
Java HashMap의 다중 스레드 동시성 문제를 해결하는 방법

- PHPz앞으로
- 2023-05-09 14:28:171657검색
동시성 문제의 증상
멀티 스레드 put으로 인해 get의 무한 루프가 발생할 수 있음
과거에 우리 Java 코드에서는 어떤 이유로 HashMap을 사용했지만 당시 프로그램은 단일 스레드였으며 모든 것이 괜찮았습니다. 나중에 프로그램에 성능 문제가 발생하여 멀티 스레드가 필요했습니다. 그래서 멀티 스레드가 된 후 온라인에 접속하여 프로그램이 종종 CPU의 100%를 차지하는 것을 발견했습니다. 프로그램이 모두 HashMap에서 중단되었습니다. .get() 메서드가 설치되었으며 프로그램을 다시 시작한 후 문제가 사라졌습니다. 그러나 잠시 후에 다시 올 것입니다. 게다가 이 문제는 테스트 환경에서 재현하기 어려울 수도 있습니다.
우리가 직접 작성한 코드만 보면 HashMap이 여러 스레드로 동작한다는 것을 알 수 있습니다. Java 문서에는 HashMap이 스레드로부터 안전하지 않으므로 ConcurrentHashMap을 사용해야 한다고 나와 있습니다. 하지만 여기서 우리는 그 이유를 연구할 수 있습니다. 간단한 코드는 다음과 같습니다.
package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t1 over" );
}
};
Thread t2 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t2 over" );
}
};
Thread t3 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t3 over" );
}
};
Thread t4 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t4 over" );
}
};
Thread t5 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t5 over" );
}
};
Thread t6 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t6 over" );
}
};
Thread t7 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t7 over" );
}
};
Thread t8 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t8 over" );
}
};
Thread t9 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t9 over" );
}
};
Thread t10 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t10 over" );
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}는 10개의 스레드를 시작하고 스레드로부터 안전하지 않은 HashMap에 콘텐츠를 지속적으로 넣거나 가져오는 것입니다. 넣기의 내용은 매우 간단합니다. 키와 값은 모두 0에서 증가하는 정수입니다. (이것은 내용이 별로 좋지 않아서 나중에 문제를 분석하는 데 방해가 되었습니다.) HashMap에서 동시 쓰기 작업을 수행하면 더티 데이터만 생성될 것이라고 생각했지만 이 프로그램을 반복적으로 실행하면 스레드 t1과 t2가 중단되는 경우가 대부분이며 다른 스레드는 성공적으로 종료됩니다. , 때때로 10개의 스레드가 모두 정지되는 경우가 있습니다.
이 무한 루프의 근본 원인은 보호되지 않은 공유 변수인 "HashMap" 데이터 구조의 작동에 있습니다. 모든 조작방법에 "동기화"를 추가한 후 모든 것이 정상으로 돌아왔습니다. 이것은 jvm 버그입니까? 아니, 이런 현상은 오래 전부터 보고된 바 있다고 해야 할 것이다. Sun 엔지니어는 이것이 버그라고 생각하지 않지만 이러한 시나리오에서는 "ConcurrentHashMap"을 사용해야 한다고 제안합니다.
과도한 CPU 사용은 일반적으로 무한 루프로 인해 일부 스레드가 계속 실행되고 CPU 시간을 차지하게 됩니다. 문제의 원인은 HashMap이 Thread-Safe하지 않다는 점이다. 여러 개의 Thread가 투입되면 특정 Key 값 Entry Key List의 무한 루프가 발생하게 되어 문제가 발생한다.
다른 스레드가 이 항목 목록 무한 루프의 키를 가져오면 이 가져오기가 항상 실행됩니다. 최종 결과는 점점 더 많은 스레드가 무한 루프에 빠지게 되어 결국 서버가 충돌하게 됩니다. 우리는 일반적으로 HashMap이 특정 값을 반복적으로 삽입하면 이전 값을 덮어쓸 것이라고 생각합니다. 이것이 맞습니다. 그러나 멀티 스레드 액세스의 경우 내부 구현 메커니즘으로 인해(멀티 스레드 환경에서 동기화가 없는 경우 동일한 HashMap에 대한 넣기 작업으로 인해 두 개 이상의 스레드가 동시에 다시 해시 작업을 수행하게 될 수 있습니다. 순환 키 테이블이 나타나면 스레드를 종료할 수 없고 계속해서 CPU를 점유하여 CPU 사용량이 높아지면 보안 문제가 발생할 수 있습니다.
jstack 도구를 사용하여 문제가 있는 서버의 스택 정보를 덤프합니다. 무한 루프가 발생하는 경우 먼저 RUNNABLE 스레드를 검색하여 다음과 같이 문제 코드를 찾습니다.
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.get(HashMap.java:303)
com.sohu.twap .service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
총 23회 등장했습니다.
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.put(HashMap.java:374)
at com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter.java:816)
합계 3번 등장.
Note: HashMap을 부적절하게 사용하면 교착 상태가 아닌 무한 루프가 발생합니다.
멀티 스레드 넣기로 인해 요소가 손실될 수 있습니다.
주요 문제는 addEntry 메서드의 새 항목(해시, 키, 값, e)에 있습니다. 두 스레드가 동시에 e를 얻으면 다음 요소는 e 이면 테이블 요소에 값을 할당할 때 하나는 성공하고 다른 하나는 손실됩니다.
null이 아닌 요소를 넣은 후 얻은 결과는 null입니다
transfer 메소드의 코드는 다음과 같습니다.
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for ( int j = 0 ; j < src.length; j++) {
Entry e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}이 메소드에서는 이전 배열을 src에 할당하고 src를 탐색하며 src의 요소가 src의 요소는 null로 설정됩니다. 이는 이전 배열의 요소가 null로 설정됨을 의미합니다. 이는 다음 문장입니다.
if (e != null ) {
src[j] = null ;현재 이 키에 액세스할 수 있는 get 메소드가 있는 경우 , 여전히 이전 배열을 가져오며 물론 해당 값을 가져올 수 없습니다.
요약: HashMap이 동기화되지 않으면 동시성 프로그램에서 미묘한 문제가 많이 발생하게 되며, 표면적으로는 원인을 찾기가 어렵습니다. 따라서 HashMap을 사용할 때 직관에 어긋나는 현상이 발생한다면 이는 동시성에 의한 것일 수 있습니다.
HashMap 데이터 구조
고전적인 데이터 구조 HashMap에 대해 간략하게 이야기해야겠습니다.
HashMap은 일반적으로 모든 키를 분산시키기 위해 포인터 배열(table[]로 가정)을 사용합니다. 키가 추가되면 배열의 첨자 i를 Hash 알고리즘을 통해 키를 통해 계산한 다음 이를 In에 삽입합니다. table[i]에서 두 개의 서로 다른 키가 동일한 i에 대해 계산되는 경우 이를 충돌이라고 하며 이를 충돌이라고도 합니다. 이는 table[i]에 연결된 목록을 형성합니다.
테이블[]의 크기가 2개와 같이 매우 작은 경우, 10개의 키를 넣으면 충돌이 매우 자주 발생하므로 O(1) 검색 알고리즘은 연결 목록이 됩니다. 성능은 O(n)이 되는데 이는 해시 테이블의 결함입니다.
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null ;
}检查容量是否超标:
void addEntry( int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize( 2 * table.length);
}新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize( int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = ( int )(newCapacity * loadFactor);
}迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for ( int j = 0 ; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash过程
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table1这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程。
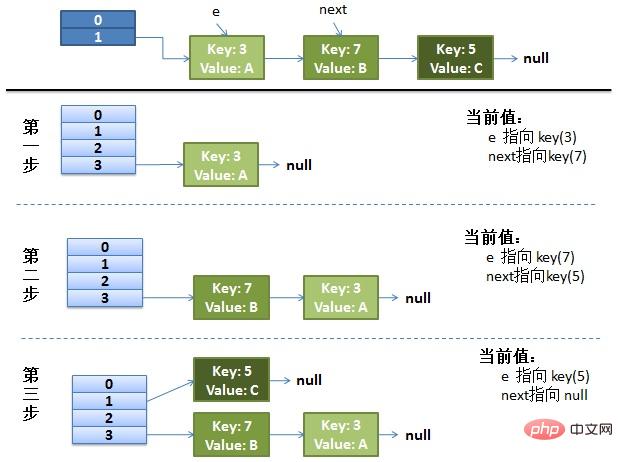
并发的Rehash过程
(1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );而我们的线程二执行完成了。于是我们有下面的这个样子。
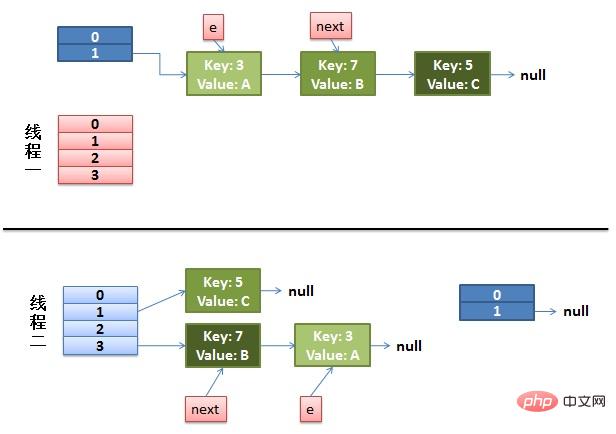
注意:因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
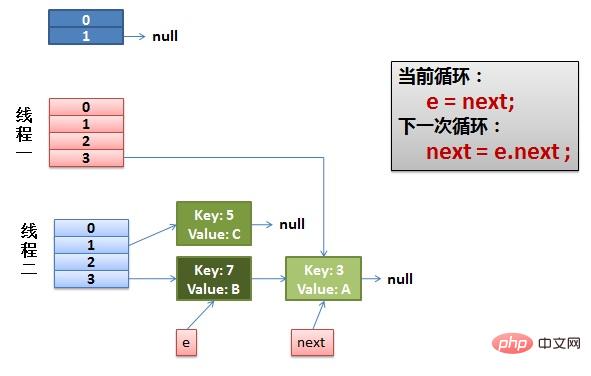
(2)线程一被调度回来执行。
先是执行 newTalbe[i] = e。
然后是e = next,导致了e指向了key(7)。
而下一次循环的next = e.next导致了next指向了key(3)。
(3)一切安好。 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
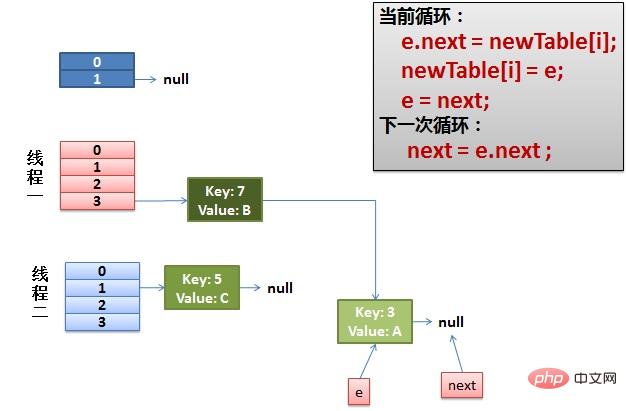
(4)环形链接出现。 e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
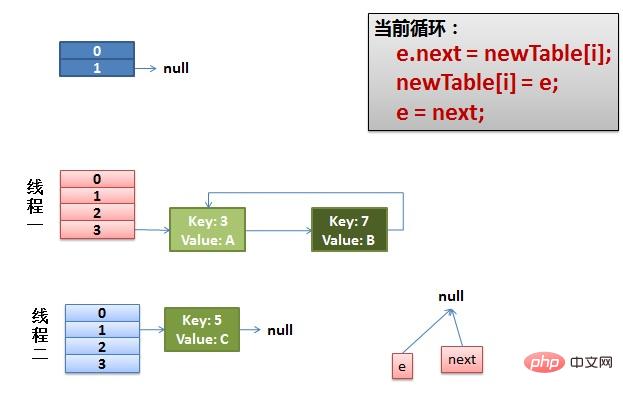
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三种解决方案
Hashtable替换HashMap
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
Collections.synchronizedMap将HashMap包装起来
返回由指定映射支持的同步(线程安全的)映射。为了保证按顺序访问,必须通过返回的映射完成对底层映射的所有访问。在返回的映射或其任意 collection 视图上进行迭代时,强制用户手工在返回的映射上进行同步:
Map m = Collections.synchronizedMap( new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}不遵从此建议将导致无法确定的行为。如果指定映射是可序列化的,则返回的映射也将是可序列化的。
ConcurrentHashMap은 HashMap을 대체합니다
전체 검색 동시성과 원하는 조정 가능한 업데이트 동시성을 지원하는 해시 테이블입니다. 이 클래스는 Hashtable과 동일한 기능 사양을 따르며 Hashtable의 각 메서드에 해당하는 메서드 버전을 포함합니다. 그러나 모든 작업은 스레드로부터 안전하지만 검색 작업은 잠글 필요가 없으며 모든 액세스를 방지하는 방식으로 전체 테이블을 잠그는 것은 지원되지 않습니다. 이 클래스는 동기화 세부 사항과 관계없이 스레드 안전성에 따라 Hashtable과 프로그래밍 방식으로 완전히 상호 운용될 수 있습니다. 검색 작업(가져오기 포함)은 일반적으로 차단되지 않으므로 업데이트 작업(넣기 및 제거 포함)과 겹칠 수 있습니다. 검색은 가장 최근에 완료된 업데이트 작업의 결과에 영향을 미칩니다. putAll 및 Clear와 같은 일부 집계 작업의 경우 동시 검색은 특정 항목의 삽입 및 제거에만 영향을 미칠 수 있습니다. 마찬가지로 반복자와 열거형은 반복자/열거형이 생성된 시점이나 그 이후 특정 시점에 해시 테이블의 상태에 영향을 준 요소를 반환합니다. ConcurrentModificationException을 발생시키지 않습니다. 그러나 반복자는 한 번에 하나의 스레드에서만 사용되도록 설계되었습니다.
위 내용은 Java HashMap의 다중 스레드 동시성 문제를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!