


훈련 속도가 17% 향상되었습니다. 네 번째 패러다임 오픈 소스 강화 학습 연구 프레임워크는 단일 및 다중 에이전트 훈련을 지원합니다.

OpenRL은 Fourth Paradigm 강화학습팀에서 개발한 PyTorch 기반 강화학습 연구 프레임워크로 단일 에이전트, 다중 에이전트, 자연어 및 기타 작업의 훈련을 지원합니다. OpenRL은 강화 학습 연구 커뮤니티에 사용하기 쉽고 유연하며 효율적이며 지속 가능하게 확장 가능한 플랫폼을 제공하는 것을 목표로 PyTorch를 기반으로 개발되었습니다. 현재 OpenRL에서 지원하는 기능은 다음과 같습니다.
- 사용하기 쉽고 단일 에이전트 및 다중 에이전트 훈련을 지원하는 공통 인터페이스
- 자연어 작업(예: 대화 작업)에 대한 강화 학습 훈련 지원
- Hugging Face에서 모델 및 데이터 가져오기 지원
- LSTM, GRU, Transformer 및 기타 모델 지원
- 자동 혼합 정밀도 훈련, 반정밀도 정책 네트워크 데이터와 같은 다양한 훈련 가속화 지원 컬렉션 등
- 지원되는 사용자 정의 훈련 모델, 보상 모델, 훈련 데이터 및 환경
- 체육관 환경 지원
- 사전 관찰 공간 지원
- wandb, tensorboardX 및 기타 주류 훈련 시각화 지원 tools
- 두 가지 모드에서 일관된 훈련 효과를 보장하면서 환경 직렬화 및 병렬 훈련을 지원합니다.
- 중국어 및 영어 문서
- 단위 테스트 및 코드 적용 범위 테스트 제공
- Black Code Style 및 유형 검사
현재 OpenRL은 GitHub에서 오픈소스화되었습니다:

프로젝트 주소: https://github.com/OpenRL-Lab/openrl
OpenRL의 첫 경험
OpenRL은 현재 pip를 통해 설치할 수 있습니다.
<code>pip install openrl</code>
conda를 통해서도 설치할 수 있습니다.
<code>conda install -c openrl openrl</code>
OpenRL은 강화 학습의 초급 사용자에게 간단하고 사용하기 쉬운 인터페이스를 제공합니다. CartPole 환경을 훈련하기 위해 PPO 알고리즘을 사용하는 예:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>
OpenRL을 사용하여 에이전트 훈련 네 가지 간단한 단계만 필요합니다: 환경 생성=> 에이전트 초기화=> 훈련 시작!
위 코드를 일반 노트북에서 실행하면 몇 초만에 에이전트 훈련이 완료됩니다. 훈련을 위해 OpenRL은 동일하고 간단하고 사용하기 쉬운 인터페이스를 제공합니다. 예를 들어 다중 에이전트 작업의 MPE 환경의 경우 OpenRL은 훈련을 완료하기 위해 몇 줄의 코드만 호출하면 됩니다.
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>
다음 그림은 OpenRL을 통한 훈련 전후의 에이전트 성능을 보여줍니다. 
구성 파일 로드
또한 OpenRL은 명령줄과 구성 파일 모두에서 훈련 매개변수 수정을 지원합니다. 예를 들어, 사용자는 python train_ppo.py --lr 5e-4를 실행하여 훈련 중에 학습 속도를 빠르게 수정할 수 있습니다.
구성 매개변수가 많은 경우 OpenRL은 사용자가 자체 구성 파일을 작성하여 훈련 매개변수를 수정할 수 있도록 지원합니다. 예를 들어, 사용자는 다음 구성 파일(mpe_ppo.yaml)을 생성하고 그 안에 있는 매개변수를 수정할 수 있습니다. 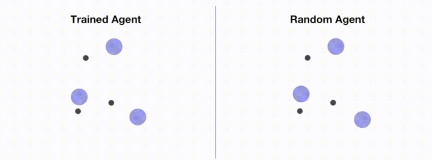
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
마지막으로 사용자는 프로그램을 실행할 때 구성 파일만 지정하면 됩니다.
<code>python train_ppo.py --config mpe_ppo.yaml</code>
训练与测试可视化
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:

OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>
此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>
执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>
上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>
然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>
自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>
OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>
最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>
自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
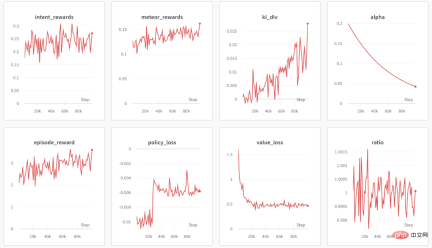
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>
最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
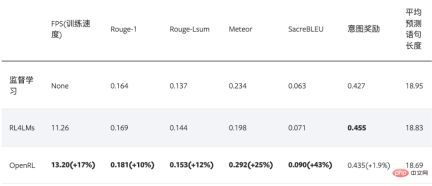
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>
执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c- ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine :https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github.com/allenai/ RL4LM
향후 작업
현재 OpenRL은 여전히 지속적인 개발 및 구축 단계에 있습니다. 앞으로 OpenRL은 더 많은 기능을 오픈 소스로 제공할 예정입니다.
- 지원 에이전트 자체 게임 교육
- 추가 오프라인 강화 학습, 모델 학습, 역 강화 학습 알고리즘
- 더 많은 강화 학습 환경 및 알고리즘 추가
- Deepspeed와 같은 가속 프레임워크 통합
- 다중 기계 분산 훈련 지원
OpenRL Lab 팀
OpenRL 프레임워크 4Paradigm의 강화학습 연구팀인 OpenRL Lab 팀에서 개발했습니다. Fourth Paradigm은 오랫동안 강화 학습의 연구, 개발 및 산업적 적용에 전념해 왔습니다. 강화 학습에 대한 산학연 통합을 촉진하기 위해 4Paradigm은 오픈 소스 첨단 기술과 인공 지능의 개척을 목표로 OpenRL Lab 연구팀을 설립했습니다. OpenRL Lab 팀은 설립된 지 1년도 채 되지 않아 AAMAS에 3편의 논문을 발표했고, Google Football Game 11 vs 11 대회에 참가하여 3위를 차지했습니다. 팀이 제안한 TiZero 에이전트는 커리큘럼 학습, 분산 강화 학습, 자체 게임 및 기타 기술을 통해 처음부터 Google 축구 전체 게임 에이전트의 최초 완전 학습을 달성했습니다.

2022년 10월 28일, 타이제로가 지디 평가 플랫폼 1위에 올랐습니다:

위 내용은 훈련 속도가 17% 향상되었습니다. 네 번째 패러다임 오픈 소스 강화 학습 연구 프레임워크는 단일 및 다중 에이전트 훈련을 지원합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Tesla의 Robovan은 2024 년 Robotaxi 티저의 숨겨진 보석이었습니다.Apr 22, 2025 am 11:48 AM
Tesla의 Robovan은 2024 년 Robotaxi 티저의 숨겨진 보석이었습니다.Apr 22, 2025 am 11:48 AM2008 년 이래로 저는 도시 교통의 미래로서 "Robotjitney"라고 불리는 공유 라이드 밴을 옹호했습니다. 나는이 차량들을 21 세기의 차세대 대중 교통 솔루션 인 Surpas로 예측합니다.
 Sam 's Club은 영수증 수표를 제거하고 소매를 강화하기 위해 AI에 베팅합니다.Apr 22, 2025 am 11:29 AM
Sam 's Club은 영수증 수표를 제거하고 소매를 강화하기 위해 AI에 베팅합니다.Apr 22, 2025 am 11:29 AM체크 아웃 경험 혁명 Sam 's Club의 혁신적인 "Just Go"시스템은 기존 AI 기반 AI 기반 "Scan & Go"기술을 기반으로하여 회원이 쇼핑 중에 Sam's Club 앱을 통해 구매를 스캔 할 수 있습니다.
 Nvidia의 AI Omniverse는 GTC 2025에서 확장됩니다Apr 22, 2025 am 11:28 AM
Nvidia의 AI Omniverse는 GTC 2025에서 확장됩니다Apr 22, 2025 am 11:28 AMGTC 2025에서 Nvidia의 향상된 예측 가능성 및 신제품 라인업 AI 인프라의 핵심 업체 인 Nvidia는 고객의 예측 가능성 증가에 중점을두고 있습니다. 여기에는 일관된 제품 제공, 성과 기대치 충족 및 충족이 포함됩니다
 Google의 Gemma 2 모델의 기능을 탐색합니다Apr 22, 2025 am 11:26 AM
Google의 Gemma 2 모델의 기능을 탐색합니다Apr 22, 2025 am 11:26 AMGoogle의 Gemma 2 : 강력하고 효율적인 언어 모델 효율성과 성능으로 축하되는 Google의 Gemma Family of Language 모델은 Gemma 2의 도착으로 확장되었습니다.이 최신 릴리스는 두 가지 모델로 구성됩니다 : 27 억 매개 변수 Ver Ver
 Genai의 다음 물결 : Kirk Borne 박사와의 관점 -Salystics VidhyaApr 22, 2025 am 11:21 AM
Genai의 다음 물결 : Kirk Borne 박사와의 관점 -Salystics VidhyaApr 22, 2025 am 11:21 AM이 데이터 에피소드와 함께이 선도에는 주요 데이터 과학자, 천체 물리학 자, TEDX 스피커 인 Kirk Borne 박사가 있습니다. Borne 박사는 빅 데이터, AI 및 머신 러닝 분야의 유명한 전문가 인 현재 상태와 미래의 Traje에 대한 귀중한 통찰력을 제공합니다.
 주자와 운동 선수를위한 AI : 우리는 훌륭한 진전을 이루고 있습니다Apr 22, 2025 am 11:12 AM
주자와 운동 선수를위한 AI : 우리는 훌륭한 진전을 이루고 있습니다Apr 22, 2025 am 11:12 AM이 연설에는 인공 지능이 사람들의 신체 운동을 지원하는 데 왜 좋은지를 보여주는 공학에 대한 백 그라운드 정보가 매우 통찰력있는 관점이있었습니다. 스포츠에서 인공 지능 적용을 탐구하는 데 중요한 부분 인 세 가지 디자인 측면을 보여주기 위해 각 기고자의 관점에서 핵심 아이디어를 간략하게 설명 할 것입니다. 에지 장치 및 원시 개인 데이터 인공 지능에 대한이 아이디어에는 실제로 두 가지 구성 요소가 포함되어 있습니다. 하나는 우리가 큰 언어 모델을 배치하는 위치와 관련하여 하나의 구성 요소와 다른 하나는 인간 언어와 활력 징후가 실시간으로 측정 될 때“표현”하는 언어의 차이와 관련이 있습니다. Alexander Amini는 달리기와 테니스에 대해 많은 것을 알고 있지만 그는 여전히
 Caterpillar의 기술, 인재 및 혁신에 관한 Jamie EngstromApr 22, 2025 am 11:10 AM
Caterpillar의 기술, 인재 및 혁신에 관한 Jamie EngstromApr 22, 2025 am 11:10 AMCaterpillar의 최고 정보 책임자이자 IT의 수석 부사장 인 Jamie Engstrom은 28 개국에서 2,200 명 이상의 IT 전문가로 구성된 글로벌 팀을 이끌고 있습니다. 현재 역할에서 4 년 반을 포함하여 Caterpillar에서 26 년 동안 Engst
 새로운 Google 사진 업데이트는 Ultra HDR 품질로 모든 사진 팝을 만듭니다.Apr 22, 2025 am 11:09 AM
새로운 Google 사진 업데이트는 Ultra HDR 품질로 모든 사진 팝을 만듭니다.Apr 22, 2025 am 11:09 AMGoogle Photos의 새로운 Ultra HDR 도구 : 빠른 가이드 Google Photos의 새로운 Ultra HDR 도구로 사진을 향상시켜 표준 이미지를 활기차고 높은 동기 범위의 걸작으로 변환하십시오. 소셜 미디어에 이상적 이며이 도구는 모든 사진의 영향을 높이고


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

