
사전 훈련에는 주의가 필요하지 않으며 4096개 토큰으로 확장하는 것도 문제가 되지 않습니다. 이는 BERT와 비슷합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-08 19:37:081217검색
Transformer는 NLP 사전 훈련 모델 아키텍처로서 레이블이 지정되지 않은 대규모 데이터를 효과적으로 학습할 수 있습니다. 연구에 따르면 Transformer는 BERT 이후 NLP 작업의 핵심 아키텍처로 입증되었습니다.
최근 연구에서는 상태 공간 모델(SSM)이 장거리 시퀀스 모델링에 유리한 경쟁 아키텍처인 것으로 나타났습니다. SSM은 음성 생성 및 Long Range Arena 벤치마크에서 최첨단 결과를 달성하며 심지어 Transformer 아키텍처보다 뛰어난 성능을 발휘합니다. 정확성을 향상시키는 것 외에도 SSM 기반 라우팅 계층은 시퀀스 길이가 늘어남에 따라 2차 복잡성을 나타내지 않습니다.
이 기사에서 Cornell University, DeepMind 및 기타 기관의 연구원들은 주의 없는 사전 훈련을 위해 BiGS(양방향 게이팅 SSM)를 제안했습니다. 이는 주로 SSM 라우팅과 곱셈 기반 게이팅(곱셈 게이팅) 아키텍처를 결합합니다. 연구에 따르면 SSM 자체는 NLP 사전 훈련에서 성능이 좋지 않지만 곱셈 게이트 아키텍처에 통합되면 다운스트림 정확도가 향상됩니다.
실험에 따르면 BiGS는 통제된 설정에서 동일한 데이터로 학습할 때 BERT 모델의 성능을 일치시킬 수 있습니다. 더 긴 인스턴스에 대한 추가 사전 훈련을 통해 모델은 입력 시퀀스를 4096으로 확장할 때 선형 시간도 유지합니다. 분석에 따르면 곱셈 게이팅이 필요하며 가변 길이 텍스트 입력에 대한 SSM 모델의 일부 특정 문제를 해결합니다.

논문 주소: https://arxiv.org/pdf/2212.10544.pdf
방법 소개
SSM은 다음을 통해 지속적으로 u(t)를 입력하고 y(t)를 출력합니다. 미분 방정식 )이 연결됩니다:
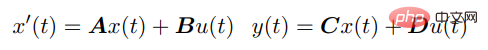
이산 시퀀스의 경우 SSM 매개변수가 이산화되고 프로세스는 다음과 같이 근사화될 수 있습니다.
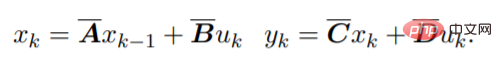
이 방정식은 선형 RNN으로 해석될 수 있습니다. 여기서 x_k는 숨겨진 상태입니다. y는 컨볼루션을 사용하여 계산할 수도 있습니다.
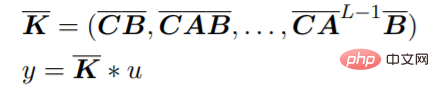
신경망에서 SSM을 사용하는 효율적인 방법은 HiPPO라는 A를 매개변수화하는 방법을 개발한 Gu et al.에 의해 시연되었습니다. S4라고 합니다. 이는 RNN 교육보다 더 효율적이면서 장기 시퀀스를 모델링하는 SSM의 기능을 유지합니다. 최근 연구자들은 원래 매개변수의 더 간단한 근사치로 유사한 결과를 달성하는 단순화된 대각선 버전의 S4를 제안했습니다. 높은 수준에서 SSM 기반 라우팅은 2차 계산으로 인한 주의 비용 없이 신경망의 시퀀스 모델링에 대한 대안을 제공합니다.
사전 훈련된 모델 아키텍처
SSM이 사전 훈련에서 주의를 대체할 수 있나요? 이 질문에 대답하기 위해 연구에서는 그림 1에 표시된 스택 아키텍처(STACK)와 곱셈 게이트 아키텍처(GATED)라는 두 가지 아키텍처를 고려했습니다.
셀프 어텐션이 있는 스택 아키텍처는 BERT /transformer 모델과 동일하며 게이트 아키텍처는 최근 단방향 SSM에도 사용되는 게이트 유닛을 양방향으로 적용한 것입니다. 곱셈 게이팅이 있는 2개의 시퀀스 블록(즉, 순방향 및 역방향 SSM)이 피드포워드 레이어에 끼워져 있습니다. 공정한 비교를 위해 게이트 아키텍처의 크기는 스택 아키텍처의 크기와 유사하게 유지됩니다.
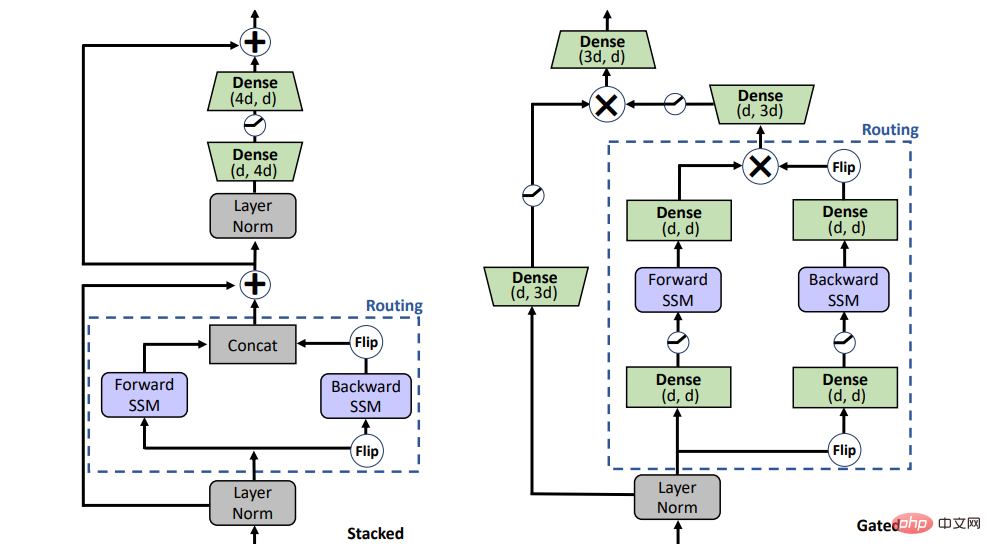
그림 1: 모델 변수. STACK은 표준 변압기 아키텍처이고 GATED는 게이트 제어 장치를 기반으로 합니다. 라우팅 구성 요소(점선)의 경우 연구에서는 양방향 SSM(그림에 표시)과 표준 self-attention을 모두 고려합니다. Gated(X)는 요소별 곱셈을 나타냅니다.
실험 결과
사전 훈련
표 1은 GLUE 벤치마크에서 다양한 사전 훈련된 모델의 주요 결과를 보여줍니다. BiGS는 토큰 확장 시 BERT의 정확성을 복제합니다. 이 결과는 SSM이 그러한 계산 예산 하에서 사전 훈련된 변환기 모델의 정확도를 복제할 수 있음을 보여줍니다. 이러한 결과는 다른 비주의 기반 사전 훈련 모델보다 훨씬 낫습니다. 이 정확도를 달성하려면 곱셈 게이팅이 필요합니다. 게이팅이 없으면 스택 SSM의 결과가 훨씬 더 나쁩니다. 이러한 이점이 주로 게이팅 사용에서 비롯되는지 조사하기 위해 GATE 아키텍처를 사용하여 주의 기반 모델을 훈련했지만 결과는 모델이 실제로 BERT보다 덜 효과적이라는 것을 보여줍니다.
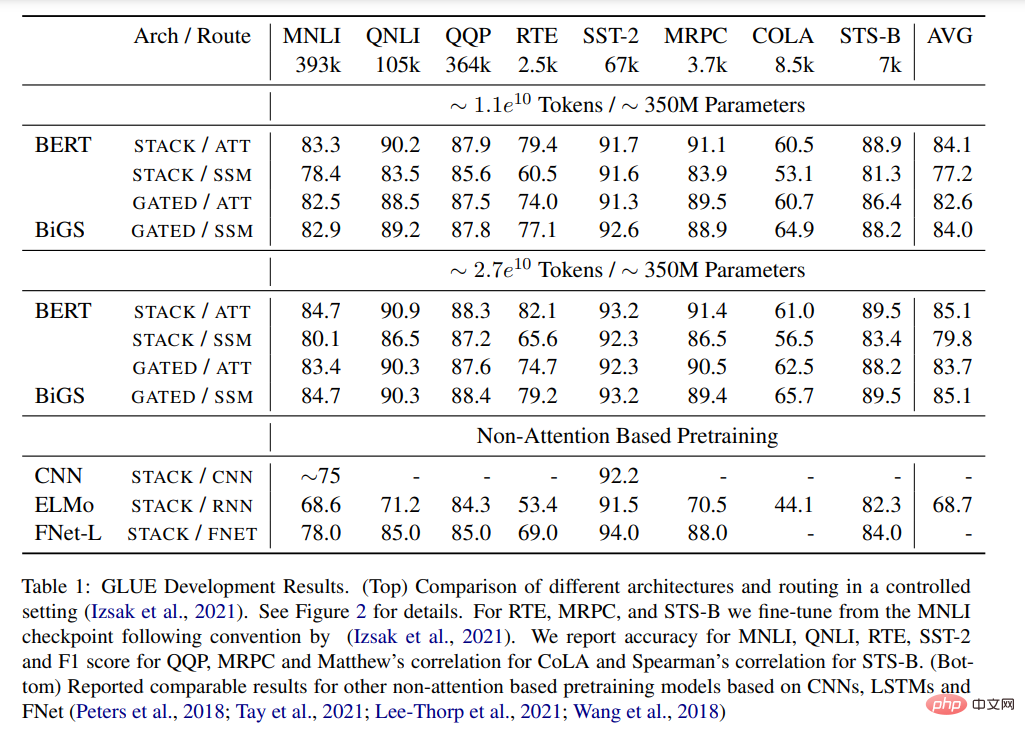
표 1: GLUE 결과. (상단) 제어 설정에 따른 다양한 아키텍처 및 라우팅 비교. 자세한 내용은 그림 2를 참조하세요. (하단)은 CNN, LSTM 및 FNet을 기반으로 한 다른 비주의 사전 학습 모델에 대한 유사한 결과를 보고했습니다.
Long-Form Task
표 2 결과는 SSM이 Longformer EncoderDecoder(LED) 및 BART와 비교할 수 있음을 보여줍니다. 그러나 결과는 원격 작업에서도 잘 수행된다는 것을 보여줍니다. 더 좋습니다. SSM은 다른 두 가지 방법보다 사전 훈련 데이터가 훨씬 적습니다. SSM이 이러한 길이를 대략적으로 계산할 필요는 없지만 긴 형식은 여전히 중요합니다.
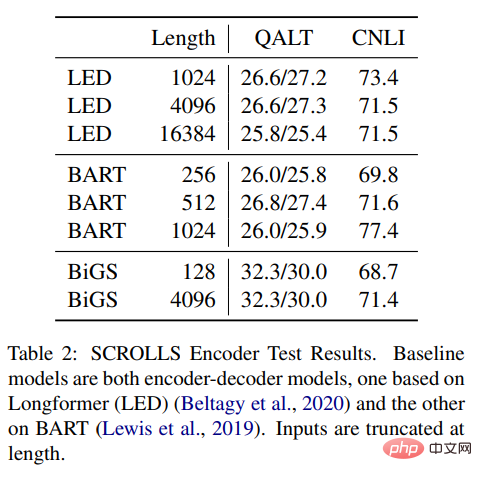
표 2: SCROLLS 인코더 테스트 결과. 기본 모델은 모두 인코더-디코더 모델이며, 하나는 Longformer(LED)를 기반으로 하고 다른 하나는 BART를 기반으로 합니다. 입력 길이가 잘립니다.
자세한 내용은 원본을 참조해주세요.
위 내용은 사전 훈련에는 주의가 필요하지 않으며 4096개 토큰으로 확장하는 것도 문제가 되지 않습니다. 이는 BERT와 비슷합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!