
Python에서 DataFrame을 사용하여 데이터를 병합하고 결합하는 방법은 무엇입니까?

- 王林앞으로
- 2023-05-07 21:04:173453검색
merge()
1. 기존 병합
①방법 1
참조 열을 지정하고, 이 열을 기준으로 다른 열을 병합합니다.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)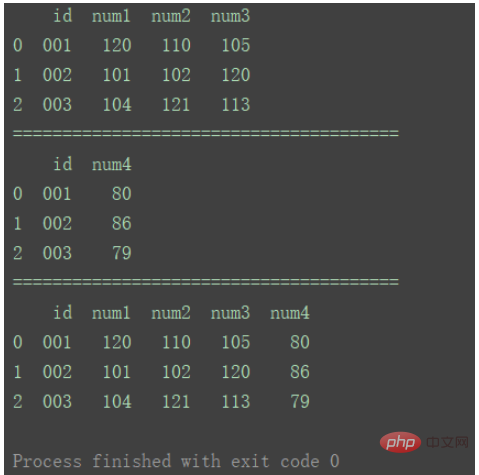
②방법 2
이 병합을 수행하려면 인덱스 열을 기준으로 인덱스별로 병합할 수도 있습니다. left_index와 right_index를 모두 True
로 설정하세요. (left_index와 right_index 모두 기본값은 False입니다. left_index는 왼쪽 테이블이 왼쪽 테이블 데이터의 인덱스를 기반으로 한다는 의미이고, right_index는 오른쪽 테이블이 오른쪽 테이블 데이터의 인덱스를 기반으로 한다는 의미입니다.)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)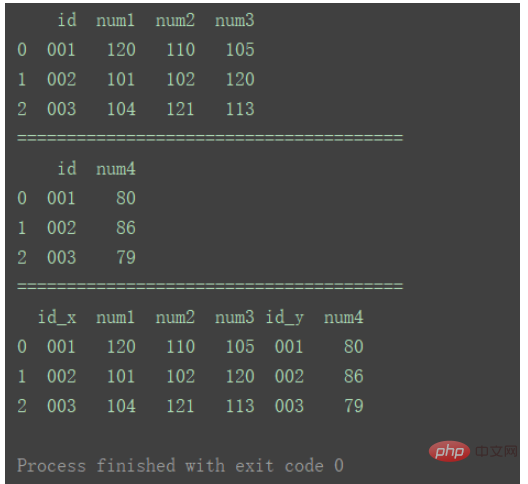
방법 ①과 비교했을 때 차이점은 그림과 같이 방법 2로 병합한 데이터에 중복된 컬럼이 있다는 점입니다.
중요 매개변수
pd.merge(right,how=‘inner’, on=“없음”, left_on=“없음”, right_on=“없음”, left_index=False, right_index=False )
| Parameters | Description |
|---|---|
| left | 왼쪽 테이블, 병합된 개체, DataFrame 또는 시리즈 |
| right | 오른쪽 테이블, 병합된 개체, DataFrame 또는 시리즈 |
| how | 병합 방법, 왼쪽(왼쪽 병합), 오른쪽(오른쪽 병합), 외부(외부 병합), 내부(내부 병합)일 수 있습니다 |
| on | 기본 열의 열 이름 |
| left_on | 기본 열 왼쪽 테이블 이름 |
| right_on | 오른쪽 테이블 기본 열 열 이름 |
| left_index | 왼쪽 열이 인덱스 기반인지 여부는 기본값이며 기본값은 False, no |
| right_index | 오른쪽인지 여부 컬럼은 인덱스를 기준으로 하며 기본값은 False이며, No |
그 중 left_index와 right_index는 on과 동시에 지정할 수 없습니다.
병합 방법 왼쪽 오른쪽 외부 내부
데이터 준비‘
새로 데이터 세트 준비:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '004', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")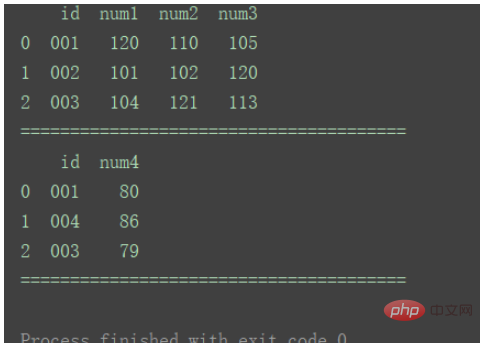
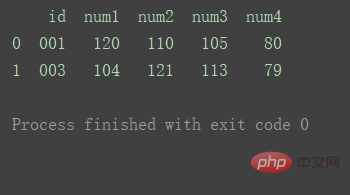
inner(기본값)
두 데이터세트의 키 교차점 사용
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
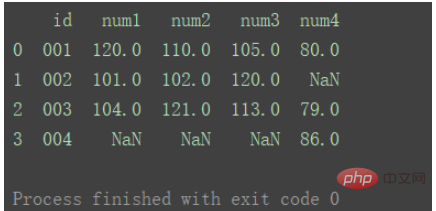
outer
두 데이터세트의 키 합집합 사용
df_merge = pd.merge(df1, df2, on='id', how="outer") print(df_merge)
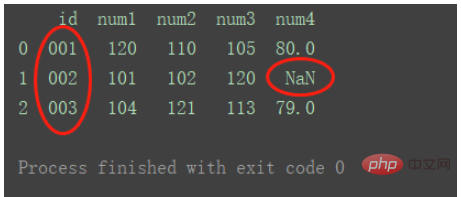
left
왼쪽 데이터세트의 키 사용
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)
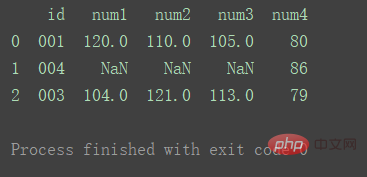
맞아
열쇠를 사용하세요 올바른 데이터 세트에서
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
2. 다대일 병합
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")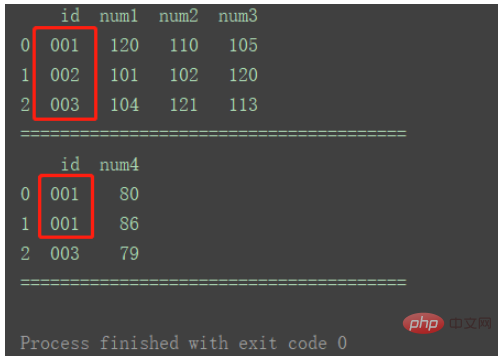
그림과 같이 df2에 중복된 id1 데이터가 있습니다.
Merge
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
병합된 결과는 그림과 같습니다.
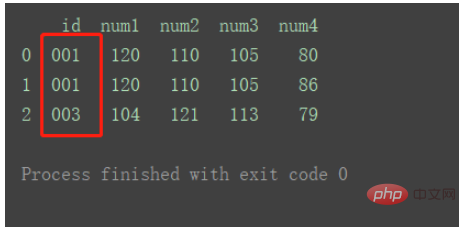
기본 내부 방법에 따라 두 데이터 세트의 키 교차를 계속 사용합니다. 그리고 중복 키가 있는 행은 병합된 결과에 여러 행으로 반영됩니다.
3. 다대다 병합
예를 들어 차트 1과 표 2 모두에 ID가 중복된 행이 여러 개 있습니다.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")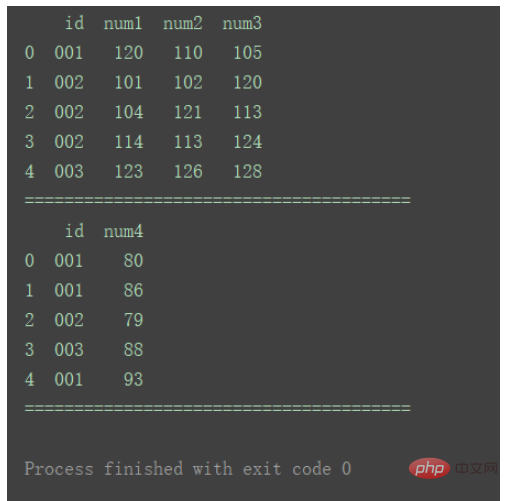
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
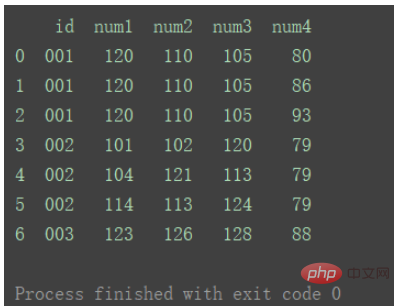
concat()
pd.concat(objs, axis=0, Join=‘outer’,ignore_index:bool=False,keys=None,levels=None,names=None , verify_integrity:bool=False,sort:bool=False,copy:bool=True)
| Parameters | Description |
|---|---|
| objs | Series, DataFrame 또는 Panel 개체의 시퀀스 또는 매핑 |
| axis | 기본값은 0으로, 이는 열을 나타냅니다. 1이면 행을 의미합니다. |
| join | 기본값은 "외부"이며 "내부"일 수도 있습니다. |
| ignore_index | 기본값은 False이며 인덱스가 유지됨(무시되지 않음)을 나타냅니다. 인덱스를 무시하려면 True로 설정합니다. |
其他重要参数通过实例说明。
1.相同字段的表首位相连
首先准备三组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)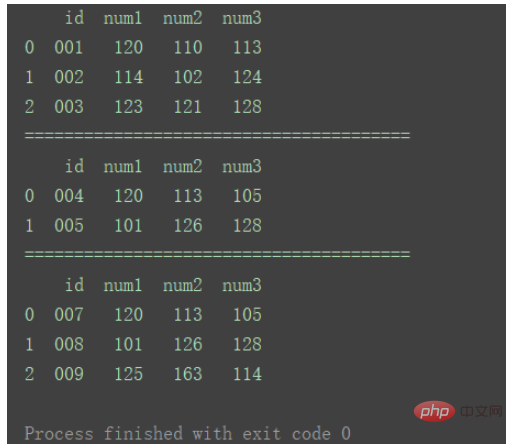
合并
dfs = [df1, df2, df3] result = pd.concat(dfs) print(result)
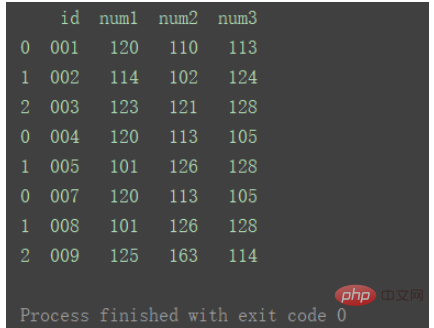
如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。
result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result)
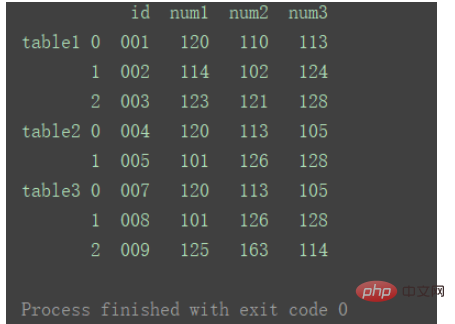
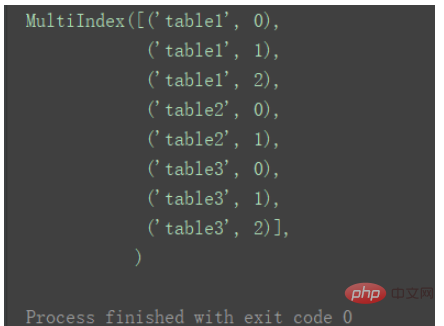
此时,添加的keys与原来的index组成元组,共同成为新的index。
print(result.index)
2.横向表合并(行对齐)
准备两组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
print(df1)
print("=======================================")
print(df2)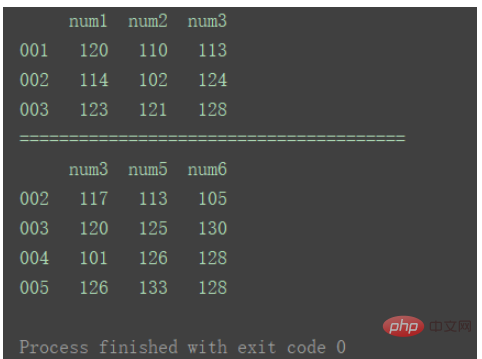
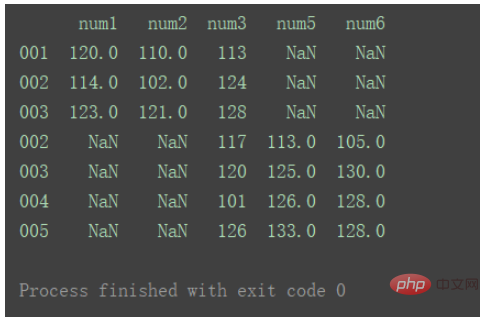
当axis为默认值0时:
result = pd.concat([df1, df2]) print(result)
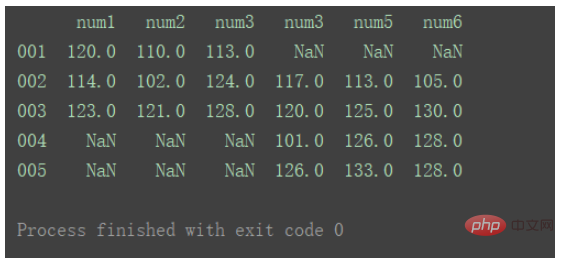
横向合并需要将axis设置为1 :
result = pd.concat([df1, df2], axis=1) print(result)
对比以上输出差异。
axis=0时,即默认纵向合并时,如果出现重复的行,则会同时体现在结果中
axis=1时,即横向合并时,如果出现重复的列,则会同时体现在结果中。
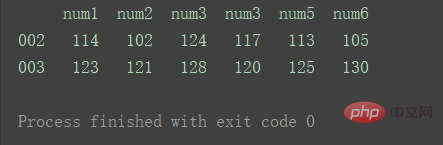
3.交叉合并
result = pd.concat([df1, df2], axis=1, join='inner') print(result)
위 내용은 Python에서 DataFrame을 사용하여 데이터를 병합하고 결합하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!