




소개: 이 공유의 제목은 약물 추천 시스템에 그래프 표현 학습 기술을 적용하는 것입니다.
주로 다음 네 부분으로 구성됩니다.
- 연구 배경 및 과제
- 차별 약물 패키지 권장
- 추천 생식의학 패키지
- 요약 및 전망
1. 연구배경 및 과제
1. 연구배경
- 전반적인 의료자원 부족과 불균등한 분포로 인한 큰 부담
의약품 추천은 스마트 의료의 하위 문제로, 우리나라에서는 인구가 증가하고 인구가 고령화됨에 따라 고품질 의료에 대한 요구가 시급한 상황입니다. 의료 서비스가 계속해서 증가하고 있습니다. 그림에는 두 가지 데이터가 있습니다. 첫째, 전국 의료기관 방문 건수는 60억 5천만 건으로 전년 대비 22.4% 증가했습니다. 둘째, The Lancet의 여러 국가의 의료 및 건강 상태에 대한 통계입니다. 의사를 포함해 중국 의사 중 학사 학위 이상 소지자는 57.4%에 불과합니다. 간호사, 지역사회 보건 종사자를 포함한 16개 보건 직종의 10,000명당 의사 수는 중국의 3분의 1에 불과합니다. 미국. 우리나라의 진단 및 치료인구는 지속적으로 증가하고 있으나, 선진국에 비해 의료자원과 의료수준이 여전히 부족하며, 의료자원의 불평등한 분배 문제도 존재한다. 1차 의료기관의 의료수준은 상대적으로 제한적이며, 최상위 의료기관의 공급이 수요를 초과하고 있다. 따라서 상급 의료기관의 진단 및 치료 경험을 어떻게 활용하여 일차의료기관의 의료수준 향상에 도움이 되는지가 시급히 해결되어야 할 중요한 문제이다.
- 스마트 의료, 인공지능 기술이 새벽을 가져왔습니다
최근 몇 년간 의료기관의 디지털화가 가속화되면서 우리나라의 의료기관이 특히 많아지고 있습니다. 3차병원 등 수준 높은 의료기관에서는 매우 풍부한 전자의무기록 데이터가 축적되어 있습니다. 빅데이터 인공지능 기술을 활용해 이러한 정보를 완벽하게 마이닝하고 관련 지식을 추출할 수 있다면, 이들 고위 기관 의료 전문가들의 진단 및 치료 방법과 아이디어를 일부 이해하고 스마트한 후속 조치를 지원하는 데 도움이 될 수 있습니다. 방문, 의료 영상 분석, 만성 질환 추적 관찰 등 일련의 다운스트림 스마트 의료 애플리케이션이 중요한 의미를 갖습니다.
2. 연구 과제
의료 AI 기술이 점점 더 광범위하게 적용되고 있으며 이는 의료 서비스의 공정성과 포용성을 촉진합니다. 의료영상 분석 등 일부 AI 기술은 인상적인 결과를 얻었지만 약품 추천 시스템에서는 거의 사용되지 않는데, 그 이유는 약품 추천 시스템이 기존 추천 시스템과 매우 다르고 기술적인 문제도 많고 어려움이 많기 때문입니다. .
- 패키지 추천 시스템

첫 번째 과제는 협업 필터링과 같은 방법을 기반으로 하는 전통적인 추천 시스템의 적용 시나리오가 주로 한 사용자에게 한 번에 하나의 항목을 추천하는 것입니다. 입력은 단일 항목과 단일 사용자의 표현이고, 출력은 둘 사이의 일치 정도에 대한 점수입니다. 그러나 약물 추천에서 의사는 환자에게 한 번에 여러 약물을 처방해야 하는 경우가 많습니다. 약품 추천 시스템은 실제로 사용자에게 한 세트의 약품을 추천하는 패키지 추천 시스템, 즉 패키지 추천 시스템이다. 약물 추천과 패키지 추천 시스템을 결합하는 방법은 우리가 직면한 첫 번째 큰 과제입니다.
- 약물간 상호작용

약물 추천 시스템의 두 번째 과제는 약물 간의 다양한 상호 작용입니다. 일부 약물 간에는 서로의 효과를 촉진하는 시너지 효과가 있고, 일부 약물 간에는 서로의 효과를 상쇄하는 길항작용이 있습니다. 일부 약물을 조합하더라도 독성이나 기타 부작용이 발생할 수 있습니다. 사진의 환자는 일종의 신장 질환을 앓고 있습니다. 왼쪽 부분은 의사가 환자에게 처방한 약품 중 일부는 시너지 효과가 있고 약의 효과를 촉진할 수 있는 약품을 보여줍니다. 오른쪽 부분은 통계적으로 분석된 증상이 있는 고주파 약물을 보여줍니다. 아래의 약물은 일부 기존 약물에 독성이 있을 수 있어 본 환자에서는 사용하지 않는 것으로 보입니다.
또한 약물 상호작용 효과는 개별화되어 있습니다. 우리는 길항 효과나 독성 효과가 있는 다수의 약물이 동시에 사용된다는 통계를 발견했습니다. 분석에 따르면 의사들은 실제로 환자의 상태와 상호작용 효과를 고려하여 약을 처방하고 있다. 예를 들어, 신장이 건강한 일부 환자는 일정량의 약물 신독성을 견딜 수 있는 경우가 많으므로 약물 간 상호 작용에 대한 맞춤형 모델링 및 분석을 수행해야 합니다.
3. 그래프 표현 학습 기술이 새로운 가능성이 되었습니다

결론적으로, 그래프 표현 학습 기술은 위의 과제와 결합하여 약물 추천 시스템에 존재하는 문제를 해결하는 데 매우 적합합니다. . 그래프 신경망의 급속한 발전으로 사람들은 그래프 신경망 기술이 노드 간의 결합 효과와 노드 간의 관계를 매우 효과적으로 모델링할 수 있다는 것을 깨닫습니다. 이는 그래프 표현 학습 기술이 약물 추천 시스템을 구축하는 데 유용한 도구가 될 수 있다는 점을 시사합니다. 날카로운 도구.
예를 들어 그림에서 약물 패키지 내의 상호 작용을 기반으로 약물 패키지를 그래프로 구성하고 기존 그래프 신경망을 통해 모델링할 수 있습니다. 위의 아이디어를 바탕으로 그래프 딥러닝 기술을 사용하여 약물 추천 시스템에 대한 두 가지 작업을 수행했으며 각각 WWW 및 TOIS 저널에 게재되었습니다.
2. 판별식 약 패키지 추천
먼저, WWW2021에 게재된 약 패키지 추천에 관한 논문을 소개하겠습니다. 본 논문에서는 패키지 추천 시스템에서 널리 사용되는 판별적 모델 정의 방법을 모델링에 채택하고, 그래프 표현 학습 기술도 핵심 기술 부분으로 활용한다.
1. 데이터 설명
- 전자 케이스 데이터

먼저 작업에 사용된 데이터 설명을 소개합니다.
우리가 연구 작업에 사용한 전자 의료 기록은 대규모 3차 병원의 실제 전자 의료 기록 데이터베이스에서 가져온 것입니다. 각 전자 의료 기록에는 다음과 같은 유형의 정보가 포함됩니다. 환자의 연령, 성별, 의료 보험 등 두 번째는 의사가 우려하는 검사 결과의 이상과 이상 유형(높음, 낮음, 양성 등)을 포함한 환자의 검사실 정보입니다. 세 번째는 의사가 환자를 위해 작성한 상태 설명입니다. 여기에는 환자가 병원에 입원한 이유, 예비 신체 검사, 그리고 마지막으로 의사가 환자에게 처방한 약품 등의 정보가 포함됩니다.
이 전자의무기록 데이터는 연령, 성별, 실험실 검사 등의 구조화된 정보와 질병 설명 등의 비구조화된 텍스트 정보를 포함하는 이질적인 데이터입니다.
- 약물 데이터

약물 간 상호 작용을 연구하기 위해 우리는 두 개의 대규모 온라인 오픈 소스 약물 지식 기반인 DrugBank와 Pharmaceutical Network에서 몇 가지 약물 속성과 상호 작용 데이터를 수집했습니다. 약물 상호작용은 일부 템플릿을 기반으로 한 자연어 설명입니다. 위 그림과 같이 설명란에는 특정 약물이 어떻게 신진대사를 증가시키거나 신진대사를 약화시킬 수 있는지에 대해 이야기합니다. 중간 단어가 템플릿이고, 앞과 뒤가 약 이름이 채워져 있습니다. 따라서 모델 분류가 명확하면 데이터베이스의 모든 약물 상호 작용을 표시할 수 있습니다.
그러므로약물 상호작용을 무상호작용, 시너지 및 길항작용의 3가지 범주로 고려하여 템플릿을 표시하고, 약물상호작용의 분류를 얻었습니다.
2. 데이터 전처리 및 문제 정의
데이터 전처리를 위해 전자 의료 기록 데이터의 경우 환자의 기본 정보와 검사실 정보를 하나의 One-hot 벡터로 처리합니다. 조건 설명 텍스트 부분을 Padding과 Cut off를 통해 고정 길이 텍스트로 변환합니다. 약물 상호작용 데이터의 경우: 이를 약물 상호작용 매트릭스로 변환합니다.
동시에 문제는 다음과 같이 정의됩니다. 일련의 환자 설명과 해당 Ground-Truth 약물 패키지가 주어지면 주어진 환자와 샘플 패키지를 입력하고 출력할 수 있는 개인화된 채점 기능을 훈련할 것입니다. 일치하는 레벨 점수. 분명히 이것이 판별 모델이 정의되는 방식입니다.
3. 모델 개요

이 기사에서 제안한 논문 제목은 DPR: Drug Package Recommendation via Interaction-aware Graph Induction입니다. 모델은 세 부분으로 구성됩니다.
사전 훈련 부분 NCF 프레임워크를 기반으로 환자와 약물의 초기 표현을 얻습니다.
약물 패키지 구성 부분에서는 약물 상호작용 관계의 유형을 기반으로 약물 패키지를 약물 그래프로 구성하는 방법을 제안합니다.
마지막 부분은 그래프 기반 약물 패키지에 대한 권장 프레임워크로, 두 가지 다른 관점에서 약물 간의 상호 작용을 모델링하는 방법을 이해하기 위해 두 가지 변형이 설계되었습니다.
- 사전 교육

사전 교육 부분은 우선 전통적인 일대일 추천 방식에 따라 진행됩니다. 어떤 경우에 의사가 환자에게 사용한 약은 양성 케이스이고, 사용하지 않은 약은 음성 케이스입니다. BPRLoss에 의해 사전 학습된 약물의 점수는 사용되지 않은 약물의 점수보다 높습니다.
사전 훈련 부분은 주로 기본적인 약물 효과 정보를 포착하여 나중에 더 복잡한 상호 작용을 포착하기 위한 기반을 제공하는 것입니다. One-hot 부분의 경우 MLP를 사용하여 텍스트 부분의 특징을 추출하고 LSTM을 사용하여 텍스트 특징을 추출합니다.
- 약물 그래프 구성

약물 추천의 핵심 문제는 약물 간 상호 작용을 어떻게 고려하고 약물 패키지의 특성을 어떻게 얻을 것인가입니다. 이를 바탕으로 본 논문에서는 그래픽 모델 기반의 의약품 패키지 모델링 방법을 제안한다.
먼저, 라벨이 붙은 약물 상호작용 관계는 서로 다른 값이 서로 다른 상호작용 유형을 나타내는 약물 상호작용 매트릭스로 변환됩니다. 그런 다음 이 순간을 기반으로 특정 약물 패키지를 이종 약물 그래프로 변환할 수 있습니다. 그래프의 노드는 약물 패키지의 약물에 해당하고 노드 속성은 노드가 사전 훈련된 임베딩에 해당한다는 것입니다. 이전 단계. 동시에 과도한 계산을 피하기 위해 약물 그래프를 완전한 그래프로 구성하지 않았습니다. 즉, 두 약물 사이에 가장자리를 허용하지 않고 선택적으로 가장자리라고 표시된 약물만 유지했습니다. 통과된 약물 쌍과 빈도가 특정 임계값을 초과하는 가장자리.
- 약물 그래프 구성
약물 그래프를 효과적으로 특성화하기 위해 약물 그래프의 에지 속성을 공식화하는 두 가지 방법을 제안합니다.

첫 번째 형태는 DPR-WG로, 가중치 그래프를 사용해 약물 그래프를 표현합니다. 첫 번째 단계는 표시된 약물 상호작용을 기반으로 전체 가장자리 값을 초기화하는 것입니다. 여기서 -1은 길항작용을 나타내고, +1은 시너지 효과를 나타내고, 0은 상호작용이 없거나 알 수 없음을 나타냅니다. 그런 다음 마스크 벡터를 사용하여 약물 그래프의 간선 가중치에 대한 개인화된 업데이트를 수행합니다.
이 마스크 벡터는 다양한 약물의 상호 작용과 개별 환자에 대한 개인별 영향 정도를 반영합니다. 계산 방법은 비선형 레이어와 시그모이드 함수를 사용하여 각 차원의 값이 0과 1 사이가 되도록 구현하는 것입니다. 특징 선택 기능 및 약물 상호작용에 대한 개인화된 조정 기능. 약물 그래프 업데이트 과정은 먼저 DPR-WG에서 업데이트 인자를 계산한 후, 해당 에지의 가중치를 곱하거나 더하여 업데이트 인자를 업데이트하는 것입니다. 후속 실험에서는 업데이트 방법이 결과에 거의 영향을 미치지 않는 것으로 나타났으며, 약물 그래프 표현 과정에서 가중치 그래프를 기반으로 약물을 표현하는 방법을 설계했습니다.
요약하자면, 먼저 가중치 그래프에 대한 정보 업데이트 프로세스를 설계했습니다. 즉, 이웃 정보를 집계하는 과정에서 집계 정도는 에지의 가중치에 따라 개별적으로 조정됩니다. 그런 다음 Self Attention 메커니즘을 사용하여 서로 다른 노드 간의 가중치를 계산하고 집계 MLP를 사용하여 그래프를 집계하여 전체 약물 그래프의 최종 표현을 얻었습니다. 이후, 환자 표현과 약물 이미지 표현이 점수 함수에 입력되고, 추천을 위한 출력이 얻어질 수 있습니다.
또한 이 기사에서는 BPRLoss를 사용하여 모델을 학습하고 1개의 양성 샘플과 10개의 음성 샘플에 해당하는 음성 샘플링 방법을 소개합니다.
 두 번째 변형은 속성 그래프를 사용하여 약물 그래프를 나타내는 것입니다. 첫 번째 단계는 MLP를 통해 에지 양 끝의 노드 벡터를 융합하여 에지 벡터를 초기화하는 것입니다. 그런 다음 마스크 벡터를 사용하여 에지 벡터를 업데이트합니다. 이때 업데이트 방법은 더 이상 업데이트 요소가 아니며 업데이트 벡터에 요소별로 약물의 에지 벡터를 곱하여 얻습니다. 업데이트된 가장자리 속성 벡터. 우리는 속성 그래프를 위한 GNN을 특별히 설계했습니다. 메시지 전달 프로세스는 먼저 전파를 위한 에지 벡터와 노드 임베딩을 기반으로 메시지를 계산하고 자체 주의 및 집계 방법을 통해 그래프 임베딩을 얻습니다.
두 번째 변형은 속성 그래프를 사용하여 약물 그래프를 나타내는 것입니다. 첫 번째 단계는 MLP를 통해 에지 양 끝의 노드 벡터를 융합하여 에지 벡터를 초기화하는 것입니다. 그런 다음 마스크 벡터를 사용하여 에지 벡터를 업데이트합니다. 이때 업데이트 방법은 더 이상 업데이트 요소가 아니며 업데이트 벡터에 요소별로 약물의 에지 벡터를 곱하여 얻습니다. 업데이트된 가장자리 속성 벡터. 우리는 속성 그래프를 위한 GNN을 특별히 설계했습니다. 메시지 전달 프로세스는 먼저 전파를 위한 에지 벡터와 노드 임베딩을 기반으로 메시지를 계산하고 자체 주의 및 집계 방법을 통해 그래프 임베딩을 얻습니다.
비슷하게 BPRLoss를 훈련에 사용할 수 있지만 차이점은 에지 벡터가 약물 상호작용의 카테고리 정보를 포함할 수 있기를 바라면서 에지 분류를 위한 교차 엔트로피 손실 함수를 추가로 도입한다는 것입니다. 이전 변형의 초기화된 부호에는 당연히 이 정보가 유지되지만 이 변형의 그래프는 그렇지 않기 때문에 손실 함수를 도입하여 이 정보를 보완합니다.
실험 결과에 따르면 우리의 두 모델은 서로 다른 평가 지표에서 다른 판별 모델을 능가했습니다. 동시에 우리는 t-SNE 방법을 사용하여 앞서 언급한 마스크 벡터를 2차원 공간에 투영하는 사례 분석도 수행했습니다. 예를 들어 그림에서 볼 수 있듯이 임산부, 유아, 간 환자가 사용하는 약물은 클러스터로 클러스터되는 경향이 매우 뚜렷하며 이는 우리 방법의 효율성을 입증합니다.
3. 생성적 약물 패키지 추천
위 판별 모델은 기존 약물 패키지에서만 선택할 수 있으므로 추천 효과에 영향을 미칩니다. 본 논문은 모델이 새로운 환자에게 맞춤형 신약 패키지를 생성할 수 있기를 바라는 목적으로 TOIS 저널에 발표된 이전 연구의 확장 작업을 소개합니다.
이 작업은 이전 논문의 그래프 표현 학습의 핵심 아이디어를 유지하는 동시에 문제 정의를 완전히 변경하고 모델을 생성 모델로 정의하며 시퀀스 생성 및 강화 학습 기술을 도입하고, 추천 효과가 크게 향상됩니다.
1. 판별 추천 -> 생성 추천

판별 모델과 생성 모델의 핵심 차이점은 판별 모델이 주어진 환자와 주어진 약물 패키지 간의 일치 정도를 점수로 매긴다는 점입니다. 생성 모델은 환자를 위한 후보 약물 패키지를 생성하고 최상의 약물 패키지를 선택합니다.
2. 휴리스틱 생성 방법

위에서 제안한 판별 모델의 단점을 보완하여 유사한 환자의 약물 패키지에 추가하여 몇 가지 휴리스틱 생성 방법을 설계했습니다. 일부 의약품을 삭제하면 모델이 선택할 수 있는 과거 기록에 한 번도 나타나지 않은 일부 의약품 패키지가 생성됩니다. 실험 결과는 이 간단한 방법이 매우 효과적이며 후속 방법의 기초를 제공한다는 것을 입증합니다.
3. 모델 개요

다음은 TOIS에 게시된 정책 그라데이션을 통한 상호 작용 인식 약물 패키지 권장 사항입니다. 본 글에서 제안하는 모델을 DPG라고 부르는데, 이는 이전 글의 DPR과 다르다. 여기서 G는 Generation이다.
이 모델은 주로 약물 상호 작용 다이어그램에 대한 정보 전파, 환자 특성화 및 약물 패키지 생성 모듈의 세 부분으로 구성됩니다. 위와 가장 큰 차이점은 약물 패키지 생성 모듈입니다.
- 약물 상호작용 그래프

먼저 약물 간의 상호작용을 포착하기 위한 그래프 신경망 방식이 기사에 그대로 남아 있습니다. 판별 모델은 약물 패키지가 주어져 약물 그래프로 쉽게 변환할 수 있지만, 생성 모델에서는 계산량이 많아 약물 그래프를 모두 그래프로 구성할 수 없습니다.
이 기사는 약물 상호작용 그래프에 모든 약물을 포함합니다. 또한 속성 그래프를 사용하여 그래프를 공식화합니다. 또한 가장자리 분류 손실 함수와 가장자리의 임베딩 정보도 유지합니다. 이 약물 상호작용 그래프의 GNN.
여러 라운드(보통 2회)의 메시지 전달 후 사용할 약물 Embedding으로 Embedding 노드를 추출합니다.
- 환자 표현

환자 표현 부분에서도 MLP와 LSTM을 사용하여 환자의 표현 벡터를 추출하고 마스크 벡터를 계산합니다. 이는 이후에 환자의 개인화된 표현 벡터를 캡처하는 데 사용됩니다. .
- 시퀀스 생성 기반 약물 패키지 생성

약물 패키지 생성 작업은 순환 신경망 RNN을 사용하여 구현된 시퀀스 생성 작업으로 간주할 수 있습니다. 그러나 이 방법은 또한 두 가지 주요 과제를 안겨줍니다.
첫 번째 과제는 생성 과정에서 생성된 약물과 기존 약물 간의 상호 작용을 어떻게 고려하는가입니다. 이를 위해 우리는 약물 간의 상호 작용을 명시적으로 모델링하기 위해 약물 상호 작용 벡터를 기반으로 하는 방법을 제안합니다.
두 번째 과제는 샘플 패키지가 본질적으로 순서가 없는 세트이지만 시퀀스 생성 작업은 종종 순서 있는 시퀀스 방법을 대상으로 한다는 것입니다. 이를 위해 정책 기울기 기반의 강화학습 방법을 제안하고, 이 알고리즘의 효과와 안정성을 향상시키기 위해 SCST 기반의 방법을 추가하였다.
- 최대 우도 기반 약물 패키지 생성

먼저 최대 우도 기반 약물 패키지 생성 과정에서 약물 간 상호 작용을 고려하는 방법을 소개합니다. 이 부분도 또한 강화학습 부분에 대한 기반은 나중에 사용됩니다. 최대 가능성을 기반으로 하는 시퀀스 생성 방법은 NLP 분야에서 널리 사용되어 왔습니다. 생성 과정에서 생성된 각 약물은 이전에 생성된 다른 약물에 의존합니다.
모델에 과도한 계산 부담을 주지 않고 약물 간의 상호 작용을 고려하기 위해 각 시간 단계에서 최근 생성된 약물과 이전 약물 간의 상호 작용 벡터를 명시적으로 계산할 것을 제안합니다. 계산 방법은 이전 그래프 신경망의 레이어에서 나옵니다.
동시에 마스크 벡터와 상호작용 벡터를 추가하여 해당 요소를 곱하여 환자의 개인화 정보를 소개합니다.
마지막으로 모든 약물의 상호작용 벡터를 합산하고 MLP를 사용하여 이를 융합하여 포괄적인 상호작용 벡터를 얻습니다.
이 벡터를 세대용 클래식 시퀀스 모델에 후속 통합하면 첫 번째 문제가 해결됩니다.

클래식 시퀀스 생성과 달리 약물 패키지는 실제로 세트이며 중복된 약물이 없어야 합니다. 따라서 모델이 이미 생성된 약물을 생성할 수 없도록 제한 사항을 추가했습니다. 생성되었습니다. 생성된 결과는 집합이어야 합니다. 마지막으로 모델 학습에 대한 최대 가능성을 기반으로 MLE 손실 함수를 사용했습니다.
- 강화학습 기반 약물 패키지 생성

위 최대 가능성 기반 방법의 가장 큰 단점은 약물 패키지의 순서가 엄격하다는 것입니다. 빈도순, 첫 글자순 정렬 등 약물의 순서를 수동으로 지정하는 일부 방법은 약물 패키지를 파괴합니다. 동시에 약물 패키지 수집의 특성을 일부 잃게 되므로 강화 학습 기반 약물 패키지 생성 모델을 제안합니다. 강화 학습에서 모델의 목표는 인위적으로 설정된 보상 함수를 최대화하는 것입니다. 모델이 완전한 약물 패키지를 생성한 후 순서와 무관한 보상 손실 함수를 제공하면 모델의 순서 의존성을 줄일 수 있습니다.
이 글에서는 F값을 보상으로 사용하는데, 이는 순서 독립적인 함수이자 우리가 우려하는 평가 지표입니다. 본 논문에서는 F-value를 평가지표로 사용하고, 학습방법에 있어서 Policy Gradient를 기반으로 한 학습방법을 채택하였으므로 여기서는 자세히 추론하지 않는다.

정책 기울기 기반 학습 방법에서는 기준선을 사용하여 기울기 추정의 분산을 줄여 학습의 안정성을 높이는 방법이 잘 알려져 있습니다. 따라서 우리는 SCST 기반의 훈련 방법, 즉 Self-Critical Sequence 훈련 방법을 사용했습니다. 기준선 역시 모델 자체에서 생성된 약물 패키지에서 얻은 보상에서 비롯됩니다. 제가 생성하는 방식은 Greedy search의 일반적인 시퀀스 생성 방법입니다.
Policy Gradient를 기반으로 한 모델에서 샘플링한 약물 패키지의 보상이 기존 Greedy 검색으로 생성된 약물 패키지보다 높기를 바랍니다. 이를 바탕으로 본 글에서는 그림과 같이 강화학습을 위한 손실 함수를 설계한다. 여기서는 도출 과정에 대해 자세히 소개하지 않는다.
- 최대 우도 사전 훈련 + 강화 학습

또한 강화 학습의 특징 중 하나는 훈련이 어렵다는 것이므로 위의 두 가지 훈련 방법을 결합했습니다. 먼저 매우 자연스러운 추정 방법을 사용하여 모델을 사전 훈련한 다음 강화 학습 방법을 사용하여 모델 매개 변수를 미세 조정합니다.
- 실험 결과
다음은 모델의 실험 결과입니다.

위 표에서 모든 의약품 패키지는 Greedy 검색을 사용하여 생성되었습니다. 우선, 생성 모델을 기반으로 한 방법의 성능은 일반적으로 판별 모델을 기반으로 한 방법보다 우수합니다. 이 실험은 생성 모델이 더 나은 선택이 될 것임을 입증합니다. 이 모델은 F 값의 다른 모든 기준선을 능가합니다. 또한, 강화학습 기반 모델의 성능이 최대 우도 기반 모델을 크게 능가하여 강화학습 방법의 효율성을 입증했습니다.

이후 일련의 절제 실험도 진행했습니다. 상호작용 마스크 벡터와 절제를 위한 강화학습 모듈을 포함한 상호작용 그래프를 제거했으며 그 결과 각 모듈이 효과적이라는 것이 입증되었습니다. 동시에, SCST 모듈을 제거하면 모델 효과가 크게 떨어지는 것을 볼 수 있는데, 이는 강화학습이 실제로 훈련하기 어렵다는 것을 증명합니다. 기준선 제한이 없으면 전체 훈련 과정이 매우 불안해집니다.

마지막으로 저희도 많은 사례분석을 해본 결과, 임산부와 아기의 개인별 선호도가 확연하다는 것을 알 수 있었습니다. 동시에 위장병, 심장병 등과 같은 몇 가지 일반적인 질병을 추가했습니다. 이러한 질병의 마스크 벡터는 매우 분산되어 클러스터를 형성하지 않습니다. 흔한 질병을 앓고 있는 환자의 상태는 다양하며, 특별히 개인별 상황은 없을 것입니다. 임산부나 영유아와 달리 약물에 대한 선별검사는 매우 명백합니다. 예를 들어 특정 소아용 약물은 지정이 필요하고, 일부 약물은 사용할 수 없습니다. 임산부에 의해.
동시에 우리는 약물의 상호작용 벡터를 투영했는데, 두 약물, 즉 시너지 효과와 길항 작용이 서로 다른 두 가지 반대 상황을 형성한다는 것을 알 수 있으며, 이는 모델이 두 가지 서로 다른 상호 작용 밴드를 포착한다는 것을 나타냅니다. . 다양한 효과가 제공됩니다.
4. 요약 및 전망
요약하면, 본 연구는 주로 차별적 약물 패키지 추천, 생성적 약물 패키지 추천을 포함하여 상호작용 인식 개인별 약물 패키지 추천에 관한 것입니다.
두 가지 모두 그래프 표현 학습 기술을 사용하여 약물 간의 상호 작용을 모델링하고, 둘 다 마스크 벡터를 사용하여 환자의 상태와 상호 작용에 대한 개인화된 인식을 고려한다는 공통점이 있습니다.
두 작품의 가장 큰 차이점은 문제 정의의 차이입니다. 판별 모델에서 원하는 것은 점수 함수이므로 생성 모델에서 원하는 것은 생성기임을 실험을 통해 증명했습니다. 생성 모델은 실제로 문제를 더 잘 정의하기 위한 것입니다.
위 내용은 이 그림은 약물 추천 시스템에 학습 기술을 적용하는 방법을 보여줍니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 생산 등급 에이전트 헝겊 파이프 라인을 모니터링하는 방법은 무엇입니까?Apr 12, 2025 am 09:34 AM
생산 등급 에이전트 헝겊 파이프 라인을 모니터링하는 방법은 무엇입니까?Apr 12, 2025 am 09:34 AM소개 2022 년에 Chatgpt의 출시는 기술 및 비 기술 산업 모두에 혁명을 일으켜 개인과 조직에 생성 AI를 제공했습니다. 2023 년 내내 노력은 큰 언어 모드를 활용하는 데 집중했습니다
 스타 스키마로 데이터웨어 하우스를 최적화하는 방법은 무엇입니까?Apr 12, 2025 am 09:33 AM
스타 스키마로 데이터웨어 하우스를 최적화하는 방법은 무엇입니까?Apr 12, 2025 am 09:33 AMStar Schema는 데이터웨어 하우징 및 비즈니스 인텔리전스에 사용되는 효율적인 데이터베이스 설계입니다. 주변 치수 테이블에 연결된 중앙 사실 테이블로 데이터를 구성합니다. 이 별 모양의 구조는 복잡한 q를 단순화합니다
 멀티 모달 헝겊 시스템 구축에 대한 포괄적 인 안내서Apr 12, 2025 am 09:29 AM
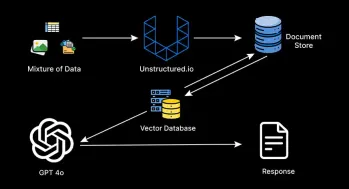
멀티 모달 헝겊 시스템 구축에 대한 포괄적 인 안내서Apr 12, 2025 am 09:29 AMRag Systems로 더 잘 알려진 검색 증강 생성 시스템은 값 비싼 미세 튜닝의 번거 로움없이 맞춤형 엔터프라이즈 데이터에 대한 질문에 답하는 지능형 AI 보조원을 구축하는 데 필요한 표준이되었습니다.
 에이전트 래그 시스템이 기술을 어떻게 변화시킬 수 있습니까?Apr 12, 2025 am 09:21 AM
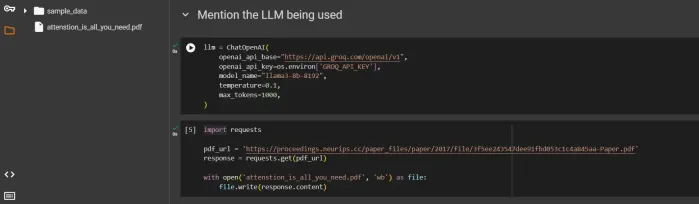
에이전트 래그 시스템이 기술을 어떻게 변화시킬 수 있습니까?Apr 12, 2025 am 09:21 AM소개 인공 지능은 새로운 시대에 들어 왔습니다. 모델이 사전 정의 된 규칙에 따라 정보를 단순히 출력하는 시대는 지났습니다. 오늘 AI의 최첨단 접근 방식은 Rag를 중심으로 진행됩니다 (검색-augmente
 자동 생성 쿼리에 대한 SQL 어시스턴트Apr 12, 2025 am 09:13 AM
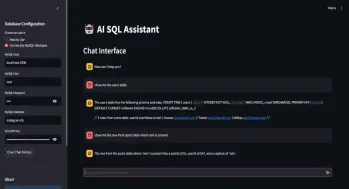
자동 생성 쿼리에 대한 SQL 어시스턴트Apr 12, 2025 am 09:13 AM단순히 데이터베이스와 대화하고, 일반 언어로 질문을하고, 복잡한 SQL 쿼리를 작성하거나 스프레드 시트를 정렬하지 않고 즉각적인 답변을받을 수 있기를 바랐습니까? Langchain의 SQL 툴킷으로 Groq a
 AI Index 2025 읽기 : AI는 친구, 적 또는 부조종사입니까?Apr 11, 2025 pm 12:13 PM
AI Index 2025 읽기 : AI는 친구, 적 또는 부조종사입니까?Apr 11, 2025 pm 12:13 PMStanford University Institute for Human-Oriented Intificial Intelligence가 발표 한 2025 인공 지능 지수 보고서는 진행중인 인공 지능 혁명에 대한 훌륭한 개요를 제공합니다. 인식 (무슨 일이 일어나고 있는지 이해), 감사 (혜택보기), 수용 (얼굴 도전) 및 책임 (우리의 책임 찾기)의 네 가지 간단한 개념으로 해석합시다. 인지 : 인공 지능은 어디에나 있고 빠르게 발전하고 있습니다 인공 지능이 얼마나 빠르게 발전하고 확산되고 있는지 잘 알고 있어야합니다. 인공 지능 시스템은 끊임없이 개선되어 수학 및 복잡한 사고 테스트에서 우수한 결과를 얻고 있으며 1 년 전만해도 이러한 테스트에서 비참하게 실패했습니다. AI 복잡한 코딩 문제 또는 대학원 수준의 과학적 문제를 해결한다고 상상해보십시오-2023 년 이후
 Meta Llama 3.2- 분석 Vidhya를 시작합니다Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2- 분석 Vidhya를 시작합니다Apr 11, 2025 pm 12:04 PM메타의 라마 3.2 : 멀티 모달 및 모바일 AI의 도약 Meta는 최근 AI에서 강력한 비전 기능과 모바일 장치에 최적화 된 가벼운 텍스트 모델을 특징으로하는 AI의 상당한 발전 인 Llama 3.2를 공개했습니다. 성공을 바탕으로 o
 AV 바이트 : Meta ' S Llama 3.2, Google의 Gemini 1.5 등Apr 11, 2025 pm 12:01 PM
AV 바이트 : Meta ' S Llama 3.2, Google의 Gemini 1.5 등Apr 11, 2025 pm 12:01 PM이번 주 AI 환경 : 발전의 회오리 바람, 윤리적 고려 사항 및 규제 토론. OpenAi, Google, Meta 및 Microsoft와 같은 주요 플레이어


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

