
Java에서 블룸 필터를 구현하는 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-08 22:16:381233검색
블룸 필터란?
블룸 필터는 1970년 Bloom이 제안한 것입니다. 실제로는 매우 긴 이진 배열 + 일련의 해시 알고리즘 매핑 함수로 구성되며, 이는 집합에 요소가 존재하는지 확인하는 데 사용됩니다.
Bloom 필터를 사용하여 요소가 컬렉션에 있는지 검색할 수 있습니다. 장점은 일반 알고리즘에 비해 공간 효율성과 쿼리 시간이 훨씬 좋다는 점이다. 단점은 일정 수준의 오인식률과 삭제가 어렵다는 점이다.
Scenario
10억 개의 휴대전화 번호가 있다고 가정하고, 그 목록에 특정 휴대전화 번호가 있는지 판단해 보세요.
mysql은 괜찮나요?
일반적인 상황에서 데이터의 양이 크지 않다면 mysql 스토리지 사용을 고려할 수 있습니다. 모든 데이터를 데이터베이스에 저장한 다음 데이터베이스를 쿼리하여 해당 데이터가 존재하는지 확인합니다. 그러나 데이터 양이 너무 많아 수천만 개를 초과하면 MySQL 쿼리 효율성이 매우 낮아져 특히 성능이 소모됩니다.
HashSet은 괜찮나요?
데이터를 HashSet에 넣고 HashSet의 자연적인 중복 제거 기능을 활용할 수 있습니다. 그러나 쿼리는 포함 메소드만 호출하면 됩니다. 그러나 데이터 양이 너무 많으면 해시세트가 메모리에 저장됩니다. 기억이 직접적으로 떠오를 것입니다.
블룸 필터의 특징
삽입과 쿼리가 효율적이고 공간을 덜 차지하지만 반환되는 결과가 불확실합니다.
요소가 존재한다고 판단되면 실제로는 존재하지 않을 수도 있습니다. 그러나 요소가 존재하지 않는다고 판단되면 존재하지 않아야 한다.
블룸 필터는 요소를 추가할 수 있지만 요소를 삭제해서는 안 됩니다 . 그러면 오탐률이 높아집니다.
블룸 필터의 원리
블룸 필터는 실제로 BIT 배열로, 일련의 해시 알고리즘을 통해 해당 해시를 매핑한 후 해당 해시에 해당하는 배열 첨자 위치를 1로 변경합니다. 쿼리할 때 데이터에 대해 일련의 해시 알고리즘을 수행하여 첨자를 얻습니다. 1이면 데이터가 존재할 수 있음을 의미합니다. 오류율이 존재하는 이유는 무엇입니까? Bloom 필터가 실제로 데이터를 해시한다는 것을 알고 있으므로 어떤 알고리즘을 사용하더라도 두 개의 서로 다른 데이터에서 생성된 해시가 실제로 동일할 수 있습니다. 이를 종종 해시 충돌이라고 합니다. . 첫 번째 데이터 삽입: 기술을 잘 배우세요
데이터 삽입: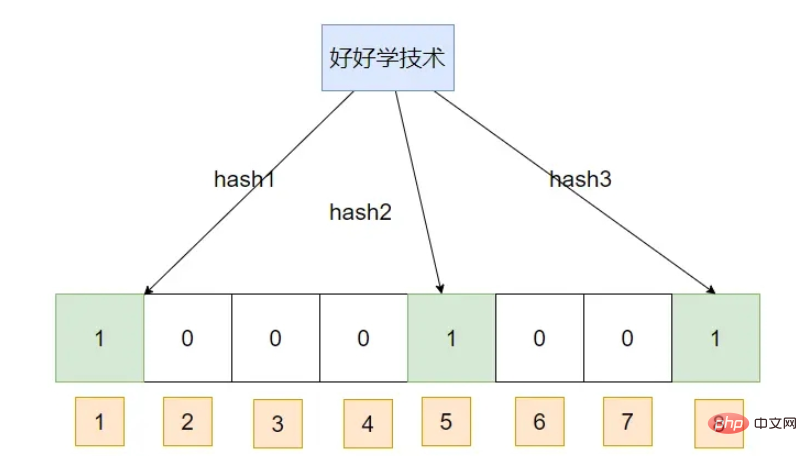
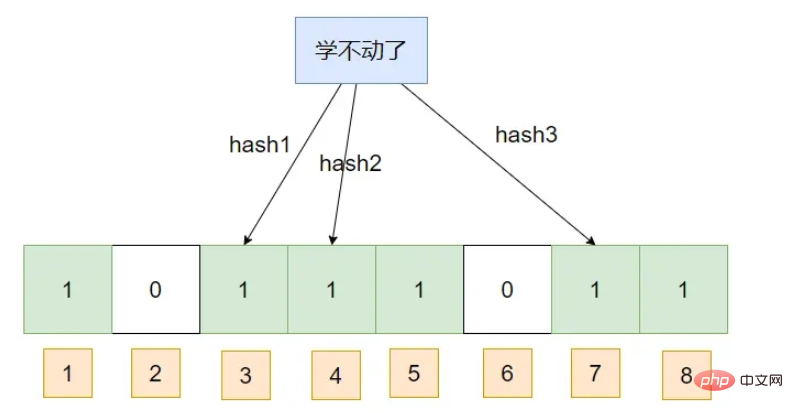
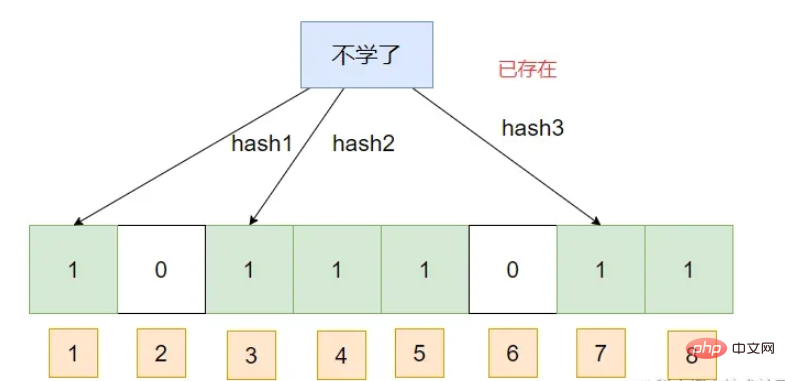 Java는 Bloom 필터를 구현합니다
Java는 Bloom 필터를 구현합니다
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}Guava는 Bloom 필터를 구현합니다
종속성 소개
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
}hutool은 Bloom 필터를 구현합니다
소개 종속성
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>package com.fandf.test.redis;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.bloomfilter.BloomFilterUtil;
/**
* @author fandongfeng
*/
public class HutoolBloomFilter {
public static void main(String[] args) {
BitMapBloomFilter bloomFilter = BloomFilterUtil.createBitMap(1000);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}Redisson은 Bloom 필터를 구현합니다
종속성 소개
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.20.0</version>
</dependency>package com.fandf.test.redis;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* Redisson 实现布隆过滤器
* @author fandongfeng
*/
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("name");
//初始化布隆过滤器:预计元素为100000000L,误差率为1%
bloomFilter.tryInit(100000000L,0.01);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}위 내용은 Java에서 블룸 필터를 구현하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
관련 기사
더보기- Java의 클래스로드 메커니즘은 다른 클래스 로더 및 대표 모델을 포함하여 어떻게 작동합니까?
- 적절한 버전 및 종속성 관리로 Custom Java 라이브러리 (JAR Files)를 작성하고 사용하려면 어떻게해야합니까?
- 캐싱 및 게으른 하중과 같은 고급 기능을 사용하여 객체 관계 매핑에 JPA (Java Persistence API)를 어떻게 사용하려면 어떻게해야합니까?
- 카페인 또는 구아바 캐시와 같은 라이브러리를 사용하여 자바 애플리케이션에서 다단계 캐싱을 구현하려면 어떻게해야합니까?
- 고급 Java 프로젝트 관리, 구축 자동화 및 종속성 해상도에 Maven 또는 Gradle을 어떻게 사용합니까?