
Python은 Excel 파일을 어떻게 처리합니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-08 17:58:151983검색
『문제 설명』
이번에 처리할 엑셀은 시트가 2개인데, 시트 하나의 데이터를 바탕으로 다른 시트의 값을 계산해야 합니다. 문제는 계산할 시트에 숫자 값뿐만 아니라 수식도 포함되어 있다는 것입니다. 살펴보겠습니다.
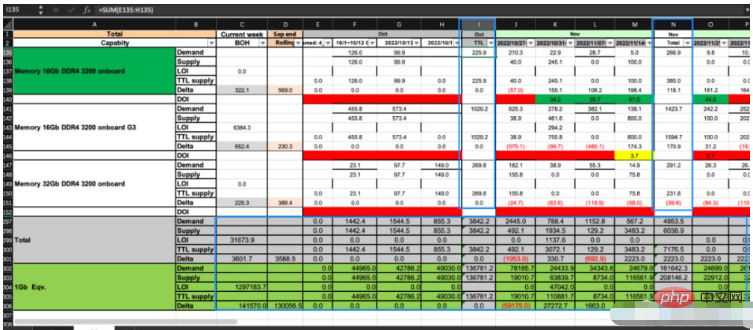
위 그림과 같이 이 엑셀에는 CP와 DS라는 두 개의 시트가 있습니다. 특정 비즈니스 규칙을 따르고 CP의 데이터를 기반으로 DS에 해당하는 셀의 데이터를 계산해야 합니다. . 그림의 파란색 상자에는 수식이 포함되어 있고 다른 영역에는 숫자 값이 포함되어 있습니다.
앞서 언급한 처리 로직을 따르면서 Excel을 일괄적으로 데이터프레임에 한 번에 읽은 다음 다시 일괄적으로 다시 작성하면 어떤 문제가 있나요? 코드의 이 부분은 다음과 같습니다.
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()위 코드의 문제점은 pd.read_excel() 메서드가 Excel에서 데이터 프레임으로 데이터를 읽을 때 수식이 있는 셀의 경우 수식 계산 결과를 직접 읽게 된다는 것입니다. (그렇지 않으면 결과는 Nan으로 반환됩니다) 그리고 Excel에 쓸 때 데이터 프레임을 일괄적으로 일괄 다시 쓰기 때문에 이전에 수식이 있는 셀은 계산된 값이나 Nan으로 다시 쓰여지고 수식은 다음과 같습니다. 잃어버린.
알겠습니다. 문제가 발생했습니다. 어떻게 해결해야 할까요? 여기서는 두 가지 아이디어가 떠오릅니다.
데이터프레임을 Excel에 다시 작성할 때 일괄적으로 다시 작성하지 말고 행과 열의 반복을 통해 계산된 데이터만 다시 작성하고 수식이 있는 셀은 변경하지 않고 그대로 둡니다.
- 엑셀을 읽을 때 수식 계산 결과를 읽는 대신 수식이 포함된 셀의 수식을 읽는 방법이 있나요?
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")위 코드는 실제로 문제를 해결합니다. 수식은 그대로 유지되었습니다. 그러나 기사 초반에 언급한 Python 처리 Excel에 대한 조언에 따르면 이 코드는 API를 통해 Excel 셀을 자주 실행하므로 쓰기 속도가 매우 느려지므로 심각한 성능 문제가 있습니다. 40분은 도저히 받아들일 수 없는 시간이어서 계획을 포기해야 했습니다. 「옵션 2」엑셀에서 수식 값이 있는 셀을 읽을 때 수식 값을 유지하는 아이디어입니다. 이는 각 Python Excel 라이브러리의 API에서만 찾아 해당 메서드가 있는지 확인할 수 있습니다. Pandas의 read_excel() 메서드를 주의 깊게 살펴보았는데 해당 매개변수 지원이 없습니다. 다음과 같이 Openpyxl을 지원할 수 있는 API를 찾았습니다. import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)여기서 핵심은 data_only 매개 변수입니다. True이면 데이터가 반환됩니다. 저는 생각했습니다. 해당 솔루션을 찾았습니다. 안녕하세요. 그런데 openpyxl을 통해 읽은 데이터 프레임의 데이터 구조를 보고 충격을 받았습니다. 내 엑셀 테이블의 헤더는 상대적으로 복잡한 2단계 헤더이고, 헤더에서 셀이 병합되고 분할되는 상황이 있기 때문에 이러한 헤더를 openpyxl에 의해 데이터 프레임으로 읽은 후에는 다중 레벨을 따르지 않습니다. pandas의 헤더는 처리되지만 단순히 숫자 인덱스 0123으로 처리됩니다...하지만 데이터 프레임 계산은 다중 레벨 인덱싱에 의존하므로 openpyxl의 이 처리 방법으로 인해 후속 계산이 불가능해집니다. 프로세스. openpyxl이 작동하지 않습니다. xlwings는 어떻습니까? xlwings API 문서를 검색한 후 실제로 아래와 같이 찾았습니다.
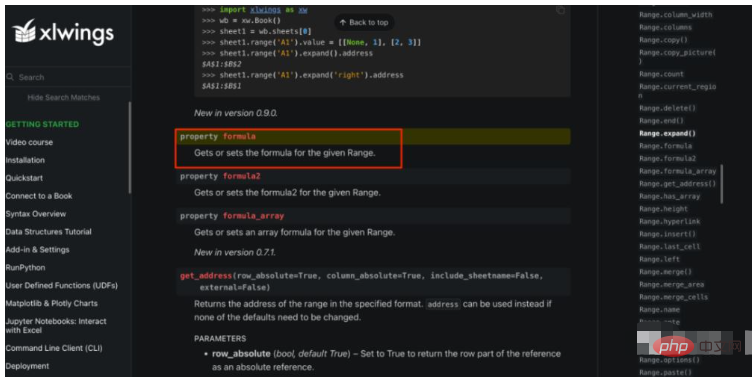
#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas그런데 ds_worksheet.used_range.formula는 수식이 있는 셀만 반환한다고 오해하게 만들었습니다. Excel에서는 실제로 모든 셀을 반환하지만 수식이 있는 셀에 대해서는 수식만 유지됩니다. 따라서 수식을 다시 작성하면 데이터프레임을 통해 계산하고 엑셀에 작성한 다른 값을 덮어쓰게 됩니다. 이런 경우 수식이 있는 셀을 한꺼번에 처리하는 것이 아니라 별도로 처리해야 하므로 코드는 다음과 같이 작성해야 합니다.
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()테스트 후 위 코드는 제 요구 사항을 완벽하게 충족하며, 성능도 완전 좋아요. 위 내용은 Python은 Excel 파일을 어떻게 처리합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!