
Python Vaex가 100G 대용량 데이터 볼륨을 빠르게 분석하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-13 08:34:051403검색
빅데이터 처리에 있어 판다의 한계
요즘 데이터 사이언스 대회에서 제공하는 데이터의 양은 수십 기가바이트에서 수백 기가바이트까지 늘어나고 있으며, 이를 통해 기계 성능과 데이터 처리 능력을 테스트한다.
Python의 Pandas는 일반적으로 사용되는 데이터 처리 도구입니다. 더 큰 데이터 세트(수천만 행)를 처리할 수 있지만 데이터 양이 수십억 또는 수십억 행 수준에 도달하면 Pandas가 약간 처리할 수 없습니다. 매우 느리다고 할 수 있습니다.
컴퓨터 메모리 등 성능 요인도 있지만 Pandas 자체의 데이터 처리 메커니즘(메모리에 의존)으로 인해 빅데이터 처리 능력도 제한됩니다.
물론 팬더는 청크를 통해 데이터를 일괄적으로 읽을 수 있지만 단점은 데이터 처리가 더 복잡하고 각 분석 단계에서 메모리와 시간이 소모된다는 것입니다.
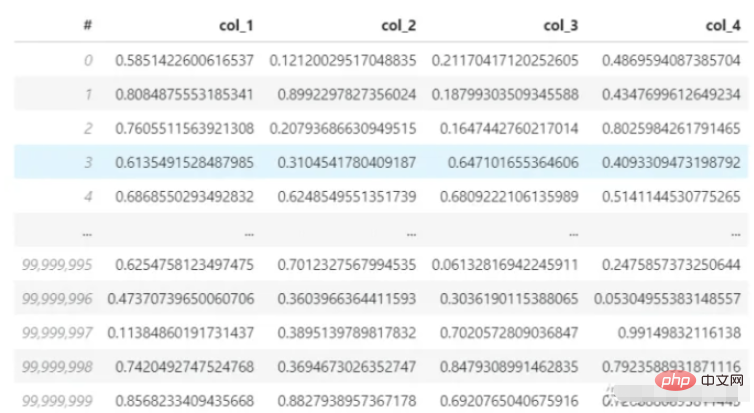
다음으로, pandas를 사용하여 3.7G 데이터 세트(hdf5 형식)를 읽고 데이터 세트에는 4개의 열과 1억 개의 행이 있으며 첫 번째 행의 평균을 계산합니다. 내 컴퓨터의 CPU는 i7-8550U이고 메모리는 8G입니다. 이 로딩 및 계산 프로세스가 얼마나 걸리는지 살펴보겠습니다.
데이터 세트:
판다를 사용하여 읽고 계산:
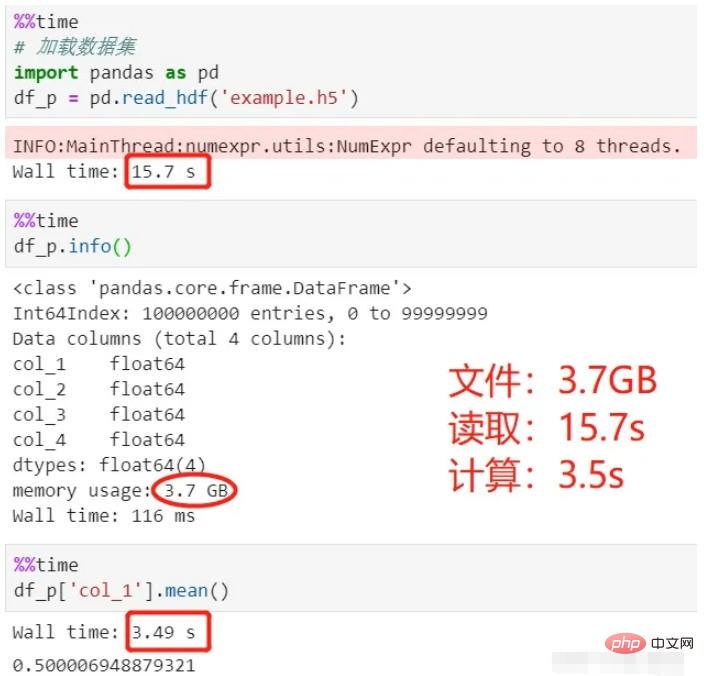
위 프로세스를 보면 데이터를 로드하는 데 15초, 평균을 계산하는 데 3.5초가 소요되어 총 18.5초가 소요됩니다. .
여기서 사용된 hdf5 파일은 csv에 비해 대용량 데이터 저장에 더 적합하고, 압축률이 높으며, 읽고 쓰는 속도가 더 빠른 파일 저장 형식입니다.
오늘의 주인공인 바엑스로 바꿔서 같은 데이터를 읽고 같은 평균 계산을 하면 얼마나 걸릴까요?
vaex를 사용하여 읽고 계산합니다.
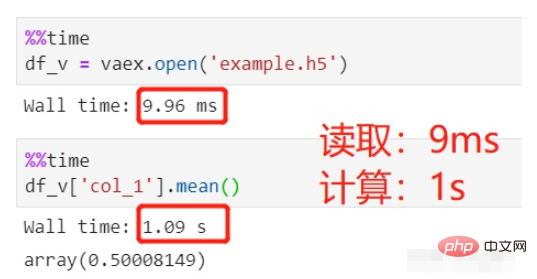
파일을 읽는 데 9ms가 걸렸는데 이는 무시할 수 있는 수준이며 평균 계산에는 1초, 총 1초가 걸렸습니다.
1억 행이 포함된 동일한 HDFS 데이터 세트를 읽습니다. 왜 pandas는 10초 이상 걸리는 반면 vaex는 0에 가깝습니까?
이는 주로 Pandas가 데이터를 메모리로 읽어온 다음 이를 처리 및 계산에 사용하기 때문입니다. Vaex는 실제로 데이터를 메모리로 읽는 대신 데이터를 메모리 매핑만 합니다. 이는 Spark의 지연 로딩과 동일하며 선언될 때가 아닙니다.
그래서 아무리 큰 데이터를 로드하더라도 10GB, 100GB... vaex에서는 즉시 처리할 수 있습니다. 문제는 vaex의 지연 로딩이 HDF5, Apache Arrow, Parquet, FITS 및 기타 파일만 지원하지만 텍스트 파일은 메모리 매핑될 수 없기 때문에 csv와 같은 텍스트 파일은 지원하지 않는다는 것입니다.
어떤 친구들은 메모리 매핑을 잘 이해하지 못할 수도 있습니다. 자세한 내용은 직접 탐색해 보아야 합니다.
메모리 매핑은 하드 디스크의 파일 위치와 영역을 말합니다. 프로세스 논리 주소 공간에서 동일한 크기 사이의 일대일 대응. 이 대응은 순전히 논리적 개념이며 물리적으로 존재하지 않습니다. 그 이유는 프로세스 자체의 논리적 주소 공간이 존재하지 않기 때문입니다. 메모리 매핑 과정에서는 실제 데이터 복사가 이루어지지 않으며, 파일이 메모리에 로드되는 것이 아니라, 구체적으로 코드의 경우 해당 데이터 구조(struct address_space)가 설정됩니다. 그리고 초기화되었습니다.
vaex란 무엇입니까
앞서 vaex와 pandas의 빅데이터 처리 속도를 비교해 보았는데, vaex는 분명한 장점이 있습니다. 능력이 뛰어나고 판다만큼 인지도가 높지는 않지만, vaex는 아직 업계에 막 등장한 신인입니다.
vaex는 Python 기반의 데이터 처리를 위한 타사 라이브러리이기도 하며 pip를 사용하여 설치할 수 있습니다.
공식 웹사이트의 vaex 소개는 세 가지로 요약될 수 있습니다:
vaex는 팬더와 유사한 데이터 처리 및 표시를 위한 데이터 테이블 도구입니다.
vaex는 메모리 매핑 및 지연 계산을 채택합니다. 메모리를 차지하지 않으며 빅 데이터 처리에 적합합니다.
vaex는 수백억 개의 데이터 세트에 대해 2단계 통계 분석 및 시각적 표시를 수행할 수 있습니다.
vaex의 장점은 다음과 같습니다.
성능: 프로세스 대용량 데이터, 109행/초 ;
Lazy: 빠른 계산, 메모리 사용량 없음
제로 메모리 복사: 필터링/변형/계산 시 메모리 복사 없음, 필요할 때 스트리밍
시각화: 이내; 시각적 구성 요소 포함
API: 풍부한 데이터 처리 및 계산 기능을 갖춘 팬더와 유사
Interactive: Jupyter 노트북과 함께 사용, 유연한 대화형 시각화
pip 사용 또는 다음으로 설치 conda:
 Read data
Read data
vaex는 read 메서드를 사용하여 hdf5, csv, parquet 및 기타 파일 읽기를 지원합니다. hdf5는 느리게 읽을 수 있지만 csv는 메모리로만 읽을 수 있습니다.
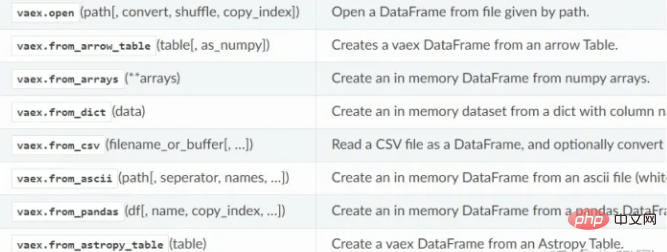
 vaex 데이터 읽기 기능:
vaex 데이터 읽기 기능:
데이터 처리
때로는 데이터에 대해 다양한 변환, 스크리닝, 계산 등을 수행해야 할 때도 있습니다. Pandas 처리의 각 단계는 메모리를 소비하고 시간이 많이 걸립니다. 체인 처리를 사용하지 않는 한 프로세스가 매우 불분명합니다.
vaex는 프로세스 전반에 걸쳐 메모리를 사용하지 않습니다. 그 처리는 논리적 표현인 표현식만 생성하기 때문에 최종 결과 생성 단계에서만 실행됩니다. 또한 전체 프로세스의 데이터가 스트리밍되므로 메모리 백로그가 없습니다.
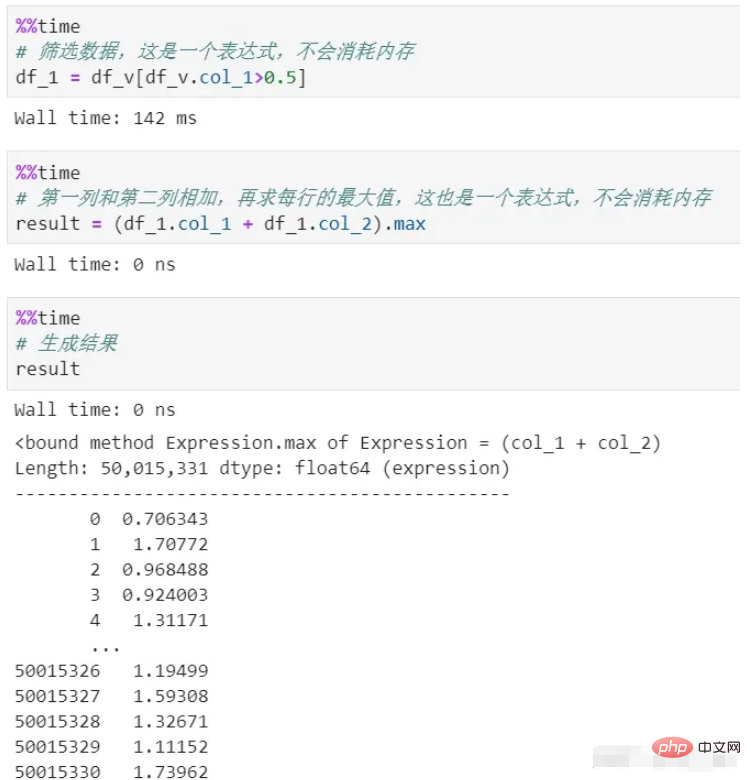
필터링과 계산의 두 가지 프로세스가 있음을 알 수 있으며 둘 다 메모리를 복사하지 않습니다. 여기서는 게으른 메커니즘인 지연 계산이 사용됩니다. 실제로 각 프로세스를 계산해 보면 메모리 소모는 말할 것도 없고 시간 비용만 해도 엄청날 것입니다.
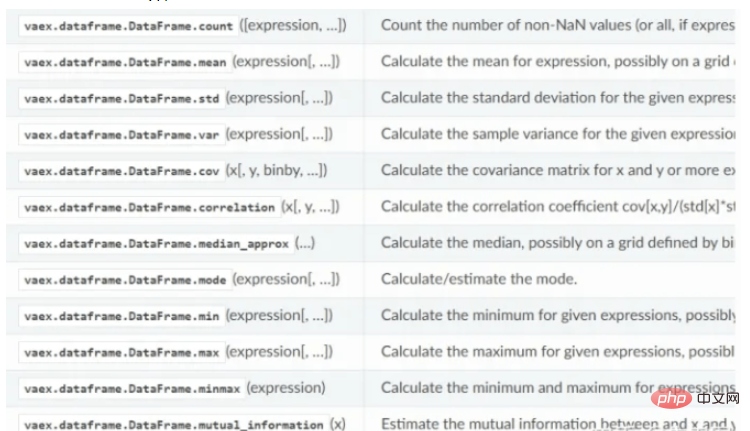
vaex의 통계 계산 기능:
시각적 표시
vaex는 또한 수백억 개의 데이터 세트가 있어도 빠른 시각적 표시를 수행할 수 있으며 여전히 몇 초 안에 그래프를 생성할 수 있습니다.
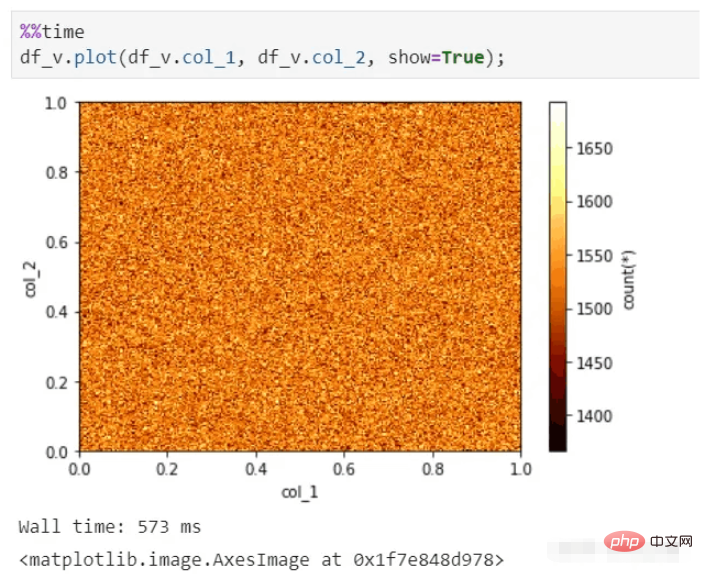
vaex 시각화 기능:

결론
vaex는 다소 Spark와 Pandas의 조합과 유사하며 데이터 양이 많을수록 장점이 더 많이 반영될 수 있습니다. 하드 드라이브에 필요한 만큼의 데이터를 저장할 수 있으면 데이터를 신속하게 분석할 수 있습니다.
vaex는 점점 더 많은 pandas 기능을 통합하면서 여전히 빠르게 발전하고 있으며 github의 스타 번호는 5,000개이며 성장 잠재력은 엄청납니다.
첨부 파일: hdf5 데이터 세트 생성 코드(4열 및 1억 행의 데이터)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
여기서는 pandas를 사용하여 hdf5를 직접 생성하지 마세요. 형식이 vaex와 호환되지 않으므로 주의하세요.
위 내용은 Python Vaex가 100G 대용량 데이터 볼륨을 빠르게 분석하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!