
Qingbei Microsoft는 GPT를 깊이 파고들어 상황별 학습을 이해합니다! 매개변수가 변경되지 않았다는 점을 제외하면 기본적으로 미세 조정과 동일합니다.

- 王林앞으로
- 2023-05-10 21:37:041099검색
대규모 사전 훈련된 언어 모델의 중요한 기능 중 하나는 ICL(문맥 내 학습) 기능입니다. 즉, 일부 예시적인 입력-레이블 쌍을 통해 매개변수를 업데이트하지 않고도 새로운 입력 레이블을 학습할 수 있습니다. .
성능이 향상되었지만 대형 모델의 ICL 기능은 어디에서 나오는지 여전히 의문입니다.
ICL의 작동 방식을 더 잘 이해하기 위해 Tsinghua University, Peking University 및 Microsoft의 연구원들은 언어 모델을 메타 최적화 프로그램(meta-optimizer)으로 해석하고 ICL을 암시적 미세 조정으로 이해하는 논문을 공동으로 발표했습니다.

문서 링크: https://arxiv.org/abs/2212.10559
이 글에서는 이론적으로 Transformer attention Dual form(dual form)에 경사하강법 기반 최적화가 있음을 명확히 합니다. form)을 토대로 ICL을 이해하면 다음과 같다. GPT는 먼저 데모 인스턴스를 기반으로 메타 그라데이션을 생성한 다음 이러한 메타 그라데이션을 원본 GPT에 적용하여 ICL 모델을 구축합니다.
실험에서 연구원들은 ICL의 동작과 실제 작업을 기반으로 한 명시적 미세 조정을 종합적으로 비교하여 이러한 이해를 뒷받침하는 경험적 증거를 제공했습니다.
결과는 ICL이 예측 수준, 표현 수준 및 주의 행동 수준에서 명시적 미세 조정과 유사하게 수행된다는 것을 증명합니다.
또한 메타 최적화에 대한 이해에서 영감을 받아 운동량 기반 경사하강법 알고리즘과의 비유를 통해 이 기사에서는 다른 곳에서 일반 주의보다 성능이 더 좋은 모멘텀 기반 주의도 설계했습니다. 한 가지 측면은 이러한 이해의 정확성을 다시 뒷받침하고 모델의 추가 설계에 이러한 이해를 사용할 가능성도 보여줍니다.
ICL의 원리
연구원들은 먼저 Transformer의 선형 주의 메커니즘에 대한 정성 분석을 수행하여 경사하강법 기반 최적화 간의 이중 형태를 찾아냈습니다. 그런 다음 ICL을 명시적 미세 조정과 비교하고 이 두 가지 최적화 형태 사이에 연결이 설정됩니다.
Transformer attention은 메타 최적화입니다.
X가 전체 쿼리의 입력 표현이고, X'가 예제의 표현이고, q가 쿼리 벡터라고 가정하고, ICL 설정에서 Attention은 결과는 다음과 같습니다.
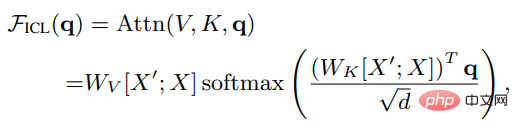
스케일링 인수 루트 d와 소프트맥스를 제거한 후 표준 주의 메커니즘은 다음과 같이 근사화될 수 있음을 알 수 있습니다.
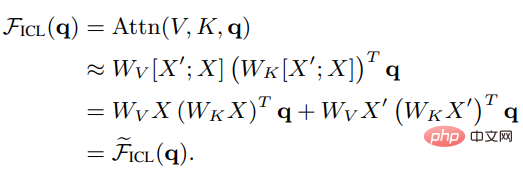
Wzsl을 ZSL(Zero-Shot Learning)으로 설정하면 Transformer attention은 다음 이중 형식으로 변환될 수 있습니다.
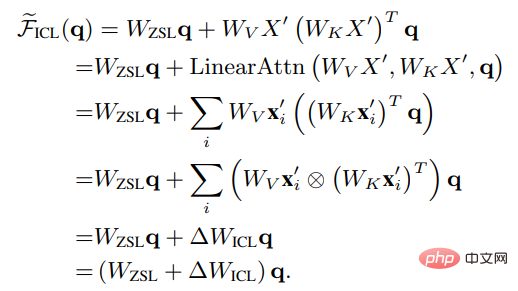
ICL은 메타 최적화 프로세스로 해석될 수 있음을 알 수 있습니다.
1. Transformer 기반 사전 훈련된 언어 모델을 메타 옵티마이저로 사용합니다.
2. 순방향 계산을 통해 데모 예제에 따라 메타 그라데이션을 계산합니다. Attention 메커니즘을 통해 원본 언어 모델에서 ICL 모델을 구축합니다.
ICL과 미세 조정의 비교
ICL의 메타 최적화와 명시적 최적화를 비교하기 위해 연구원들은 특정 미세 조정 설정을 비교 기준으로 설계했습니다. 관심의 키와 가치이므로 미세 조정은 키와 가치 예측의 매개변수만 업데이트합니다.선형 주의의 비엄격한 형태와 마찬가지로 미세 조정 후 머리 주의 결과는 다음과 같이 표현될 수 있습니다.
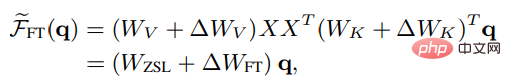
ICL과 보다 공정한 비교를 위해 미세 조정 설정은 다음과 같습니다. 다음과 같이 제한됩니다.
1. 훈련 예제를 ICL의 데모 예제로 지정합니다.
2. 각 예제에 대해 한 단계만 훈련을 수행하며 순서는 데모와 동일합니다.
3. 각 훈련 예제는 ICL에서 사용하는 템플릿으로 형식화되고 인과 언어 모델링 목표를 사용하여 미세 조정됩니다.
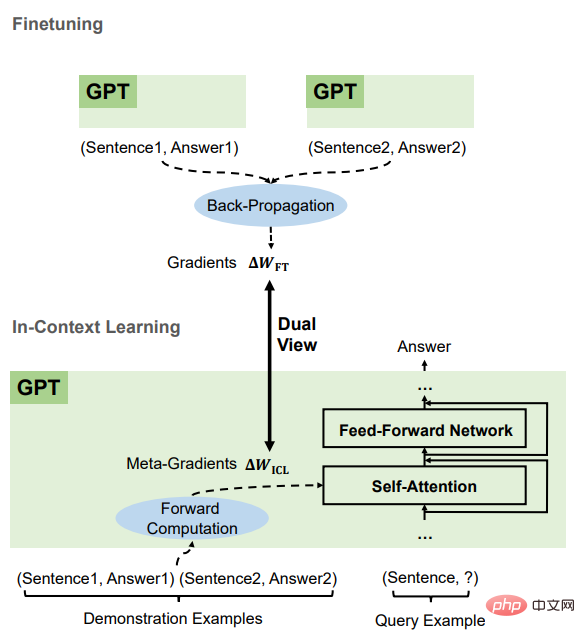
비교 후 ICL과 미세 조정에는 주로 네 가지 측면을 포함하여 많은 공통 속성이 있음을 알 수 있습니다.
은 모두 경사하강법
ICL과 Fine-tuning 모두 Wzsl, 즉 경사하강법을 업데이트한 것을 확인할 수 있습니다. 유일한 차이점은 ICL이 순방향 계산을 통해 메타 경사도를 생성한다는 것입니다. , 미세 조정은 역방향 계산을 통해 메타 기울기를 생성하여 실제 기울기를 얻습니다.
동일한 학습 정보
ICL의 메타 기울기는 데모 예제를 기반으로 구하고, Fine-tuning의 기울기도 동일한 학습 샘플, 즉 ICL에서 구합니다. 미세 조정은 훈련 정보의 동일한 소스를 공유합니다.
훈련 예제의 인과 순서는 동일합니다
ICL과 미세 조정은 디코더 전용 변환기를 사용하므로 예제의 후속 토큰은 이전 샘플에 영향을 주지 않습니다. 미세 조정을 위해 훈련 예제의 순서가 동일하고 단 하나의 에포크만 훈련되므로 후속 샘플이 이전 샘플에 영향을 미치지 않는다는 것도 보장할 수 있습니다.
둘 다 attention에 작용합니다
제로샷 학습과 비교하여 ICL과 미세 조정의 직접적인 영향은 attention의 키와 값 계산으로 제한됩니다. ICL의 경우 모델 매개변수는 변경되지 않으며, 미세 조정에 도입된 제한 사항에 대해 주의 행동을 변경하기 위해 예제 정보를 추가 키와 값으로 인코딩합니다. 훈련 정보는 주의 키의 투영에만 영향을 미칠 수 있습니다. 값.
ICL과 미세 조정의 이러한 공통 특성을 바탕으로 연구자들은 ICL을 일종의 암시적 미세 조정으로 이해하는 것이 합리적이라고 믿습니다.
실험 부분
작업 및 데이터 세트
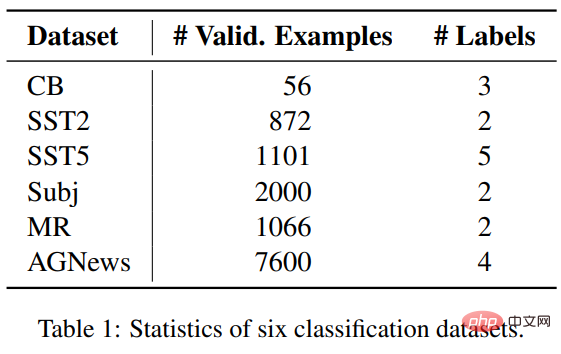
연구원은 ICL과 미세 조정을 비교하기 위해 3가지 분류 작업에서 SST2, SST-5, MR 및 Subj를 포함한 6개의 데이터 세트를 선택했습니다. 감정 분류에 사용됩니다. AGNews는 주제 분류 데이터 세트입니다. CB는 자연어 추론에 사용됩니다.
실험 설정
모델 부분은 fairseq에서 출시한 GPT와 유사한 사전 훈련된 두 가지 언어 모델을 사용하며 매개변수 양은 각각 1.3B 및 2.7B입니다.
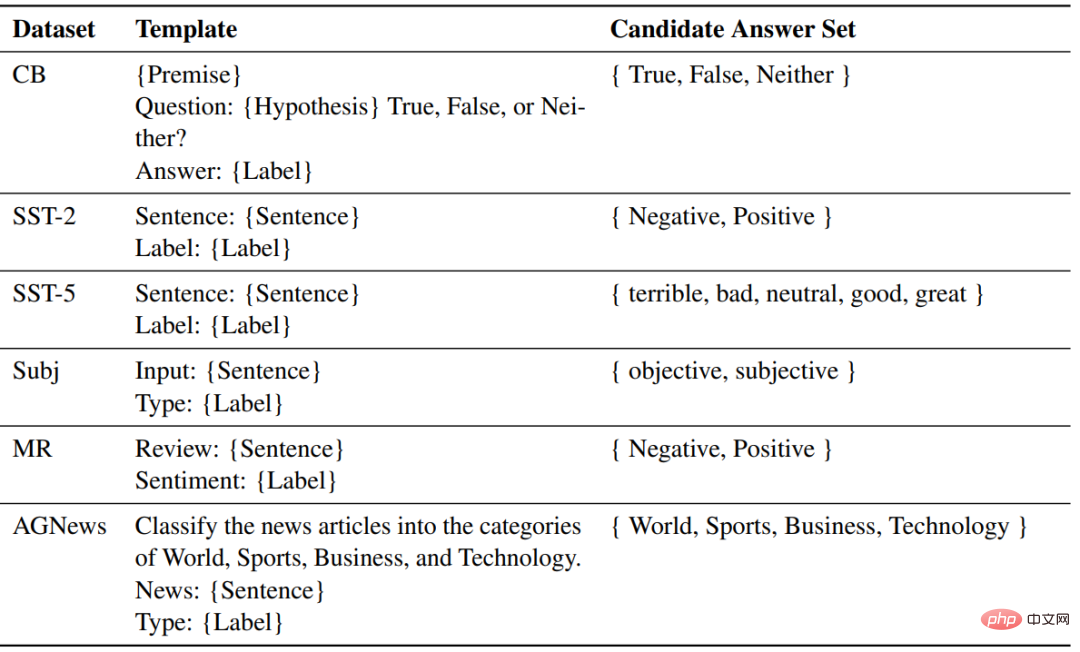
각 작업에 대해 동일한 템플릿을 사용하여 ZSL, ICL 및 미세 조정을 위한 샘플 형식을 지정합니다.
Results
정확도
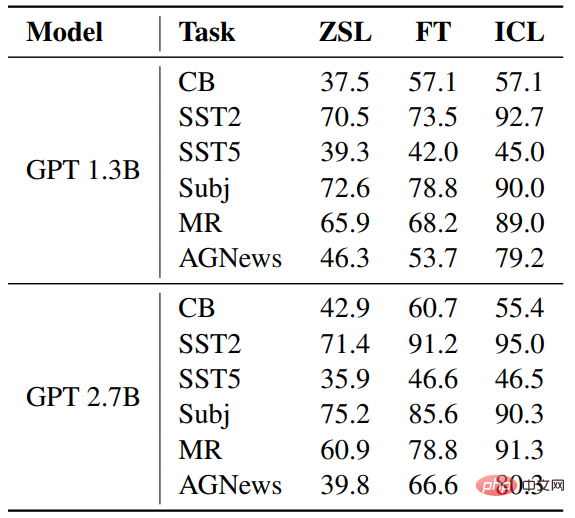
ZSL에 비해 ICL과 미세 조정 모두 상당한 개선을 이루었습니다. 이는 최적화가 이러한 다운스트림 작업에 도움이 된다는 것을 의미합니다. 또한 일부 경우에는 ICL이 미세 조정보다 낫습니다.
Rec2FTP(미세 조정 예측 호출)
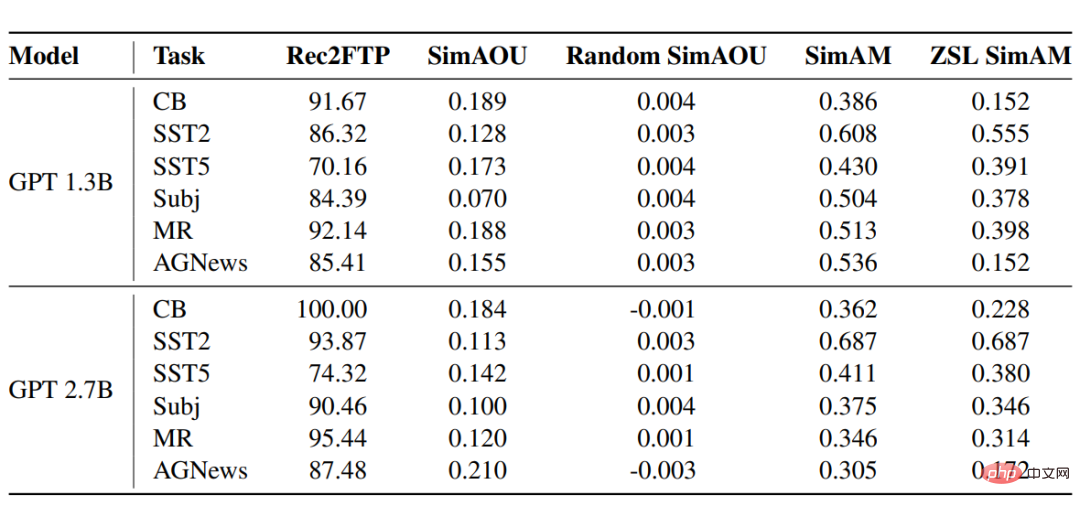
6개 데이터 세트에 대한 GPT 모델의 점수 결과는 평균적으로 ICL이 예제의 87.64%를 정확하게 예측할 수 있는 반면 Fine -튜닝을 통해 ZSL을 수정할 수 있습니다. 예측 수준에서 ICL은 미세 조정을 위한 올바른 동작의 대부분을 다룰 수 있습니다.
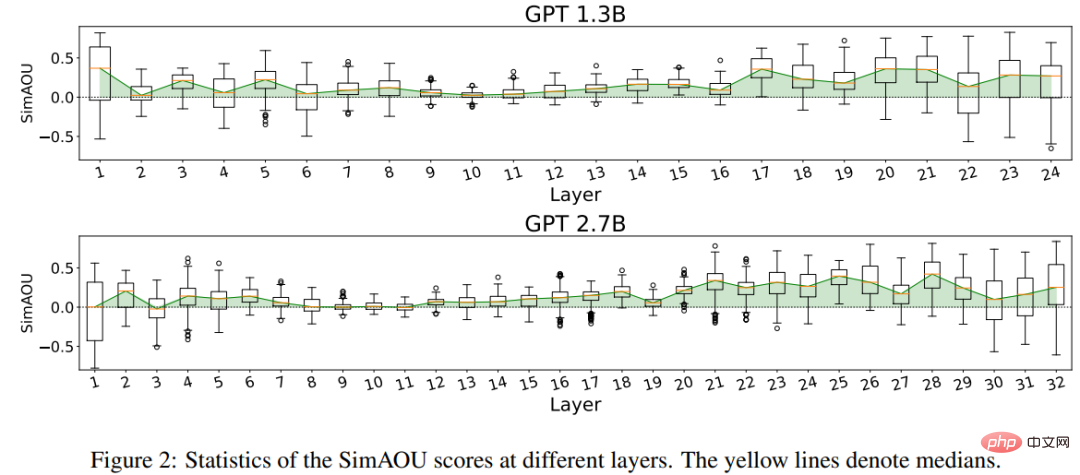
SimAOU (Similarity of Attention Output Updates)
ICL 업데이트와 미세 조정 업데이트의 유사성이 무작위 업데이트보다 훨씬 높다는 결과를 확인할 수 있으며, 이는 표현에서도 수준에서 ICL은 주의력 결과의 변화가 넛지의 변화와 동일한 방향으로 나타나는 경향이 있습니다.
SimAM(Similarity of Attention Map)
ZSL SimAM은 SimAM의 기준 지표로 ICL 주의 가중치와 ZSL 주의 가중치 간의 유사성을 계산합니다. 이 두 측정항목을 비교하면 ZSL과 비교하여 ICL이 미세 조정과 유사한 주의 가중치를 생성하는 경향이 있음을 알 수 있습니다.
마찬가지로 주의 행동 수준에서 실험 결과는 ICL이 미세 조정과 유사하게 행동한다는 것을 증명합니다.
위 내용은 Qingbei Microsoft는 GPT를 깊이 파고들어 상황별 학습을 이해합니다! 매개변수가 변경되지 않았다는 점을 제외하면 기본적으로 미세 조정과 동일합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!