
k8s 서비스 springboot 프로젝트 애플리케이션을 업그레이드할 때 502 오류를 해결하는 방법

- 王林앞으로
- 2023-05-11 22:28:042493검색
작은 단계와 빠른 반복의 개발 모델이 점점 더 많은 인터넷 회사에서 인식되고 채택됨에 따라 애플리케이션 변경 및 업그레이드 빈도가 점점 더 빈번해지고 있습니다. 다양한 업그레이드 요구 사항에 대처하고 업그레이드 프로세스가 원활하게 진행되도록 하기 위해 일련의 배포 및 릴리스 모델이 탄생했습니다.
릴리스 중지 - 이전 버전의 애플리케이션 인스턴스를 완전히 중지한 다음 새 버전을 릴리스합니다. 이번 출시 모델은 주로 새 버전과 이전 버전 간의 비호환성 및 공존 불가능 문제를 해결하기 위한 것입니다. 단점은 일정 기간 동안 서비스를 완전히 사용할 수 없다는 것입니다.
블루-그린 릴리스 - 동일한 수의 신규 및 기존 버전 애플리케이션 인스턴스를 동시에 온라인으로 배포합니다. 새 버전이 테스트를 통과하면 트래픽이 즉시 새 서비스 인스턴스로 전환됩니다. 이 게시 모델은 가동 중지 시간 게시 시 전체 서비스를 사용할 수 없는 문제를 해결하지만 상대적으로 많은 리소스를 소비하게 됩니다.
롤링 릴리스 - 애플리케이션 인스턴스를 일괄적으로 점진적으로 교체합니다. 이 릴리스 모드는 서비스를 중단하지 않으며 너무 많은 추가 리소스를 소비하지 않습니다. 그러나 이전 버전 인스턴스와 새 버전 인스턴스가 동시에 온라인 상태이므로 동일한 클라이언트의 요청이 이전 버전과 새 버전 간에 전환될 수 있습니다. 호환성 문제.
Canary 릴리스 - 트래픽을 이전 버전에서 새 버전으로 점차 전환합니다. 일정 시간 동안 관찰한 결과 문제가 발견되지 않으면 새 버전의 트래픽은 더욱 확대되고 이전 버전의 트래픽은 감소됩니다.
A/B 테스트 - 두 개 이상의 버전을 동시에 출시하고, 이러한 버전에 대한 사용자 피드백을 수집하고, 공식 채택을 위한 최고의 버전을 분석 및 평가합니다.
K8s 애플리케이션 업그레이드
k8s에서 Pod는 배포 및 업그레이드의 기본 단위입니다. 일반적으로 Pod는 애플리케이션 인스턴스를 의미하며, Pod는 배포, StatefulSet, DaemonSet, Job 등의 형태로 배포 및 실행됩니다. 다음은 이러한 배포 형태의 Pod 업그레이드 방법을 설명합니다.
Deployment
배포는 포드의 가장 일반적인 배포 형식입니다. 여기서는 스프링 부트 기반의 Java 애플리케이션을 예로 들어보겠습니다. 이 애플리케이션은 실제 애플리케이션을 기반으로 추상화된 간단한 버전입니다.
애플리케이션이 시작된 후 구성을 로드하는 데 일정 시간이 걸립니다. 외부 세계에 서비스를 제공할 수 없습니다.
어플리케이션 실행이 가능하다고 해서 정상적으로 서비스를 제공할 수 있는 것은 아닙니다.
서비스를 제공할 수 없는 경우 애플리케이션이 자동으로 종료되지 않을 수 있습니다.
업그레이드 프로세스 중에는 오프라인 상태가 되려는 애플리케이션 인스턴스가 새로운 요청을 받지 않고 현재 요청을 처리할 충분한 시간이 있는지 확인해야 합니다.
매개변수 구성
위의 특성을 가진 애플리케이션이 다운타임과 생산 중단 없는 업그레이드를 달성하려면 배포에서 관련 매개변수를 신중하게 구성해야 합니다. 여기서 업그레이드와 관련된 구성은 다음과 같다. (전체 구성은 spring-boot-probes-v1.yaml 참고)
kind: Deployment
...
spec:
replicas: 8
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
minReadySeconds: 120
...
template:
...
spec:
containers:
- name: spring-boot-probes
image: registry.cn-hangzhou.aliyuncs.com/log-service/spring-boot-probes:1.0.0
ports:
- containerPort: 8080
terminationGracePeriodSeconds: 60
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
failureThreshold: 1
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
failureThreshold: 3
...전략 구성
전략을 통해 포드 교체 전략을 구성할 수 있습니다. 주요 매개변수는 다음과 같습니다.
.spec.strategy.type- 포드를 교체할 전략 유형을 지정하는 데 사용됩니다. 이 매개변수는 Recreate 또는 RollingUpdate 값을 사용할 수 있으며 기본값은 RollingUpdate입니다..spec.strategy.type- 用于指定替换 pod 的策略类型。该参数可取值 Recreate 或 RollingUpdate,默认为 RollingUpdate。Recreate - K8s 会先删掉全部原有 pod 再创建新的 pod。该方式适用于新老版本互不兼容、无法共存的场景。但由于该方式会造成一段时间内服务完全不可用,在上述场景之外须慎用。
RollingUpdate - K8s 会将 pod 分批次逐步替换掉,可用来实现服务热升级。
.spec.strategy.rollingUpdate.maxSurge- 指定在滚动更新过程中最多可创建多少个额外的 pod,可以是数字或百分比。该值设置得越大、升级速度越快,但会消耗更多的系统资源。-
.spec.strategy.rollingUpdate.maxUnavailable
- RollingUpdate - K8s는 서비스의 핫 업그레이드를 구현하는 데 사용할 수 있는 포드를 일괄적으로 점진적으로 교체할 예정입니다.
.spec.strategy.rollingUpdate.maxSurge- 롤링 업데이트 중에 생성될 수 있는 추가 Pod의 최대 수를 숫자 또는 백분율로 지정합니다. 값을 크게 설정할수록 업그레이드 속도는 빨라지지만 시스템 리소스를 더 많이 소모하게 됩니다.
.spec.strategy.rollingUpdate.maxUnavailable - 롤링 업데이트 프로세스 중에 사용할 수 없도록 허용된 최대 Pod 수를 지정합니다. 숫자 또는 백분율일 수 있습니다. 값을 크게 설정할수록 업그레이드 속도는 빨라지지만 서비스가 불안정해집니다.
maxSurge 및 maxUnavailable을 조정하면 다양한 시나리오의 업그레이드 요구 사항을 충족할 수 있습니다.
🎜🎜🎜시스템 가용성과 안정성을 보장하면서 최대한 빨리 업그레이드하려면 maxUnavailable을 0으로 설정하고 maxSurge에 더 큰 값을 부여할 수 있습니다. 🎜🎜🎜🎜시스템 리소스가 부족하고 Pod 로드가 낮은 경우 업그레이드 속도를 높이기 위해 maxSurge를 0으로 설정하고 maxUnavailable에 더 큰 값을 지정할 수 있습니다. maxSurge가 0이고 maxUnavailable이 DESIRED인 경우 전체 서비스를 사용할 수 없게 될 수 있습니다. 이때 RollingUpdate는 종료 릴리스로 저하됩니다. 🎜🎜🎜🎜샘플에서는 maxSurge를 3으로 설정하고 maxUnavailable을 2로 설정하여 안정성, 리소스 소비 및 업그레이드 속도의 균형을 맞추는 절충 솔루션을 선택합니다. 🎜🎜구성 프로브🎜🎜K8s는 다음 두 가지 유형의 프로브를 제공합니다. 🎜ReadinessProbe - 기본적으로 포드의 모든 컨테이너가 시작되면 k8s는 포드가 준비 상태인 것으로 간주하고 트래픽을 포드로 보냅니다. 그러나 일부 애플리케이션은 시작된 후에도 외부 서비스를 제공하기 전에 데이터 또는 구성 파일의 로드를 완료해야 합니다. 따라서 컨테이너가 시작되었는지 여부로 컨테이너가 준비되었는지 판단하는 것은 엄격하지 않습니다. 컨테이너에 대한 준비 상태 프로브를 구성함으로써 k8s는 컨테이너가 준비되었는지 더 정확하게 판단하여 보다 강력한 애플리케이션을 구축할 수 있습니다. K8s는 포드의 모든 컨테이너가 준비 감지를 통과한 경우에만 서비스가 포드로 트래픽을 보낼 수 있도록 허용합니다. 준비 감지가 실패하면 k8s는 포드로의 트래픽 전송을 중지합니다.
LivenessProbe - 기본적으로 k8s는 실행 가능한 컨테이너를 고려합니다. 그러나 문제가 발생하거나 건강에 해로울 때(예: 심각한 교착 상태 발생) 애플리케이션이 자동으로 종료될 수 없는 경우 이러한 판단은 문제가 될 수 있습니다. 컨테이너에 대한 활성 프로브를 구성함으로써 k8s는 컨테이너가 정상적으로 실행되고 있는지 더 정확하게 확인할 수 있습니다. 컨테이너가 활성 감지에 실패하면 kubelet은 컨테이너를 중지하고 다시 시작 정책에 따라 다음 작업을 결정합니다.
프로브 구성은 매우 유연합니다. 사용자는 프로브의 감지 빈도, 감지 성공 임계값, 감지 실패 임계값 등을 지정할 수 있습니다. 각 매개변수의 의미와 구성 방법은 활성 및 준비 프로브 구성 문서를 참조하세요.
샘플은 대상 컨테이너에 대한 준비 상태 프로브와 활성 상태 프로브를 구성합니다.
애플리케이션이 초기화 작업을 완료하는 데 평균 30초가 걸리기 때문에 준비 상태 프로브의initialDelaySeconds는 30으로 설정됩니다.
활성 프로브를 구성할 때 컨테이너가 준비 상태에 도달하는 데 충분한 시간이 있는지 확인해야 합니다. initialDelaySeconds, periodSeconds 및 failureThreshold 매개변수를 너무 작게 설정하면 컨테이너가 준비되기 전에 다시 시작되어 준비 상태에 도달할 수 없게 될 수 있습니다. 샘플의 구성은 컨테이너가 시작 후 80초 이내에 준비되면 다시 시작되지 않도록 보장합니다. 이는 평균 초기화 시간인 30초에 비해 충분한 버퍼입니다.
준비 프로브의 기간(초)은 10으로 설정되고, failureThreshold는 1로 설정됩니다. 이런 식으로 컨테이너가 비정상일 경우 약 10초 후에는 트래픽이 전송되지 않습니다.
활동 프로브의 기간(초)은 20으로 설정되고, failureThreshold는 3으로 설정됩니다. 이런 방식으로 컨테이너가 비정상일 경우 약 60초가 지나도 다시 시작되지 않습니다.
minReadySeconds 구성
기본적으로 새로 생성된 포드가 준비되면 k8s는 포드를 사용할 수 있는 것으로 간주하고 이전 포드를 삭제합니다. 그러나 때로는 새 Pod가 실제로 사용자 요청을 처리할 때 문제가 노출될 수 있으므로 보다 강력한 접근 방식은 이전 Pod를 삭제하기 전에 일정 기간 동안 새 Pod를 관찰하는 것입니다.
minReadySeconds 매개변수는 준비 상태에서 Pod의 관찰 시간을 제어할 수 있습니다. 이 기간 동안 Pod의 컨테이너가 정상적으로 실행될 수 있으면 k8s는 새 Pod를 사용 가능한 것으로 간주하고 이전 Pod를 삭제합니다. 이 매개변수를 구성할 때 신중하게 고려해야 합니다. 너무 작게 설정하면 관찰이 부족할 수 있으며, 너무 크게 설정하면 업그레이드 진행이 느려집니다. 이 예시에서는 minReadySeconds를 120초로 설정합니다. 그러면 준비 상태의 Pod가 전체 활성 감지 주기를 거칠 수 있습니다.
TerminationGracePeriodSeconds 구성
k8s가 포드를 삭제할 준비가 되면 포드의 컨테이너에 TERM 신호를 보내는 동시에 서비스의 끝점 목록에서 포드를 제거합니다. 지정된 시간(기본값 30초) 내에 컨테이너를 종료할 수 없는 경우 k8s는 SIGKILL 신호를 컨테이너에 보내 프로세스를 강제 종료합니다. 자세한 Pod 종료 프로세스는 Pod 종료 문서를 참조하세요.
애플리케이션이 요청을 처리하는 데 최대 40초가 걸리므로 종료되기 전에 서버에 도착한 요청을 처리할 수 있도록 샘플에서는 정상적인 종료 시간을 60초로 설정합니다. 다양한 애플리케이션의 경우 실제 조건에 따라 종료GracePeriodSeconds 값을 조정할 수 있습니다.
업그레이드 동작을 관찰하세요
위 구성을 통해 대상 애플리케이션의 원활한 업그레이드를 보장할 수 있습니다. 배포에서 PodTemplateSpec의 필드를 변경하여 포드 업그레이드를 트리거하고 kubectl get rs -w 명령을 실행하여 업그레이드 동작을 관찰할 수 있습니다. 여기에서 관찰된 이전 버전과 새 버전의 Pod 복사본 수 변화는 다음과 같습니다.
maxSurge 새 Pod를 생성합니다. 이때 총 Pod 수는 허용 상한, 즉 DESIRED + maxSurge에 도달합니다.
새 포드가 준비되거나 사용 가능해질 때까지 기다리지 않고 maxUnavailable 이전 포드의 삭제 프로세스를 즉시 시작합니다. 현재 사용 가능한 Pod 수는 DESIRED - maxUnavailable입니다.
기존 Pod가 완전히 삭제되면 새 Pod가 즉시 추가됩니다.
새 포드가 준비 감지를 통과하고 준비되면 k8s는 트래픽을 포드로 보냅니다. 그러나 지정된 관찰 시간에 도달하지 않았으므로 포드를 사용할 수 없는 것으로 간주됩니다.
관찰 기간 동안 정상적으로 실행 중인 준비된 포드는 사용 가능한 것으로 간주됩니다. 이때 이전 포드의 삭제 프로세스를 다시 시작할 수 있습니다.
모든 이전 포드가 삭제되고 사용 가능한 새 포드가 목표 복제본 수에 도달할 때까지 3, 4, 5단계를 반복합니다.
失败回滚
应用的升级并不总会一帆风顺,在升级过程中或升级完成后都有可能遇到新版本行为不符合预期需要回滚到稳定版本的情况。K8s 会将 PodTemplateSpec 的每一次变更(如果更新模板标签或容器镜像)都记录下来。这样,如果新版本出现问题,就可以根据版本号方便地回滚到稳定版本。回滚 Deployment 的详细操作步骤可参考文档 Rolling Back a Deployment。
StatefulSet
StatefulSet 是针对有状态 pod 常用的部署形式。针对这类 pod,k8s 同样提供了许多参数用于灵活地控制它们的升级行为。好消息是这些参数大部分都和升级 Deployment 中的 pod 相同。这里重点介绍两者存在差异的地方。
策略类型
在 k8s 1.7 及之后的版本中,StatefulSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 StatefulSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.6 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - K8s 会将 StatefulSet 管理的 pod 分批次逐步替换掉。它与 Deployment 中 RollingUpdate 的区别在于 pod 的替换是有序的。例如一个 StatefulSet 中包含 N 个 pod,在部署的时候这些 pod 被分配了从 0 开始单调递增的序号,而在滚动更新时,它们会按逆序依次被替换。
Partition
可以通过参数.spec.updateStrategy.rollingUpdate.partition实现只升级部分 pod 的目的。在配置了 partition 后,只有序号大于或等于 partition 的 pod 才会进行滚动升级,其余 pod 将保持不变。
Partition 的另一个应用是可以通过不断减少 partition 的取值实现金丝雀升级。具体操作方法可参考文档 Rolling Out a Canary。
DaemonSet
DaemonSet 保证在全部(或者一些)k8s 工作节点上运行一个 pod 的副本,常用来运行监控或日志收集程序。对于 DaemonSet 中的 pod,用于控制它们升级行为的参数与 Deployment 几乎一致,只是在策略类型方面略有差异。DaemonSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 DaemonSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.5 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - 其含义和可配参数与 Deployment 的 RollingUpdate 一致。
滚动更新 DaemonSet 的具体操作步骤可参考文档 Perform a Rolling Update on a DaemonSet。
Job
Deployment、StatefulSet、DaemonSet 一般用于部署运行常驻进程,而 Job 中的 pod 在执行完特定任务后就会退出,因此不存在滚动更新的概念。当您更改了一个 Job 中的 PodTemplateSpec 后,需要手动删掉老的 Job 和 pod,并以新的配置重新运行该 job。
总结
K8s 提供的功能可以让大部分应用实现零宕机时间和无生产中断的升级,但也存在一些没有解决的问题,主要包括以下几点:
目前 k8s 原生仅支持停机发布、滚动发布两类部署升级策略。如果应用有蓝绿发布、金丝雀发布、A/B 测试等需求,需要进行二次开发或使用一些第三方工具。
K8s 虽然提供了回滚功能,但回滚操作必须手动完成,无法根据条件自动回滚。
有些应用在扩容或缩容时同样需要分批逐步执行,k8s 还未提供类似的功能。
实例配置:
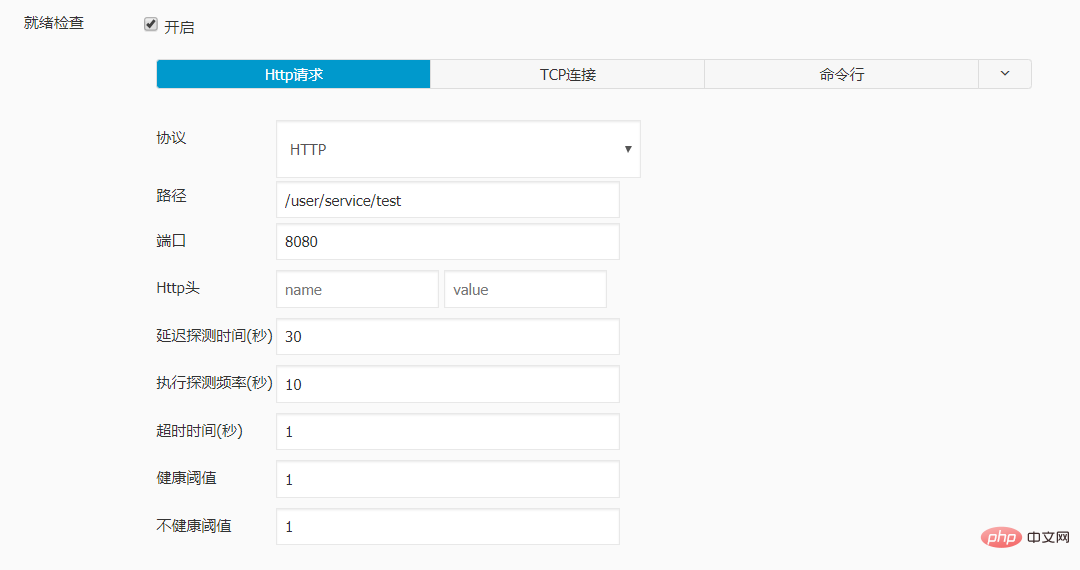
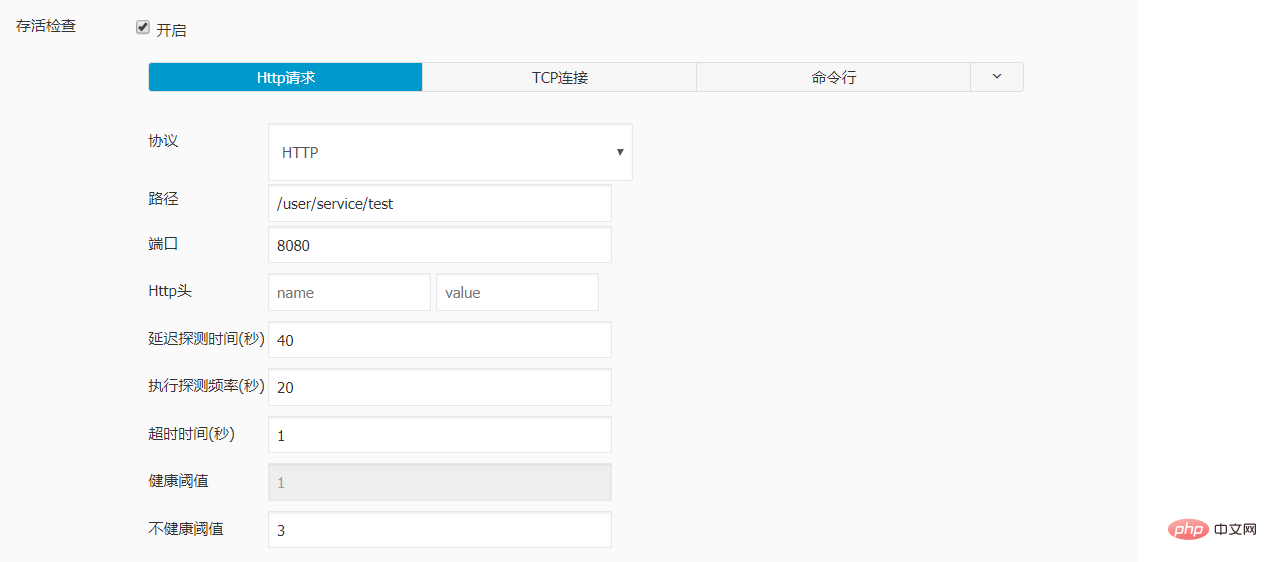
livenessProbe:
failureThreshold: 3
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
name: dataline-dev
ports:
- containerPort: 8080
protocol: TCP
readinessProbe:
failureThreshold: 1
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1经测试 , 再对sprintboot 应用进行更新时, 访问不再出现502的报错。
위 내용은 k8s 서비스 springboot 프로젝트 애플리케이션을 업그레이드할 때 502 오류를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!