-175B와 같은 성능은 29배 향상될 수 있습니다.
기억 작업
기억 능력을 테스트하기 위해 연구원들은 모델이 간단한 사실과 기본 추론을 기억해야 하는 합성 데이터세트를 구축했습니다.
과제 입력은 하나 이상의 사실과 이 모든 사실로만 답할 수 있는 질문으로 구성됩니다.
작업의 난이도를 높이기 위해 질문이나 답변과 관련이 없는 자연어 텍스트도 작업에 추가됩니다. 이러한 텍스트는 노이즈로 간주될 수 있으므로 실제로 모델의 작업은 사실과 사실을 분리하는 것입니다. 관련 없는 텍스트를 선택하고 사실 텍스트를 사용하여 질문에 답하세요.

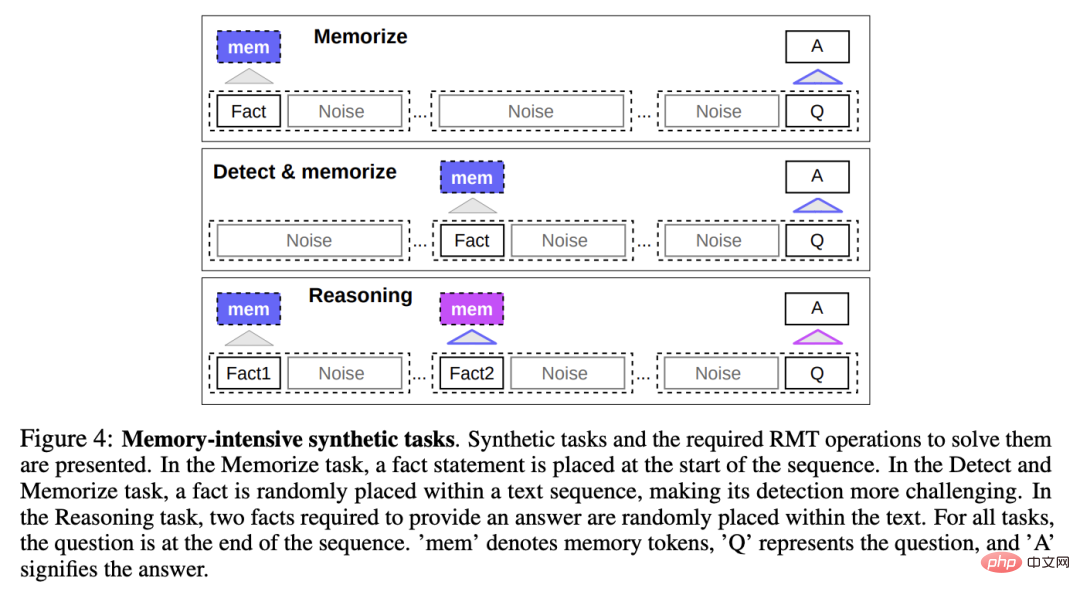
사실 메모리
장기간 메모리에 정보를 쓰고 저장하는 RMT의 능력을 테스트합니다. 가장 간단한 경우 사실은 입력의 시작 부분에 있고 질문은 모델이 모든 입력을 한 번에 받아들일 수 없을 때까지 질문과 답변 사이에 관련 없는 텍스트의 양을 점차적으로 늘립니다.

사실 탐지 및 메모리
사실 탐지는 사실을 입력의 임의 위치로 이동하여 작업의 난이도를 높이고, 모델이 먼저 관련 없는 텍스트와 사실을 구별하여 메모리에 기록하도록 요구합니다. 그럼 마지막에 질문에 대답해 보세요.
기억된 사실에 기초한 추론
기억의 또 다른 중요한 작동은 기억된 사실과 현재의 맥락을 활용하여 추론하는 것입니다.
이 기능을 평가하기 위해 연구원들은 두 가지 사실이 생성되어 입력 시퀀스에 무작위로 배치되는 더 복잡한 작업을 도입했습니다. 올바른 사실로 질문에 대답하려면 시퀀스 끝에 묻는 질문을 선택해야 합니다.

실험 결과
연구원들은 모든 실험에서 HuggingFace Transformers의 사전 훈련된 Bert 기반 케이스 모델을 RMT의 백본으로 사용했으며 모든 모델은 메모리 크기 10으로 향상되었습니다.
4~8개의 NVIDIA 1080Ti GPU에서 훈련하고 평가하세요. 더 긴 시퀀스의 경우 단일 40GB NVIDIA A100으로 전환하여 평가를 가속화하세요.
Curriculum Learning
연구원들은 교육 일정을 사용하면 솔루션의 정확성과 안정성이 크게 향상될 수 있음을 관찰했습니다.
훈련이 수렴된 후 세그먼트를 추가하여 작업 길이를 늘리고 이상적인 입력 길이에 도달할 때까지 과정 학습 과정을 계속하세요.
단일 세그먼트에 맞는 시퀀스로 실험을 시작하세요. BERT의 특수 토큰 3개와 메모리 자리 표시자 10개가 모델 입력에서 유지되어 총 크기가 512가 되므로 실제 세그먼트 크기는 499입니다.
짧은 작업을 훈련한 후 RMT는 더 적은 훈련 단계를 사용하여 완벽한 솔루션으로 수렴하기 때문에 긴 작업을 해결하기가 더 쉽다는 것을 알 수 있습니다.
외삽 능력
다양한 시퀀스 길이에 대한 RMT의 일반화 능력을 관찰하기 위해 연구원들은 더 긴 길이의 작업을 해결하기 위해 다양한 수의 세그먼트에 대해 훈련된 모델을 평가했습니다.
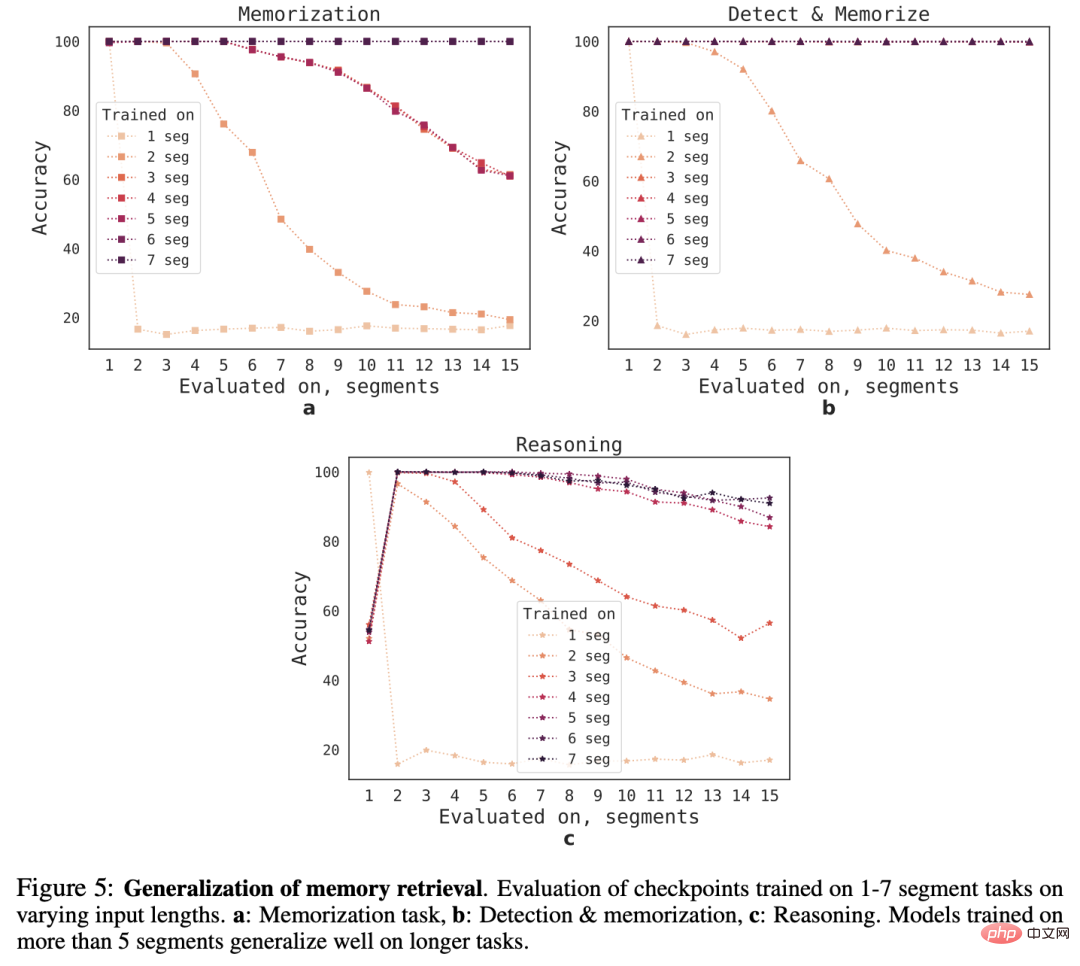
모델이 짧은 작업에서는 잘 작동하는 경우가 많지만 긴 시퀀스에서 모델을 훈련한 후에는 단일 세그먼트 추론 작업을 처리하기가 어려워집니다.
가능한 설명은 작업 크기가 한 세그먼트를 초과하기 때문에 모델이 첫 번째 세그먼트에서 문제 예측을 중단하여 결과적으로 품질이 저하된다는 것입니다.
흥미롭게도 훈련 세그먼트 수가 증가함에 따라 RMT의 더 긴 시퀀스에 대한 일반화 능력도 나타납니다. 5개 이상의 세그먼트를 훈련한 후 RMT는 작업을 거의 두 배 더 오래 수행할 수 있습니다. 완벽한 일반화.
일반화의 한계를 테스트하기 위해 연구원들은 검증 작업의 크기를 4096개 세그먼트(예: 2,043,904개 토큰)로 늘렸습니다.
RMT는 "감지 및 기억" 작업이 가장 간단하고 추론 작업이 가장 복잡한 긴 시퀀스에서 놀라울 정도로 잘 유지됩니다.
참조: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
위 내용은 ChatGPT 기억상실증을 완전히 해결해보세요! Transformer 입력 제한 돌파: 200만 개의 유효 토큰을 지원하는 것으로 측정됨의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!