
Java ArrayQueue 소스 코드를 분석합니다.

- PHPz앞으로
- 2023-05-09 08:10:151331검색
ArrayQueue 내부 구현
ArrayQueue의 내부 구현에 대해 이야기하기 전에 먼저 ArrayQueue의 사용 예를 살펴보겠습니다. ArrayQueue的内部实现之前我们先来看一个ArrayQueue的使用例子:
public void testQueue() {
ArrayQueue<Integer> queue = new ArrayQueue<>(10);
queue.add(1);
queue.add(2);
queue.add(3);
queue.add(4);
System.out.println(queue);
queue.remove(0); // 这个参数只能为0 表示删除队列当中第一个元素,也就是队头元素
System.out.println(queue);
queue.remove(0);
System.out.println(queue);
}
// 输出结果
[1, 2, 3, 4]
[2, 3, 4]
[3, 4]首先ArrayQueue内部是由循环数组实现的,可能保证增加和删除数据的时间复杂度都是,不像ArrayList删除数据的时间复杂度为。在ArrayQueue内部有两个整型数据head和tail,这两个的作用主要是指向队列的头部和尾部,它的初始状态在内存当中的布局如下图所示:

因为是初始状态head和tail的值都等于0,指向数组当中第一个数据。现在我们向ArrayQueue内部加入5个数据,那么他的内存布局将如下图所示:
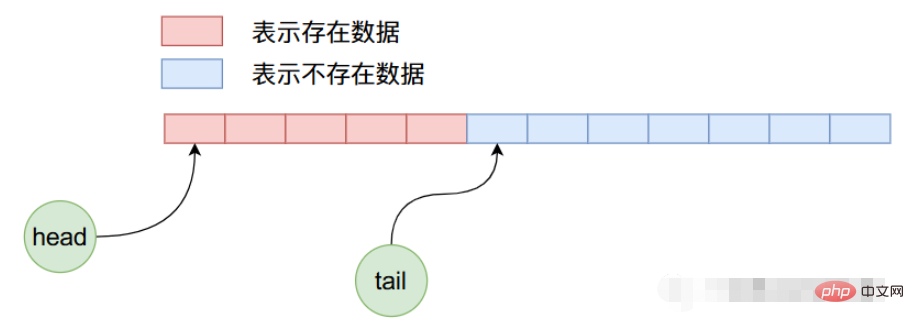
现在我们删除4个数据,那么上图经过4次删除操作之后,ArrayQueue内部数据布局如下:

在上面的状态下,我们继续加入8个数据,那么布局情况如下:

我们知道上图在加入数据的时候不仅将数组后半部分的空间使用完了,而且可以继续使用前半部分没有使用过的空间,也就是说在ArrayQueue内部实现了一个循环使用的过程。
ArrayQueue源码剖析
构造函数
public ArrayQueue(int capacity) {
this.capacity = capacity + 1;
this.queue = newArray(capacity + 1);
this.head = 0;
this.tail = 0;
}
@SuppressWarnings("unchecked")
private T[] newArray(int size) {
return (T[]) new Object[size];
}上面的构造函数的代码比较容易理解,主要就是根据用户输入的数组空间长度去申请数组,不过他具体在申请数组的时候会多申请一个空间。
add函数
public boolean add(T o) {
queue[tail] = o;
// 循环使用数组
int newtail = (tail + 1) % capacity;
if (newtail == head)
throw new IndexOutOfBoundsException("Queue full");
tail = newtail;
return true; // we did add something
}上面的代码也相对比较容易看懂,在上文当中我们已经提到了ArrayQueue可以循环将数据加入到数组当中去,这一点在上面的代码当中也有所体现。
remove函数
public T remove(int i) {
if (i != 0)
throw new IllegalArgumentException("Can only remove head of queue");
if (head == tail)
throw new IndexOutOfBoundsException("Queue empty");
T removed = queue[head];
queue[head] = null;
head = (head + 1) % capacity;
return removed;
}从上面的代码当中可以看出,在remove函数当中我们必须传递参数0,否则会抛出异常。而在这个函数当中我们只会删除当前head下标所在位置的数据,然后将head的值进行循环加1操作。
get函数
public T get(int i) {
int size = size();
if (i < 0 || i >= size) {
final String msg = "Index " + i + ", queue size " + size;
throw new IndexOutOfBoundsException(msg);
}
int index = (head + i) % capacity;
return queue[index];
}get函数的参数表示得到第i个数据,这个第i个数据并不是数组位置的第i个数据,而是距离head位置为i的位置的数据,了解这一点,上面的代码是很容易理解的。
resize函数
public void resize(int newcapacity) {
int size = size();
if (newcapacity < size)
throw new IndexOutOfBoundsException("Resizing would lose data");
newcapacity++;
if (newcapacity == this.capacity)
return;
T[] newqueue = newArray(newcapacity);
for (int i = 0; i < size; i++)
newqueue[i] = get(i);
this.capacity = newcapacity;
this.queue = newqueue;
this.head = 0;
this.tail = size;
}在resize函数当中首先申请新长度的数组空间,然后将原数组的数据一个一个的拷贝到新的数组当中,注意在这个拷贝的过程当中,重新更新了head与tail,而且并不是简单的数组拷贝,因为在之前的操作当中headrrreee
ArrayQueue는 내부적으로 순환 배열로 구현되어 ArrayList의 데이터 삭제 시간 복잡도와 달리 데이터 추가 및 삭제 시간 복잡도가 동일하도록 보장할 수 있습니다. ArrayQueue에는 두 개의 정수 데이터 head와 tail가 있습니다. 이 두 가지의 기능은 주로 대기열의 머리와 꼬리를 가리키는 것입니다. 메모리의 초기 상태 레이아웃은 다음과 같습니다. 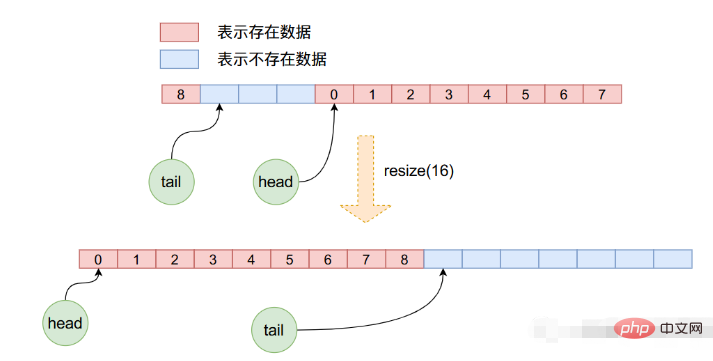
head와 tail의 값이 모두 0이고 배열의 첫 번째 데이터를 가리키기 때문입니다. 이제 ArrayQueue에 5개의 데이터를 추가하면 메모리 레이아웃은 아래와 같습니다: 🎜🎜🎜🎜이제 4개의 데이터를 삭제하고, 위 그림에서 4개의 데이터를 삭제한 후 ArrayQueue의 내부 데이터 레이아웃은 다음과 같습니다. :🎜🎜🎜🎜위 상태에서, 계속해서 8개의 데이터를 추가하면 레이아웃은 다음과 같습니다: 🎜🎜ArrayQueue 내부에 재활용 프로세스가 구현됩니다. 🎜🎜ArrayQueue 소스 코드 분석🎜생성자
rrreee🎜 위 생성자의 코드는 비교적 이해하기 쉽습니다. 그러나 주로 사용자가 입력하는 배열 공간의 길이를 기준으로 하는 배열에 적용됩니다. 배열을 신청할 때 더 구체적입니다. 🎜함수 추가
rrreee🎜위 코드는 비교적 이해하기 쉽습니다. 위에서ArrayQueue가 루프의 배열에 데이터를 추가할 수 있다고 언급했습니다. 위의 코드. 🎜remove 함수
rrreee🎜위 코드에서 볼 수 있듯이remove 함수에 매개변수 0을 전달해야 합니다. 그렇지 않으면 예외가 발생합니다. 이 함수에서는 현재 head 첨자 위치의 데이터만 삭제한 다음 head 값에 대해 1씩 주기적으로 증가시킵니다. 🎜get 함수
rrreee🎜get 함수의 매개변수는 i번째 데이터를 얻었음을 나타내고, i번째 데이터는 배열 위치의 i번째 데이터가 아니고, head 위치에서 i 위치에 있는 데이터입니다. 이를 이해하면 위 코드는 매우 이해하기 쉽습니다. 🎜크기 조정 함수
rrreee🎜크기 조정 함수에서는 먼저 새로운 길이의 배열 공간을 적용한 후 원래 배열의 데이터를 새 배열에 하나씩 복사합니다. 복사 과정에서 head와 tail이 다시 업데이트되며, head가 그럴 수도 있기 때문에 단순한 배열 복사가 아닙니다. 이전 작업 중에 복사되었습니다. 0이 아니므로 새 복사본을 사용하려면 이전 배열에서 하나씩 가져온 다음 새 배열에 넣어야 합니다. 아래 그림에서는 이 과정을 명확하게 볼 수 있습니다. 🎜🎜🎜🎜위 내용은 Java ArrayQueue 소스 코드를 분석합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!