
AI가 휴대폰으로 그림 그리기 12초 만에 완성! Google, 확산 모델 추론을 가속화하는 새로운 방법 제안

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-12 10:43:051202검색
Stable Diffusion을 사용하여 휴대폰의 컴퓨팅 성능만을 사용하여 이미지를 생성하는 데 12초밖에 걸리지 않습니다.
그리고 20번의 반복을 마친 종류입니다.

현재 확산 모델은 기본적으로 10억 개의 매개변수를 초과한다는 점을 알아야 합니다. 그림을 빠르게 생성하려면 클라우드 컴퓨팅이나 충분히 강력한 로컬 하드웨어를 사용해야 합니다.
대형 모델 애플리케이션이 점차 대중화되면서 개인용 컴퓨터와 휴대폰에서 대형 모델을 구동하는 것이 앞으로 새로운 트렌드가 될 가능성이 높습니다.
그 결과, Google 연구원들은 Speed is all you need라는 새로운 결과를 내놓았습니다. GPU 최적화를 통해 기기에서 대규모 확산 모델의 추론 속도를 가속화하는 것입니다.

3단계 최적화 및 가속
이 방법은 Stable Diffusion에 최적화되어 있지만 다른 확산 모델에도 적용할 수 있습니다. 이 작업은 텍스트에서 이미지를 생성하는 것입니다.
특정 최적화는 세 부분으로 나눌 수 있습니다:
- 특수 커널 설계
- Attention 모델의 효율성 향상
- Winograd 컨볼루션 가속
그룹 정규화 및 GELU 활성화 기능.
그룹 정규화는 UNet 아키텍처 전반에 걸쳐 구현됩니다. 이 정규화는 기능 맵의 채널을 더 작은 그룹으로 나누고 각 그룹을 독립적으로 정규화하여 그룹을 정규화하는 방식으로 작동합니다. 네트워크 아키텍처.
연구원들은 중간 텐서 없이 단일 GPU 명령으로 모든 커널을 실행할 수 있는 GPU 셰이더 형태의 고유한 커널을 설계했습니다.
GELU 활성화 함수에는 페널티, 가우스 오류 함수 등과 같은 수많은 수치 계산이 포함되어 있습니다.
전용 셰이더는 이러한 수치 계산과 이에 수반되는 나눗셈 및 곱셈 연산을 통합하는 데 사용되므로 이러한 계산을 간단한 그리기 호출에 배치할 수 있습니다.
Draw 호출은 CPU가 이미지 프로그래밍 인터페이스를 호출하고 GPU에 렌더링을 수행하도록 지시하는 작업입니다.
다음으로 Attention 모델의 효율성 향상과 관련하여 논문에서는 두 가지 최적화 방법을 소개합니다.
하나는 소프트맥스 기능을 부분적으로 융합하는 것입니다.
대형 행렬 A에 대해 전체 소프트맥스 계산을 수행하지 않기 위해 연구에서는 L 및 S 벡터를 계산하여 계산을 줄이기 위한 GPU 셰이더를 설계하여 궁극적으로 N×2 크기의 텐서를 생성했습니다. 그런 다음 소프트맥스 계산과 행렬 V의 행렬 곱셈이 병합됩니다.
이 접근 방식은 중간 프로그램의 메모리 공간과 전체 대기 시간을 크게 줄입니다.
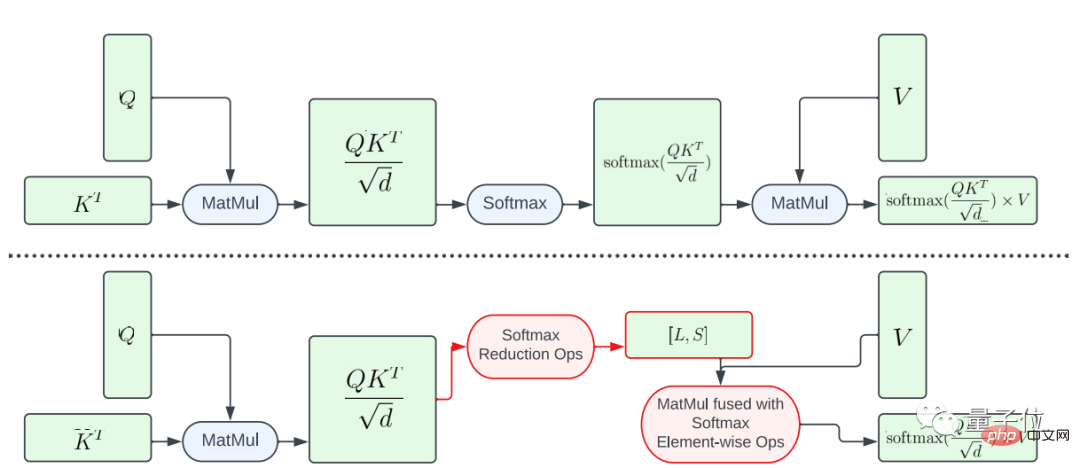
결과 텐서의 요소 수가 입력 텐서 A의 요소 수보다 훨씬 작기 때문에 A에서 L 및 S로의 계산 매핑 병렬성이 제한된다는 점을 강조해야 합니다.
병렬성을 높이고 지연 시간을 더욱 줄이기 위해 본 연구에서는 A의 요소를 블록으로 구성하고 축소 작업을 여러 부분으로 나누었습니다.
그런 다음 각 블록에 대해 계산이 수행된 다음 최종 결과로 축소됩니다.
신중하게 설계된 스레딩 및 메모리 캐시 관리를 활용하면 단일 GPU 명령을 사용하여 여러 부분에서 지연 시간을 줄일 수 있습니다.
또 다른 최적화 방법은 FlashAttention입니다.
지난해 인기를 끌었던 IO 인식 정밀 주의 알고리즘에는 두 가지 구체적인 가속 기술이 있습니다. 즉, 블록 내 증분 계산, 즉 역방향 전달의 주의 재계산과 모든 주의 작업을 CUDA 커널에 통합하는 것입니다. . 가운데.
표준 Attention과 비교하여 이 방법은 HBM(고대역폭 메모리) 액세스를 줄이고 전반적인 효율성을 향상시킬 수 있습니다.
그러나 FlashAttention 코어는 등록 집약적이므로 팀에서는 이 최적화 방법을 선택적으로 사용합니다.
그들은 주의 매트릭스 d=40인 Adreno GPU 및 Apple GPU에서 FlashAttention을 사용하고 다른 경우에는 부분 융합 소프트맥스 기능을 사용합니다.
세 번째 부분은 Winograd 컨볼루션 가속입니다.
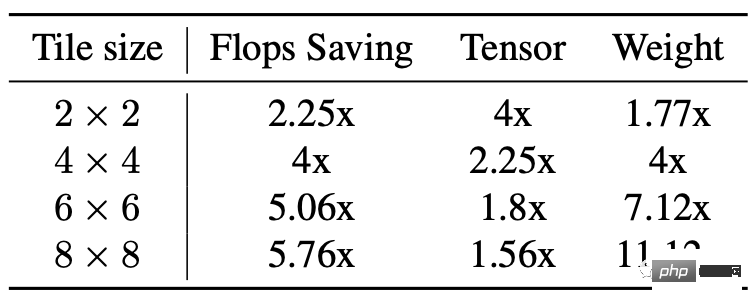
단순히 덧셈 계산을 더 많이 사용하여 곱셈 계산을 줄여 계산량을 줄이는 것이 원칙입니다.
하지만 단점도 분명합니다. 특히 타일이 상대적으로 큰 경우 비디오 메모리 소비가 늘어나고 수치 오류가 발생한다는 점입니다.
Stable Diffusion의 백본은 3×3 컨볼루셔널 레이어에 크게 의존하며, 특히 이미지 디코더에서는 레이어의 90%가 3×3 컨볼루셔널 레이어로 구성됩니다.
분석 결과 연구원들은 4×4 타일을 사용하는 것이 모델 계산 효율성과 비디오 메모리 활용도 간의 균형이 가장 잘 맞는다는 사실을 발견했습니다.
실험 결과
개선 효과를 평가하기 위해 연구진은 먼저 휴대폰에서 벤치마크 테스트를 진행했습니다.
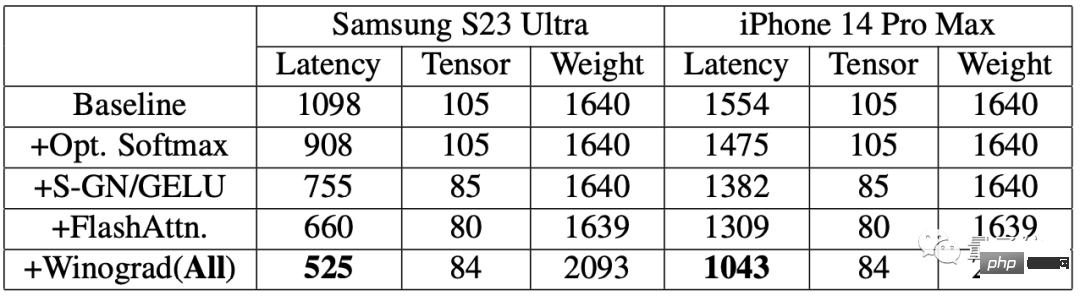
가속 알고리즘을 사용한 후 두 휴대폰의 이미지 생성 속도가 크게 향상되었다는 결과가 나왔습니다.
그 중 Samsung S23 Ultra의 지연 시간은 52.2% 감소했으며, iPhone 14 Pro Max의 지연 시간은 32.9% 감소했습니다.
Samsung S23 Ultra에서 텍스트 전체에서 512×512 픽셀 이미지를 생성합니다. 20번의 반복을 통해 12초도 채 걸리지 않습니다.
논문 주소: https://www.php.cn/link/ba825ea8a40c385c33407ebe566fa1bc
위 내용은 AI가 휴대폰으로 그림 그리기 12초 만에 완성! Google, 확산 모델 추론을 가속화하는 새로운 방법 제안의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!