
Java 개발에 일반적으로 사용되는 일반적인 알고리즘은 무엇입니까?

- 王林앞으로
- 2023-05-09 10:04:151741검색
그리디 알고리즘
클래식 애플리케이션: Huffman Coding, Prim 및 Kruskal 최소 스패닝 트리 알고리즘, Dijkstra 단일 소스 최단 경로 알고리즘 등.
문제 해결을 위한 그리디 알고리즘의 단계
첫 번째 단계에서는 이런 종류의 문제를 볼 때 먼저 그리디 알고리즘을 생각해야 합니다. 즉, 데이터 세트에 대해 한계 값과 기대 값을 정의하고 그 중에서 몇 가지 데이터를 선택하기를 바랍니다. 한계값이 충족됩니다. 아래에서는 예상값이 가장 높습니다.
지금 예시에 비유하자면, 제한 값은 무게가 100kg을 초과할 수 없으며 예상 값은 품목의 총 값입니다. 이 데이터 세트는 5종의 콩입니다. 그 중 무게가 100kg을 넘지 않고 총 가치가 가장 높은 부분을 선택합니다.
두 번째 단계에서는 그리디 알고리즘으로 이 문제를 해결할 수 있는지 확인하려고 합니다. 매번 현재 상황에서 기대 값에 가장 많이 기여하는 데이터를 선택하고 한계 값에 동일한 양을 기여합니다. .
지금의 예와 유사하게 매번 남은 원두 중에서 단가가 가장 높은 원두, 즉 무게가 동일할 때 가치에 가장 많이 기여하는 원두를 선택합니다.
세 번째 단계에서는 그리디 알고리즘이 생성한 결과가 최적인지 확인하기 위해 몇 가지 예를 들어 보겠습니다. 대부분의 경우 이를 확인하기 위해 몇 가지 예를 들어보십시오. 그리디 알고리즘의 정확성을 엄격하게 증명하는 것은 매우 복잡하고 많은 수학적 추론이 필요합니다.
그리디 알고리즘이 작동하지 않는 주된 이유는 이전 선택이 다음 선택에 영향을 미치기 때문입니다.
그리디 알고리즘의 실제 분석
1. 사탕을 공유하세요.
우리에게는 m개의 사탕과 n명의 아이들이 있습니다. 이제 이 아이들에게 사탕을 나눠주고 싶지만, 사탕 수가 적고 아이들(m 이 문제를 다음과 같이 추상화할 수 있습니다. n명의 어린이 중에서 사탕을 나눠줄 어린이의 일부를 선택하여 만족하는 어린이의 수(기대값)가 가장 큽니다. 이 문제의 극한값은 사탕의 개수 m입니다.
매번 남은 아이들 중에서 사탕 크기에 대한 수요가 가장 작은 아이를 찾아내고, 그 아이가 만족할 수 있는 가장 작은 사탕을 그에게 줍니다. 이렇게 얻은 분배 계획이 바로 아이 개개인입니다. 가장 많은 옵션이 만족됩니다.
2. 코인 변경
이 문제는 일상 생활에서 더 흔합니다. 1위안, 2위안, 5위안, 10위안, 20위안, 50위안, 100위안 지폐가 있다고 가정해 보겠습니다. 지폐의 숫자는 각각 c1, c2, c5, c10, c20, c50, c100입니다. 이제 이 돈을 사용하여 K 위안을 지불해야 합니다. 사용해야 하는 최소 지폐 수는 얼마입니까?
인생에서는 액면가가 가장 큰 것부터 먼저 지불해야 합니다. 충분하지 않으면 액면가가 더 작은 것을 계속 사용하고 마지막으로 1위안을 사용하여 보충합니다. 나머지. 동일한 기대값(지폐 수)을 기부하는 경우 더 많은 기부를 하여 지폐 수를 줄일 수 있도록 하는 것이 그리디 알고리즘의 솔루션입니다.
3. 간격 취재
n개의 간격이 있고 간격의 시작 및 끝 끝점이 [l1, r1], [l2, r2], [l3, r3], ..., [ln, rn]이라고 가정합니다. 이 n개 간격에서 간격의 일부를 선택합니다. 간격의 이 부분은 두 간격이 교차하지 않는다는 점을 충족합니다(교차하는 끝점은 교차로 간주되지 않음). 최대 몇 개의 간격을 선택할 수 있습니까?
이 처리 아이디어는 작업 스케줄링, 교사 스케줄링 등과 같은 많은 욕심 많은 알고리즘 문제에 사용됩니다.
이 문제에 대한 해결책은 다음과 같습니다. 이 n 간격의 가장 왼쪽 끝점이 lmin이고 가장 오른쪽 끝점이 rmax라고 가정합니다. 이 문제는 여러 개의 분리된 구간을 선택하고 왼쪽에서 오른쪽으로 [lmin, rmax]를 다루는 것과 동일합니다. 우리는 이 n 간격을 작은 시작 끝점부터 큰 시작 끝점 순으로 정렬합니다.
선택할 때마다 왼쪽 끝점은 이전에 덮힌 구간과 일치하지 않고 오른쪽 끝점은 최대한 작아서 나머지 덮이지 않은 구간을 최대한 크게 만들고 더 많은 구간을 배치할 수 있습니다. 이것은 실제로 탐욕스러운 선택 방법입니다.
그리디 알고리즘을 사용하여 허프만 코딩을 구현하는 방법은 무엇입니까?
허프만 코딩은 이러한 비동등 길이 인코딩 방법을 사용하여 문자를 인코딩합니다. 각 문자의 인코딩 사이에는 한 인코딩이 다른 인코딩의 접두사가 되는 상황이 없어야 합니다. 더 자주 나타나는 문자에는 약간 더 짧은 인코딩을 사용하고, 덜 자주 나타나는 문자에는 약간 더 긴 인코딩을 사용합니다.
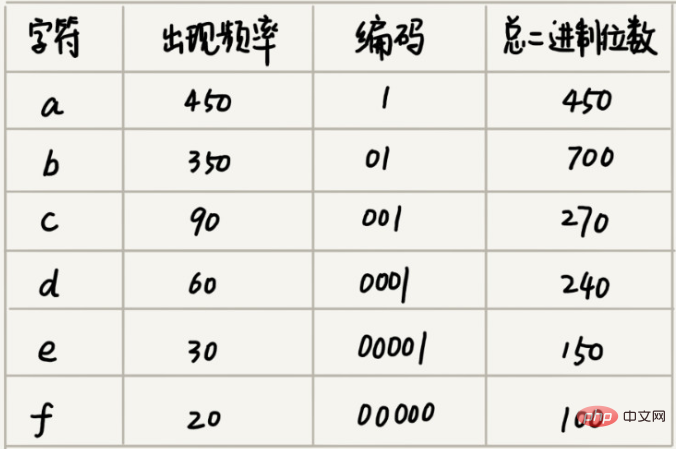
1000자를 포함하는 파일이 있다고 가정합니다. 각 문자는 1바이트(1바이트=8비트)를 차지합니다. 이 1000자를 저장하려면 총 8000비트가 필요합니다.
통계 분석을 통해 이 1000개의 문자에 a, b, c, d, e, f라고 가정할 때 6개의 문자만 포함되어 있다고 가정해 보겠습니다. 3개의 바이너리 비트(bits)는 8개의 서로 다른 문자를 나타낼 수 있으므로 저장 공간을 최소화하기 위해 각 문자를 표현하기 위해 3개의 바이너리 비트를 사용합니다. 그러면 이 1000자를 저장하는 데 3000비트만 필요하므로 원래 저장 방법보다 많은 공간이 절약됩니다. 하지만 이보다 더 공간을 절약하는 저장 방법이 있을까요?
a(000), b(001), c(010), d(011), e(100), f(101)
허프만 코딩은 매우 효과적인 코딩 방법이며 데이터 압축에 널리 사용됩니다. 압축률은 일반적으로 20%에서 90% 사이입니다.
허프만 코딩은 텍스트에 얼마나 많은 문자가 있는지 조사할 뿐만 아니라, 각 문자의 빈도도 조사하고, 빈도에 따라 다양한 길이의 코드를 선택합니다. 허프만 코딩은 이러한 불평등 길이 코딩 방법을 사용하여 압축 효율성을 더욱 높이려고 시도합니다. 빈도가 다른 문자에 대해 길이가 다른 코드를 선택하는 방법은 무엇입니까? 탐욕스러운 생각에 따르면, 더 자주 나타나는 문자에는 약간 더 짧은 코드를 사용할 수 있고, 덜 자주 나타나는 문자에는 약간 더 긴 코드를 사용할 수 있습니다.
코드의 길이가 같지 않습니다. 코드를 읽고 구문 분석하는 방법은 무엇입니까?
동일 길이 인코딩의 경우 압축을 푸는 것은 매우 간단합니다. 예를 들어, 지금 예제에서는 3비트를 사용하여 문자를 나타냅니다. 압축을 풀 때 텍스트에서 3자리 바이너리 코드를 한 번에 읽어 해당 문자로 변환합니다. 그러나 허프만 코드는 매번 1비트를 읽어야 할까요, 아니면 압축을 풀기 위해 2비트, 3비트 등을 읽어야 할까요? 이 문제는 허프만 코딩을 압축 해제하기 더 복잡하게 만듭니다. 압축 해제 과정에서 모호함을 피하기 위해 Huffman 인코딩에서는 각 문자의 인코딩 간에 한 인코딩이 다른 인코딩의 접두사가 되는 상황이 없어야 합니다.
이 6개 문자의 높은 순서에서 낮은 순서의 빈도가 a, b, c, d, e, f라고 가정합니다. 우리는 이를 이렇게 인코딩합니다. 어떤 문자의 인코딩은 다른 문자의 접두사가 아닙니다. 압축을 풀 때마다 가능한 한 긴 압축 해제 가능한 이진 문자열을 읽으므로 모호함이 없습니다. 이 인코딩 및 압축 후에는 이러한 1000자에 2100비트만 필요합니다.
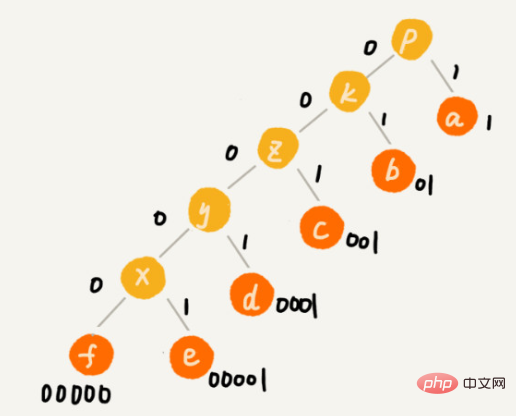
허프만 코딩의 개념은 이해하기 어렵지 않지만, 발생 빈도에 따라 길이가 다른 다양한 문자를 어떻게 인코딩합니까?
큰 상단 스택을 사용하여 빈도에 따라 문자를 배치하세요.
분할 및 정복 알고리즘
분할 정복 알고리즘의 핵심 아이디어는 실제로 네 단어로, 분할 정복, 즉 원래 문제를 원래 문제와 유사한 구조를 가진 n개의 더 작은 하위 문제로 나누고 이러한 하위 문제를 해결합니다. 재귀적으로 수행한 다음 결과를 결합하여 원래 문제에 대한 솔루션을 얻습니다.
분할 정복 알고리즘은 문제 해결 아이디어이고 재귀는 프로그래밍 기술입니다. 실제로 분할 정복 알고리즘은 일반적으로 재귀를 사용하여 구현하는 데 더 적합합니다. 분할 정복 알고리즘의 재귀적 구현에서 각 재귀 수준에는 다음 세 가지 작업이 포함됩니다.
분해: 원래 문제를 일련의 하위 문제로 분해합니다. 해결: 하위 문제가 충분히 작으면 직접 해결합니다. 하위 문제의 결과를 원래 질문으로 결합합니다. 분할 정복 알고리즘이 해결할 수 있는 문제는 일반적으로 다음 조건을 충족해야 합니다.
원래 문제는 분해된 작은 문제와 동일한 패턴을 갖습니다. 원래 문제는 독립적으로 해결될 수 있는 하위 문제로 분해되며 하위 문제 사이에는 상관관계가 없습니다. 분할정복 알고리즘 적용 예시 분석 각 숫자와 그 뒤의 숫자를 비교하여 얼마나 더 작은지 확인하세요. 이보다 작은 숫자의 개수를 k로 기록합니다. 이런 식으로 각 숫자를 조사한 후 각 숫자에 해당하는 k개의 값을 합산하여 얻은 최종 합은 역순으로 쌍의 개수입니다. 그러나 이 연산의 시간 복잡도는 O(n^2)입니다.
배열을 A1과 A2의 두 부분으로 나누고 각각 A1과 A2의 역순 쌍 K1과 K2의 수를 계산한 다음 A1과 A2 사이의 역순 쌍 K3의 수를 계산할 수 있습니다. 그러면 배열 A의 역순 쌍 수는 K1+K2+K3과 같습니다. 병합 정렬 알고리즘의 도움으로
10GB 주문 파일을 금액별로 정렬해야 하나요?
주문을 먼저 스캔한 후 10GB 파일을 주문 금액에 따라 여러 금액 범위로 나눌 수 있습니다. 예를 들어, 1~100위안 사이의 주문 금액은 작은 파일에 배치되고, 101~200위안 사이의 주문 금액은 다른 파일에 배치되는 식입니다. 이러한 방식으로 각 작은 파일을 메모리에 로드하여 별도로 정렬할 수 있으며, 마지막으로 정렬된 작은 파일을 병합하여 최종 정렬된 10GB 주문 데이터를 얻습니다.
역추적 알고리즘
응용 시나리오: 깊이 우선 검색, 정규식 일치, 컴파일 원칙의 구문 분석. 역추적 알고리즘을 사용하여 스도쿠, 여왕 8명, 배낭 0-1, 그래프 색칠, 여행하는 외판원 문제, 총 순열 등과 같은 많은 고전적인 수학 문제를 해결할 수 있습니다.
역추적의 처리 아이디어는 열거형 검색과 다소 유사합니다. 우리는 모든 솔루션을 열거하고 우리의 기대를 충족하는 솔루션을 찾습니다. 가능한 모든 솔루션을 정기적으로 열거하고 누락과 중복을 방지하기 위해 문제 해결 프로세스를 여러 단계로 나눕니다. 각 단계에서 우리는 먼저 무작위로 경로를 선택합니다. 이 경로가 작동하지 않는 경우(예상 솔루션을 충족하지 않음) 도로의 이전 분기점으로 돌아가서 다른 길을 선택하세요.
에잇 퀸즈 문제
8x8 체스판이 있고 그 위에 8개의 체스 말(퀸)을 놓으려고 합니다. 각 체스 말은 행, 열 또는 대각선에 다른 체스 말을 가질 수 없습니다.
1.0-1 백팩
많은 시나리오를 이 문제 모델로 추상화할 수 있습니다. 이 문제에 대한 고전적인 해결책은 동적 프로그래밍이지만 간단하지만 효율성이 떨어지는 솔루션도 있습니다. 바로 오늘 이야기하는 역추적 알고리즘입니다.
백팩이 있는데, 백팩의 총 운반 무게는 Wkg입니다. 이제 우리는 n개의 항목을 가지고 있으며, 각 항목은 서로 다른 가중치를 가지며 분할할 수 없습니다. 이제 몇 가지 항목을 선택하여 배낭에 로드하려고 합니다. 배낭이 지닐 수 있는 무게를 초과하지 않고 배낭에 있는 품목의 총 무게를 최대화하는 방법은 무엇입니까?
각 품목에는 배낭에 넣거나 넣지 않는 두 가지 옵션이 있습니다. n개 품목의 경우 2^n가지 설치 방법이 있습니다. 총 중량이 Wkg을 초과하는 품목을 제거하고 나머지 설치 방법 중에서 총 중량이 Wkg에 가장 가까운 품목을 선택합니다. 그런데 이 2^n가지 척하는 방식을 반복 없이 어떻게 철저하게 열거할 수 있을까요?
역추적 방법: 항목을 순서대로 배열할 수 있으며 전체 문제는 n개의 단계로 분해되며 각 단계는 항목을 선택하는 방법에 해당합니다. 첫 번째 항목을 먼저 처리하고 로드 여부를 선택한 다음 나머지 항목을 재귀적으로 처리합니다.
동적 프로그래밍
동적 프로그래밍은 최대값, 최소값 찾기 등과 같은 최적의 문제를 해결하는 데 더 적합합니다. 시간 복잡성을 크게 줄이고 코드 실행 효율성을 향상시킬 수 있습니다.
0-1 배낭 문제
무게가 다른 분할할 수 없는 품목 세트의 경우 배낭에 넣을 품목을 선택해야 합니다. 배낭의 최대 무게 제한을 충족한다는 전제 하에 배낭에 있는 품목의 최대 총 무게는 얼마입니까?
생각:
(1) 전체 해결 과정을 n단계로 나누고, 각 단계에서 배낭에 물건을 넣을지 여부를 결정합니다. 각 품목이 결정된 후(배낭에 넣을지 여부), 배낭에 있는 품목의 무게는 많은 상황에 처하게 됩니다. 즉, 다음과 같은 다양한 상태에 도달합니다. 재귀 트리, 즉 다양한 노드가 있습니다.
(2) 각 레이어의 반복되는 상태(노드)를 병합하고 서로 다른 상태만 기록한 다음 이전 레이어의 상태 세트를 기반으로 다음 레이어의 상태 세트를 파생합니다. 각 레이어의 반복된 상태를 병합하여 각 레이어의 서로 다른 상태 수가 w(w는 배낭의 운반 무게를 나타냄)(예제에서는 9)를 초과하지 않도록 할 수 있습니다.
n개의 스테이지로 나누어 각 스테이지는 이전 스테이지를 기반으로 파생되며 반복 계산을 피하기 위해 동적으로 진행됩니다.
이 문제를 해결하기 위해 역추적 알고리즘을 사용하는 데 따른 시간 복잡도는 O(2^n)이며 이는 지수적입니다. 그렇다면 동적 프로그래밍 솔루션의 시간 복잡도는 얼마나 됩니까?
가장 시간이 많이 걸리는 부분은 코드의 2단계 for 루프이므로 시간 복잡도는 O(n*w)입니다. n은 물품의 개수를 나타내고, w는 배낭이 운반할 수 있는 총 무게를 나타냅니다. n 곱하기 w+1의 2차원 배열을 추가로 신청해야 하는데, 이는 많은 공간을 소모합니다. 그러므로 때때로 우리는 동적 프로그래밍이 공간과 시간을 교환하는 솔루션이라고 말할 것입니다.
0-1 배낭 문제의 업그레이드 버전
무게와 가치가 다른 분할할 수 없는 품목 세트의 경우 배낭의 최대 무게 제한을 충족한다는 전제 하에 일부 품목을 배낭에 넣기로 선택합니다. 배낭에 짐을 넣었어?
동적 프로그래밍으로 해결하기에 적합한 문제는 무엇인가요?
한 모델의 세 가지 기능
One 모델: 다단계 의사결정 최적 솔루션 모델
세 가지 기능:
최적의 하위 구조, 문제의 최적 솔루션에는 하위 문제의 최적 솔루션이 포함되어 있습니다. 후유증이 없습니다. 첫 번째 의미는 이후 단계의 상태를 도출할 때 이전 단계에만 관심이 있다는 것입니다. 의 상태 값은 이 상태가 단계별로 어떻게 도출되는지 상관하지 않습니다. 두 번째 의미는 특정 단계의 상태가 일단 결정되면 이후 단계의 결정에 영향을 받지 않는다는 것입니다. (후자는 이전 문제에 영향을 미치지 않습니다.) 반복되는 하위 문제, 다른 결정 순서는 특정 동일한 단계에 도달할 때 반복되는 상태를 생성할 수 있습니다. 두 가지 동적 프로그래밍 문제 해결 아이디어 요약
1. 상태 전이 테이블 방법
일반적으로 동적 프로그래밍으로 해결할 수 있는 문제는 역추적 알고리즘을 사용한 무차별 탐색을 통해 해결할 수 있습니다. 재귀 트리를 그립니다. 재귀 트리를 통해 반복되는 하위 문제가 있는지, 그리고 반복되는 하위 문제가 어떻게 생성되는지 쉽게 확인할 수 있습니다.
반복되는 하위 문제를 찾은 후 처리하는 방법에는 두 가지가 있습니다. 첫 번째는 반복되는 하위 문제를 피하기 위해 역추적 및 "메모" 방법을 직접 사용하는 것입니다. 실행 효율성 측면에서는 동적 프로그래밍의 솔루션 아이디어와 다르지 않습니다. 두 번째 방법은 동적 프로그래밍, 상태 전이 테이블 방법을 사용하는 것입니다.
먼저 상태표를 그려보겠습니다. 상태 테이블은 일반적으로 2차원이므로 2차원 배열이라고 생각하면 됩니다. 그 중 각 상태에는 행, 열, 배열 값이라는 세 가지 변수가 포함됩니다. 의사결정 과정, 앞에서 뒤로, 재귀 관계에 따라 단계적으로 상태 테이블의 각 상태를 채웁니다. 마지막으로 이 재귀적 양식 작성 프로세스를 동적 프로그래밍 코드인 코드로 변환합니다.
표현하려면 많은 변수가 필요하며 해당 상태 테이블은 3차원 또는 4차원과 같은 고차원일 수 있습니다. 현재로서는 이를 해결하기 위해 상태 전이 테이블 방법을 사용하는 것이 적합하지 않습니다. 한편으로는 고차원적인 상태전이표를 작성하고 표현하기가 어렵기 때문이고, 다른 한편으로는 인간의 뇌는 고차원적인 것에 대해 생각하는 능력이 정말 부족하기 때문입니다.
2. 상태 전이 방정식 방법
최적하부구조라 불리는 하위 문제를 통해 특정 문제가 어떻게 재귀적으로 해결될 수 있는지 분석해야 합니다. 최적의 하부 구조를 기반으로 소위 상태 전이 방정식인 재귀 공식을 작성합니다. 상태 전이 방정식을 사용하면 코드 구현이 매우 간단합니다. 일반적으로 코드 구현 방법에는 두 가지가 있습니다. 하나는 재귀에 "메모"를 더한 것이고, 다른 하나는 반복 재귀입니다.
min_dist(i, j) = w[i][j] + min(min_dist(i, j-1), min_dist(i-1, j))
모든 문제가 두 문제 해결 아이디어 모두에 적합한 것은 아니라는 점을 강조하고 싶습니다. 어떤 문제는 첫 번째 사고방식을 사용하면 더 명확해질 수 있고, 어떤 문제는 두 번째 사고방식을 사용하면 더 명확해질 수 있습니다. 따라서 어떤 문제 해결 방법을 사용할지는 구체적인 문제를 고려하여 결정해야 합니다. 상태 전이 테이블 방법 문제 해결 아이디어는 대략 다음과 같이 요약할 수 있습니다. 역추적 알고리즘 구현 - 상태 정의 - 재귀 트리 그리기 - 중복 하위 문제 찾기 - 상태 전이 테이블 그리기 - 그에 따라 테이블 채우기 재귀 관계 - 테이블 채우기 프로세스를 코드 로 변환합니다. 상태 전이 방정식 방법의 일반적인 아이디어는 최적의 하위 구조 찾기 - 상태 전이 방정식 작성 - 상태 전이 방정식을 코드로 변환하는 것으로 요약할 수 있습니다.
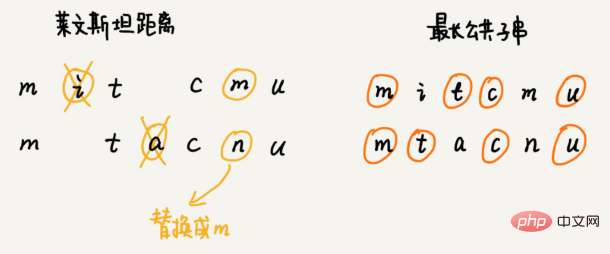
두 문자열의 유사성을 어떻게 수량화할 수 있나요? 편집 거리는 한 문자열을 다른 문자열로 변환하는 데 필요한 편집 작업(예: 문자 추가, 문자 삭제, 문자 바꾸기)의 최소 횟수를 나타냅니다. 편집 거리가 클수록 두 문자열 간의 유사성은 작아지고, 반대로 편집 거리가 작을수록 두 문자열 간의 유사성은 커집니다. 두 개의 동일한 문자열의 경우 편집 거리는 0입니다. 편집 거리를 계산하는 방법은 다양하며 가장 유명한 방법은 Levenshtein 거리 및 가장 긴 공통 부분 문자열 길이입니다. 그 중 레빈스타인 거리는 문자 추가, 삭제, 교체의 세 가지 편집 작업을 허용하며, 가장 긴 공통 부분 문자열의 길이는 문자 추가, 삭제의 두 가지 편집 작업만 허용합니다. Lewenstein 거리와 가장 긴 공통 부분 문자열 길이는 완전히 반대되는 두 가지 관점에서 문자열의 유사성을 분석합니다. Levenstein 거리의 크기는 두 문자열 간의 차이를 나타내며 가장 긴 공통 부분 문자열의 크기는 두 문자열 간의 유사성을 나타냅니다. 두 문자열 mitcmu와 mtacnu의 Levinstein 거리는 3이고, 가장 긴 공통 부분 문자열의 길이는 4입니다. 프로그래밍 방식으로 Levenstein 거리를 계산하는 방법은 무엇입니까? 이 질문은 한 문자열을 다른 문자열로 변경하는 데 필요한 최소 편집 횟수를 찾는 것입니다. 전체 솔루션 프로세스에는 여러 의사결정 단계가 포함됩니다. 문자열의 각 문자가 다른 문자열의 문자와 일치하는지, 일치하면 어떻게 처리할지, 일치하지 않으면 어떻게 처리할지를 차례로 조사해야 합니다. . 따라서 이 문제는 다단계 의사결정 최적해 모델을 따릅니다. 추천 알고리즘 벡터의 거리를 사용하여 유사성을 찾습니다. 검색: A* 검색 알고리즘을 사용하여 게임에서 길 찾기 기능을 구현하는 방법은 무엇입니까? 그럼 최단 경로에 가까운 최적이 아닌 경로를 빠르게 찾는 방법은 무엇일까요? 이 빠른 경로 계획 알고리즘은 오늘 우리가 배울 A* 알고리즘입니다. 실제로 A* 알고리즘은 Dijkstra 알고리즘을 최적화하고 변형한 것입니다. 꼭지점과 끝점 사이의 직선 거리, 즉 유클리드 거리를 사용하여 꼭지점과 끝점 사이의 경로 길이를 대략적으로 추정합니다. (참고: 경로 길이와 직선 거리는 두 가지 개념입니다.) 이 거리는 h(i)(i는 이 꼭지점의 수를 나타냄)로 기록되며 전문적인 이름은 휴리스틱 함수(휴리스틱 함수)입니다. 유클리드 거리 계산 공식에는 루트 기호이므로 일반적으로 또 다른 간단한 거리 계산 공식, 즉 맨해튼 거리(Manhattan distance)를 사용합니다. 맨해튼 거리는 두 점 사이의 수평 좌표와 수직 좌표 사이의 거리의 합입니다. 계산 프로세스에는 덧셈, 뺄셈 및 부호 비트 반전만 포함되므로 유클리드 거리보다 효율적입니다. int hManhattan(Vertex v1, Vertex v2) { // Vertex는 나중에 정의되는 정점을 나타냅니다.
Math.abs(v1.x - v2.x) + Math.abs(v1.y - v2.y)를 반환합니다.
}
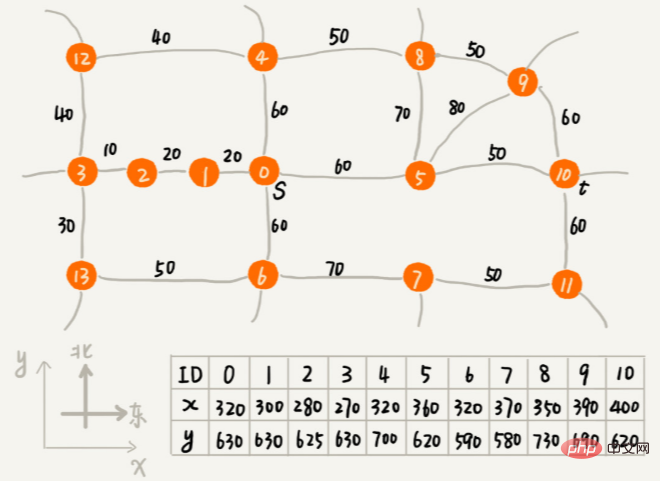
f(i)=g(i)+h(i), 꼭지점과 시작점 사이의 경로 길이 g(i), 꼭지점에서 끝점까지의 예상 경로 길이 h(i)입니다. f(i)의 전문적인 명칭은 평가함수이다. A* 알고리즘은 Dijkstra 알고리즘을 간단히 수정한 것입니다. 가장 작은 f(i)가 먼저 나열됩니다. Dijkstra 알고리즘의 코드 구현과 세 가지 주요 차이점이 있습니다. 우선순위 대기열이 구성되는 방식이 다릅니다. A* 알고리즘은 f 값(즉, 방금 언급한 f(i)=g(i)+h(i))을 기반으로 우선순위 큐를 구축하는 반면, Dijkstra 알고리즘은 dist 값(즉, f(i)=g(i)+h(i))을 기반으로 우선순위 큐를 구축합니다. 즉, 방금 언급한 (i)) 우선순위 큐를 구축하기 위한 것입니다. A* 알고리즘은 정점 dist 값을 업데이트할 때 f 값을 동기적으로 업데이트합니다. 루프 종료 조건은 다음과 같습니다. 또한 다르다. Dijkstra 알고리즘은 끝점이 큐에서 제거되면 종료되고, A* 알고리즘은 순회가 끝점에 도달하면 종료됩니다. 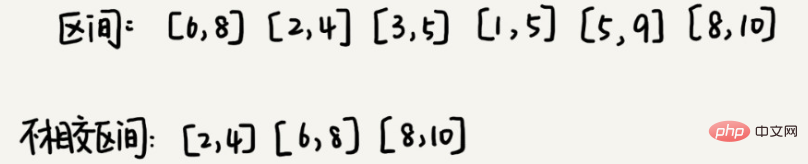
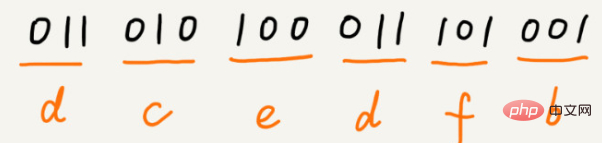
데이터 세트의 순서쌍 또는 역방향 쌍의 수를 찾도록 프로그래밍하는 방법은 무엇입니까?

위 내용은 Java 개발에 일반적으로 사용되는 일반적인 알고리즘은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!