
Zhu Jun 팀은 Tsinghua University에서 Transformer를 기반으로 한 최초의 대규모 다중 모드 확산 모델을 오픈 소스화했으며 텍스트와 이미지 재작성 후 완전히 완성되었습니다.

- PHPz앞으로
- 2023-05-08 20:34:081498검색
GPT-4가 이번 주에 출시될 예정이며, 다중 모드가 그 하이라이트 중 하나가 될 것이라고 합니다. 현재의 대형 언어 모델은 다양한 양상을 이해하기 위한 보편적인 인터페이스가 되고 있으며 다양한 모달 정보를 기반으로 응답 텍스트를 제공할 수 있습니다. 그러나 대형 언어 모델에서 생성되는 콘텐츠는 텍스트로만 제한됩니다. 반면, 현재의 확산 모델인 DALL・E 2, Imagen, Stable Diffusion 등은 시각적 창작에 혁명을 일으켰으나 이들 모델은 텍스트에서 이미지까지 단일 크로스 모달 기능만 지원하며 아직까지는 갈 길이 멀다. 보편적인 생성 거리에서. 다중 모드 대형 모델은 다양한 양식의 기능을 개방하고 모든 양식 간의 전환을 실현할 수 있으며, 이는 범용 생성 모델의 향후 개발 방향으로 간주됩니다.
칭화대학교 컴퓨터과학과 Zhu Jun 교수가 이끄는 TSAIL 팀은 최근 "One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale"이라는 논문을 발표했습니다. 다중 모드 생성 모델은 모든 모드 간의 상호 변환을 실현합니다.

논문 링크: https://ml.cs.tsinghua.edu.cn/diffusion/unidiffuser.pdf
오픈 소스 코드: https://github .com/thu-ml/unidiffuser
본 논문은 멀티모달리티를 위해 설계된 확률론적 모델링 프레임워크인 UniDiffuser를 제안하고, 팀이 제안하는 Transformer 기반 네트워크 아키텍처 U-ViT를 오픈소스 대규모 환경에서 채택합니다. 축척 그래프 10억 개의 매개변수가 있는 모델이 문헌 데이터 세트 LAION-5B에서 훈련되어 기본 모델이 고품질로 다양한 생성 작업을 완료할 수 있게 되었습니다(그림 1). 간단히 말하면, 단방향 텍스트 생성 외에도 이미지 생성, 이미지와 텍스트 결합 생성, 무조건적인 이미지와 텍스트 생성, 이미지와 텍스트 재작성 등 다양한 기능을 실현할 수 있어 생산이 크게 향상됩니다. 텍스트 및 이미지 콘텐츠의 효율성을 높이고 텍스트 및 그래픽 생성을 더욱 향상시킵니다. 수식 모델의 응용 상상력.
이 논문의 첫 번째 저자인 Bao Fan은 현재 Analytic-DPM의 이전 제안자였습니다. 그는 ICLR 2022 우수 논문상을 수상했습니다(현재는 독립적으로 완성된 유일한 수상 논문). 본토 단위) 확산 모델 분야에서 뛰어난 성과를 거두었습니다.
또한, Machine Heart는 이전에 TSAIL 팀이 제안한 DPM-Solver 고속 알고리즘에 대해 보고했는데, 이는 여전히 확산 모델을 위한 가장 빠른 생성 알고리즘입니다. 다중 모드 대형 모델은 팀이 장기적으로 심층적으로 축적한 알고리즘과 심층 확률 모델의 원리를 집중적으로 표시한 것입니다. 이 작업의 공동 작업자로는 Renmin University Hillhouse 인공 지능 학교의 Li Chongxuan, Beijing Zhiyuan Research Institute의 Cao Yue 등이 있습니다.

이 프로젝트의 논문과 코드가 오픈 소스라는 점은 주목할 가치가 있습니다.
효과 표시
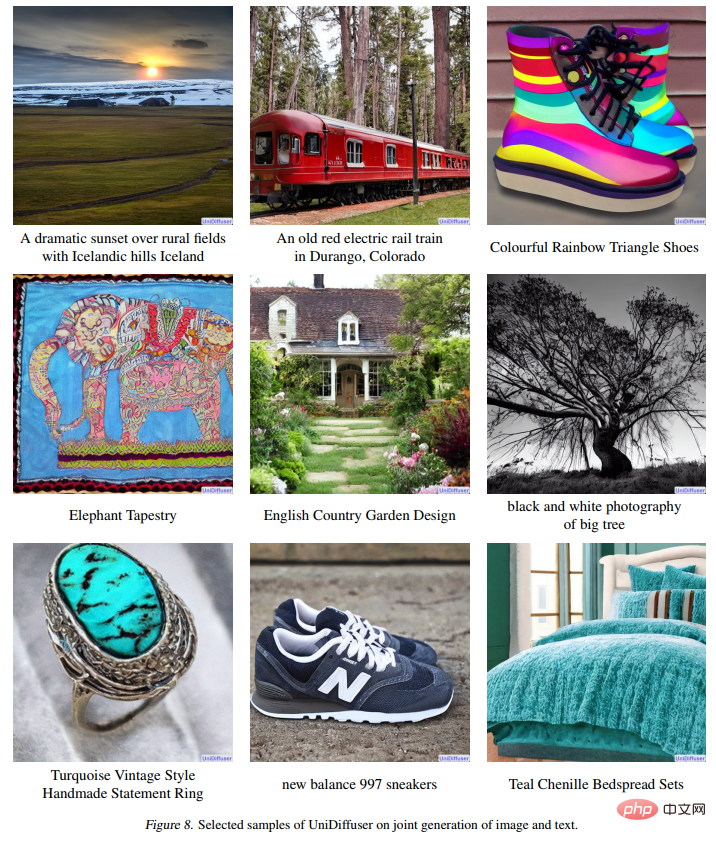
다음 그림 8은 이미지와 텍스트의 공동 생성에 대한 UniDiffuser의 효과를 보여줍니다.
다음 그림 9는 텍스트-이미지에 대한 UniDiffuser의 효과를 보여줍니다. 생성:

다음 그림 10은 이미지-텍스트 변환에 대한 UniDiffuser의 효과를 보여줍니다.

다음 그림 11은 무조건적인 이미지 생성에 대한 UniDiffuser의 효과를 보여줍니다.

다음 그림 12는 이미지 재작성에 대한 UniDiffuser의 효과를 보여줍니다.

다음 그림 15는 UniDiffuser가 이미지와 텍스트의 두 가지 모드 사이를 앞뒤로 이동할 수 있음을 보여줍니다.

아래 그림 16과 같이 UniDiffuser는 두 개의 실제 이미지를 보간할 수 있습니다.
방법 개요
연구팀은 일반 생성 모델의 설계를 두 가지 하위 문제로 나누었습니다.
- 확률적 모델링 프레임워크: 한계 분포, 조건부 분포, 이미지와 텍스트 간의 결합 분포 등 모드 간 모든 분포를 동시에 모델링할 수 있는 확률적 모델링 프레임워크를 찾을 수 있습니까?
- 네트워크 아키텍처: 다양한 입력 양식을 지원하도록 통합 네트워크 아키텍처를 설계할 수 있습니까?
확률적 모델링 프레임워크
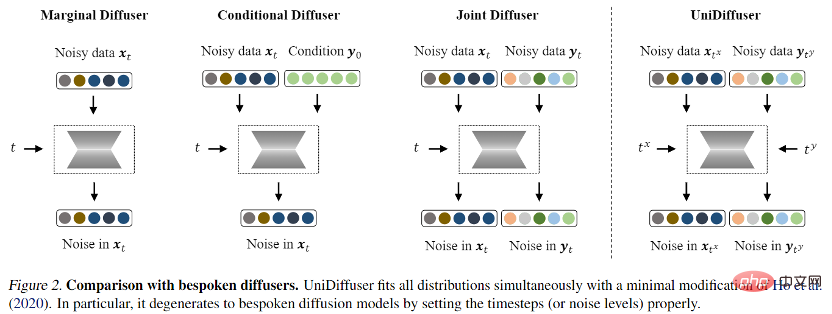
확률적 모델링 프레임워크로 연구팀은 확산 모델 기반의 확률적 모델링 프레임워크인 UniDiffuser를 제안했습니다. UniDiffuser는 한계 분포, 조건 분포 및 결합 분포를 포함하여 다중 모드 데이터의 모든 분포를 명시적으로 모델링할 수 있습니다. 연구팀은 서로 다른 분포에 대한 확산 모델 학습이 하나의 관점으로 통합될 수 있다는 사실을 발견했습니다. 먼저 두 양식의 데이터에 일정 크기의 노이즈를 추가한 다음 두 양식의 데이터에 대한 노이즈를 예측하는 것입니다. 두 모달 데이터의 노이즈 양에 따라 특정 분포가 결정됩니다. 예를 들어, 텍스트의 노이즈 크기를 0으로 설정하는 것은 빈첸시안 다이어그램의 조건부 분포에 해당하고, 텍스트의 노이즈 크기를 최대값으로 설정하는 것은 이미지의 노이즈 크기를 무조건적으로 설정하는 것에 해당합니다. 동일한 값의 텍스트는 이미지와 텍스트의 공동 분포에 해당합니다. 이러한 통합된 관점에 따르면 UniDiffuser는 위의 모든 분포를 동시에 학습하기 위해 원래 확산 모델의 훈련 알고리즘을 약간 수정하기만 하면 됩니다. 아래 그림에 표시된 것처럼 UniDiffuser는 동시에 모든 모드에 노이즈를 추가합니다. 단일 모드 대신 모든 모드에 해당하는 노이즈 크기와 모든 모드에서 예상되는 노이즈를 입력합니다.
바이모달 모드를 예로 들면, 최종 학습 목적 함수는 다음과 같습니다.
는 데이터를 나타냅니다.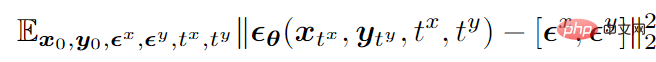
은 두 모드에 추가된 표준 가우스 노이즈를 나타내고,

은 두 모드에 추가된 노이즈의 크기(즉, 시간)를 나타내며, 두 개는 { 1, 2,…,T} 중간 샘플링,

은 두 가지 양식에 대한 잡음을 동시에 예측하는 잡음 예측 네트워크입니다.
훈련 후 UniDiffuser는 소음 예측 네트워크에 두 모드에 대한 적절한 시간을 설정하여 무조건, 조건부 및 공동 생성을 달성할 수 있습니다. 예를 들어, 텍스트 시간을 0으로 설정하면 텍스트-이미지 생성이 가능하며, 텍스트 시간을 최대값으로 설정하면 이미지와 텍스트의 시간을 동일한 값으로 설정하면 무조건 이미지 생성이 가능합니다. 이미지와 텍스트의 공동 생성.
UniDiffuser의 훈련 및 샘플링 알고리즘은 다음과 같습니다. 이러한 알고리즘은 원래 확산 모델에 비해 약간만 변경되었으며 구현하기 쉽다는 것을 알 수 있습니다.

또한 UniDiffuser는 조건부 분포와 무조건 분포를 모두 모델링하기 때문에 UniDiffuser는 자연스럽게 분류자 없는 안내를 지원합니다. 아래 그림 3은 다양한 지침 규모에 따른 UniDiffuser의 조건부 생성과 결합 생성의 효과를 보여줍니다.

Network Architecture
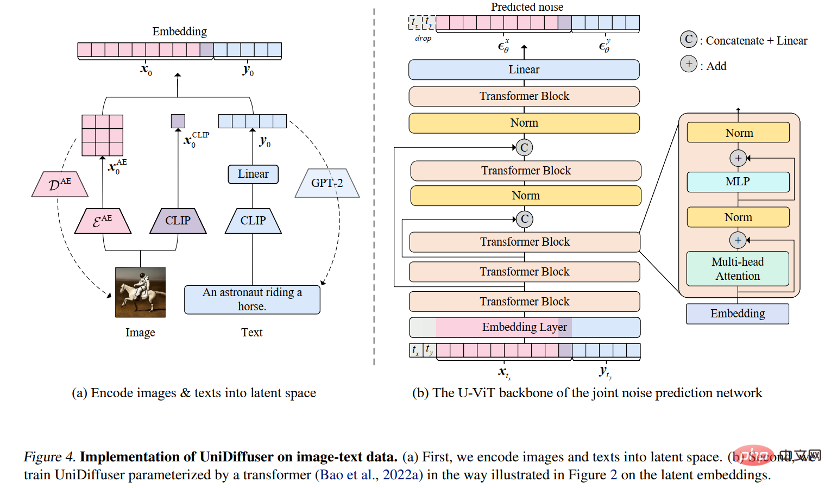
네트워크 아키텍처의 경우, 연구팀은 Transformer 기반 아키텍처를 사용할 것을 제안했습니다. 잡음 예측 네트워크를 매개변수화합니다. 구체적으로 연구팀은 최근 제안된 U-ViT 아키텍처를 채택했다. U-ViT는 모든 입력을 토큰으로 처리하고 변압기 블록 사이에 U자형 연결을 추가합니다. 연구팀은 또한 다양한 양식의 데이터를 잠재 공간으로 변환한 후 확산 모델을 모델링하기 위해 Stable Diffusion 전략을 채택했습니다. U-ViT 아키텍처도 이 연구팀에서 제공되었으며 https://github.com/baofff/U-ViT에서 오픈 소스로 공개되었다는 점은 주목할 가치가 있습니다.
실험 결과
UniDiffuser는 먼저 Versatile Diffusion과 비교했습니다. Versatile Diffusion은 다중 작업 프레임워크를 기반으로 하는 과거의 다중 모드 확산 모델입니다. 먼저 UniDiffuser와 Versatile Diffusion의 텍스트-이미지 효과를 비교했습니다. 아래 그림 5에서 볼 수 있듯이 UniDiffuser는 다양한 분류 없는 안내 척도에서 CLIP 점수와 FID 측정 항목 모두에서 Versatile Diffusion보다 우수합니다.
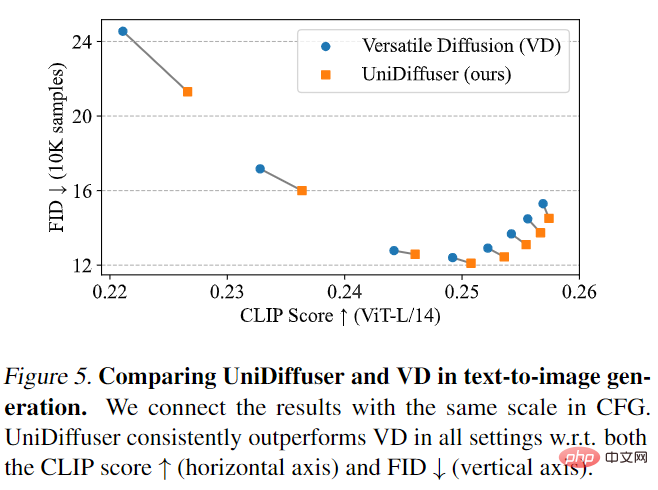
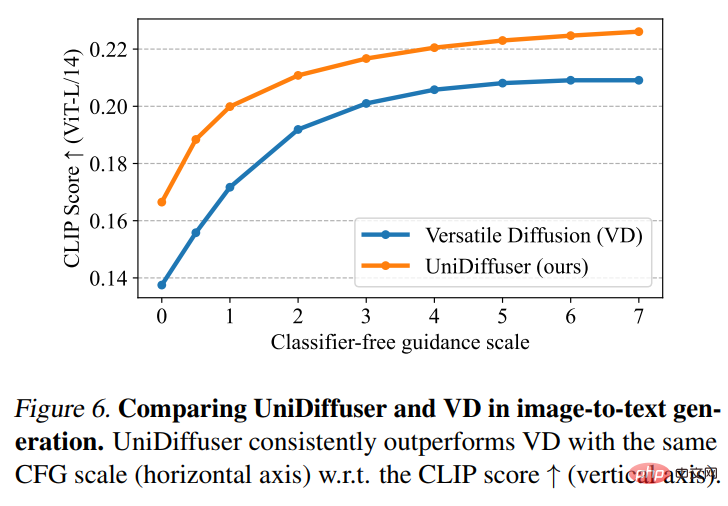
그런 다음 UniDiffuser와 Versatile Diffusion은 그림-텍스트 효과 비교를 수행했습니다. 아래 그림 6에서 볼 수 있듯이 UniDiffuser는 이미지-텍스트에서 더 나은 CLIP 점수를 갖습니다.
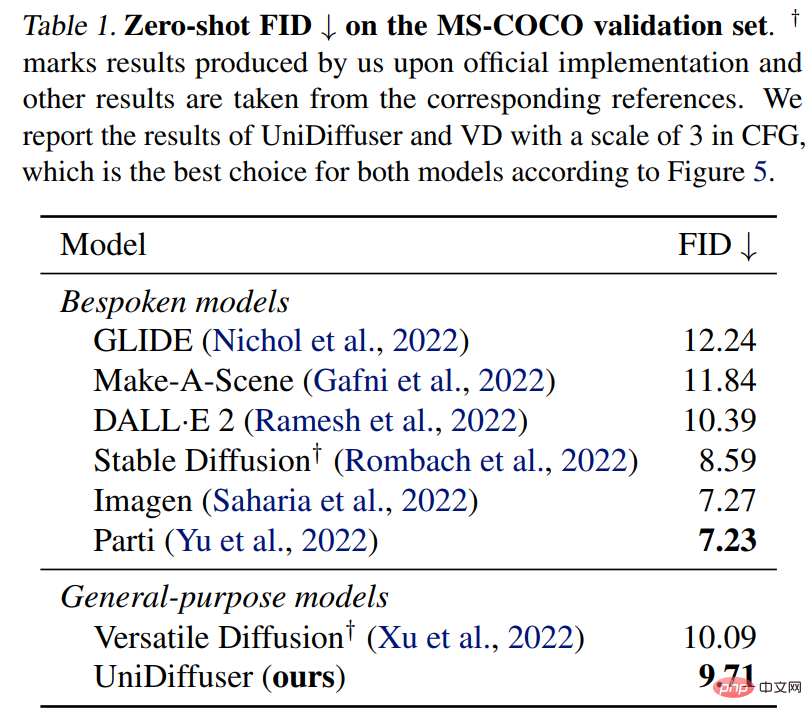
UniDiffuser는 MS-COCO의 제로샷 FID를 위한 전용 텍스트-그래프 모델과도 비교됩니다. 아래 표 1에서 볼 수 있듯이 UniDiffuser는 전용 텍스트-그래프 모델과 비슷한 결과를 얻을 수 있습니다.
위 내용은 Zhu Jun 팀은 Tsinghua University에서 Transformer를 기반으로 한 최초의 대규모 다중 모드 확산 모델을 오픈 소스화했으며 텍스트와 이미지 재작성 후 완전히 완성되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!