
TensorFlow와 Keras를 사용하면 첫 번째 신경망을 쉽게 구축하고 훈련할 수 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-09 19:04:06926검색
AI 기술은 빠르게 발전하고 있으며 다양한 첨단 AI 모델을 활용해 채팅 로봇, 휴머노이드 로봇, 자율주행차 등을 만들 수 있다. AI는 가장 빠르게 성장하는 기술이 되었으며, 객체 감지 및 객체 분류가 최근 트렌드입니다.
이 기사에서는 컨벌루션 신경망을 사용하여 이미지 분류 모델을 처음부터 구축하고 훈련하는 전체 단계를 소개합니다. 이 기사에서는 공개 Cifar-10 데이터 세트를 사용하여 이 모델을 교육합니다. 이 데이터세트는 자동차, 비행기, 개, 고양이 등과 같은 일상 사물의 이미지를 포함하고 있다는 점에서 독특합니다. 이 기사에서는 이러한 객체에 대한 신경망을 훈련함으로써 현실 세계에서 이러한 객체를 분류하는 지능형 시스템을 개발할 것입니다. 여기에는 10가지 다양한 유형의 개체에 대한 60,000개 이상의 32x32 이미지가 포함되어 있습니다. 이 튜토리얼이 끝나면 시각적 특성을 기반으로 객체를 식별할 수 있는 모델을 갖게 됩니다.

그림 1 데이터 세트 샘플 이미지 | Datasets.activeloop의 이미지
이 기사에서는 처음부터 모든 내용을 다룰 것이므로 신경망의 실제 구현을 배우지 않았다면 전혀 괜찮습니다.
다음은 이 튜토리얼의 전체 워크플로입니다.
- 필요한 라이브러리 가져오기
- 데이터 로드
- 데이터 전처리
- 모델 빌드
- 모델 성능 평가
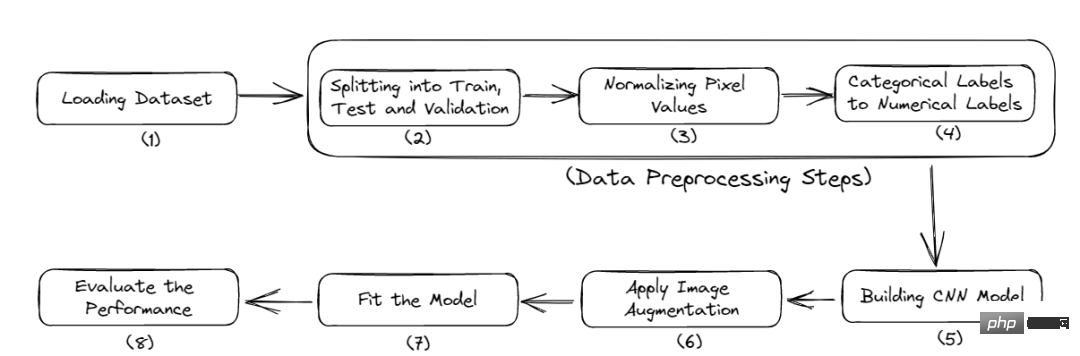
그림 2 프로세스 완료
필요한 라이브러리 가져오기
먼저 이 프로젝트를 시작하려면 일부 모듈을 설치해야 합니다. 이 기사에서는 무료 GPU 교육을 제공하는 Google Colab을 사용합니다.
다음은 필수 라이브러리를 설치하는 명령입니다.
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
라이브러리를 Python 파일로 가져옵니다.
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
- Numpy: 이미지가 포함된 대규모 데이터 세트에 대한 효율적인 배열 계산에 사용됩니다.
- Tensorflow: Google에서 개발한 오픈소스 머신러닝 라이브러리입니다. 크고 확장 가능한 모델을 구축하는 데 필요한 다양한 기능을 제공합니다.
- Keras: TensorFlow 위에서 실행되는 또 다른 고급 신경망 API입니다.
- Matplotlib: 이 Python 라이브러리는 차트를 생성하고 더 나은 데이터 시각화를 제공할 수 있습니다.
- Sklearn: 데이터 세트에서 데이터 전처리 및 특징 추출 작업을 수행하는 기능을 제공합니다. 여기에는 정확도, 정밀도, 거짓 긍정, 거짓 부정 등과 같은 모델 평가 지표를 찾는 기본 기능이 포함되어 있습니다.
이제 데이터 로딩 단계로 들어갑니다.
데이터 로드
이 섹션에서는 데이터 세트를 로드하고 훈련-테스트 데이터 분할을 수행합니다.
데이터 로드 및 분할:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>
cifar10 데이터세트는 Keras 데이터세트 라이브러리에서 직접 로드됩니다. 그리고 이 데이터도 훈련 데이터와 테스트 데이터로 나누어집니다. 훈련 데이터는 모델이 내부의 패턴을 인식할 수 있도록 훈련하는 데 사용됩니다. 테스트 데이터는 모델에 표시되지 않지만 성능, 즉 총 데이터 포인트 수에 비해 얼마나 많은 데이터 포인트가 올바르게 예측되었는지 확인하는 데 사용됩니다.
training_label에는 training_data의 이미지에 해당하는 라벨이 포함되어 있습니다.
그런 다음 내장된 sklearn의 train_test_split 함수를 사용하여 훈련 데이터를 검증 데이터로 다시 분할합니다. 검증 데이터는 최종 모델을 선택하고 조정하는 데 사용되었습니다. 마지막으로 모든 교육, 테스트 및 검증 데이터는 32비트 부동 소수점 숫자로 변환됩니다.
이제 데이터세트 로딩이 완료되었습니다. 다음 섹션에서는 이 문서에 대해 몇 가지 전처리 단계를 수행합니다.
데이터 전처리
데이터 전처리는 기계 학습 모델을 개발할 때 첫 번째이자 가장 중요한 단계입니다. 이를 수행하는 방법을 알아 보려면 이 문서를 따르십시오.
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>
출력:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
이 데이터 세트에는 10개 카테고리의 이미지가 포함되어 있으며 각 이미지 크기는 32x32픽셀입니다. 각 픽셀은 0~255 사이의 값을 가지며, 계산 과정을 단순화하기 위해 이를 0~1 사이로 정규화해야 합니다. 그런 다음 범주형 레이블을 원-핫 인코딩된 레이블로 변환합니다. 이는 범주형 데이터를 수치 데이터로 변환하여 기계 학습 알고리즘을 문제 없이 적용할 수 있도록 하기 위한 것입니다.
이제 CNN 모델 구축에 들어갑니다.
CNN 모델 구축
CNN 모델은 세 단계로 작동합니다. 첫 번째 단계는 이미지에서 관련 특징을 추출하는 컨볼루셔널 레이어로 구성됩니다. 두 번째 단계는 이미지 크기를 줄이기 위한 풀링 레이어로 구성됩니다. 또한 모델의 과적합을 줄이는 데도 도움이 됩니다. 세 번째 단계는 2D 이미지를 1D 배열로 변환하는 조밀한 레이어로 구성됩니다. 마지막으로 이 배열은 완전 연결 레이어에 입력되어 최종 예측을 수행합니다.
다음 코드는 다음과 같습니다.
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
이 문서에서는 3개의 레이어 세트를 적용합니다. 각 세트에는 2개의 컨볼루션 레이어, 즉 최대 풀링 레이어와 드롭아웃 레이어가 포함되어 있습니다. Conv2D 레이어는 input_shape를 (32, 32, 3)으로 받습니다. 이는 이미지와 크기가 동일해야 합니다.
각 Conv2D 레이어에는 relu라는 활성화 함수도 필요합니다. 활성화 기능은 시스템의 비선형성을 높이는 데 사용됩니다. 더 간단히 말하면 특정 임계값에 따라 뉴런을 활성화해야 하는지 여부를 결정합니다. 뉴런의 발화를 결정하기 위해 다양한 알고리즘을 사용하는 ReLu, Tanh, Sigmoid, Softmax 등과 같은 다양한 유형의 활성화 함수가 있습니다.
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
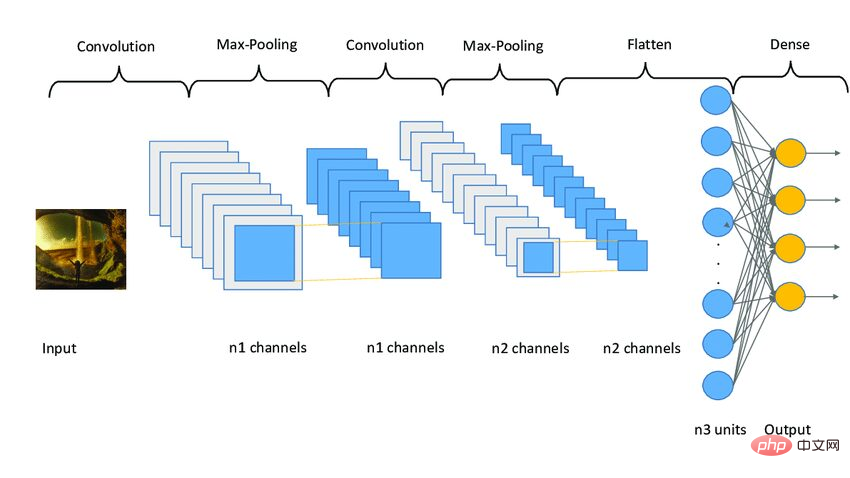
图3 Sampe CNN架构|图片来源:Researchgate
编译模型
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
拟合模型
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
评估模型性能
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>
输出:
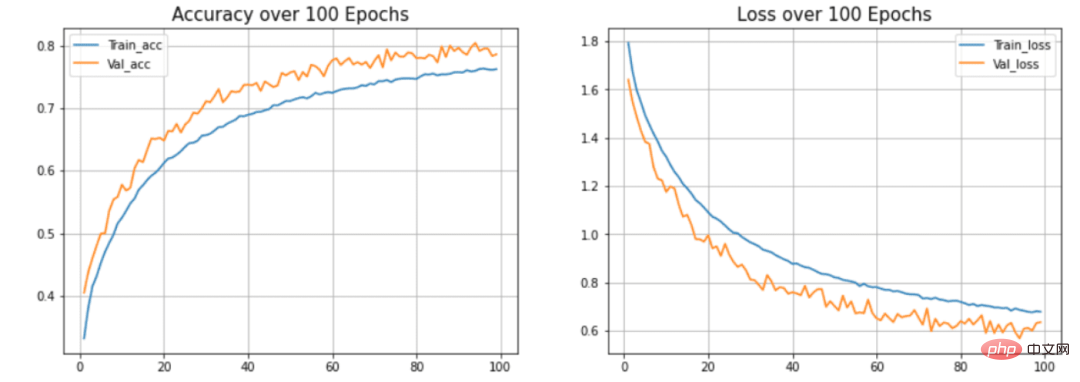
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
总结
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
위 내용은 TensorFlow와 Keras를 사용하면 첫 번째 신경망을 쉽게 구축하고 훈련할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!