
Python의 pandas 라이브러리를 사용하여 다중 레벨 인덱스(MultiIndex)를 만드는 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-07 14:55:082915검색
Introduction
pd.MultiIndex, 여러 수준의 인덱스입니다. 다단계 인덱스를 통해 인덱스 그룹 전체의 데이터를 운용할 수 있습니다. 이 글에서는 주로 Pandas에서 다단계 인덱스를 생성하는 6가지 방법을 소개합니다:
pd.MultiIndex.from_arrays(): 다차원 배열은 매개변수로 사용되며, 고차원은 고차원 인덱스를 지정하고, 저차원은 지정합니다. 하위 수준 인덱스.
pd.MultiIndex.from_tuples(): 인수인 튜플 목록, 각 튜플은 각 인덱스(고차원 인덱스 및 저차원 인덱스)를 지정합니다.
pd.MultiIndex.from_product(): 반복 가능한 개체 목록이 매개 변수로 사용되며, 여러 반복 가능한 개체 요소의 데카르트 곱(요소 쌍별 조합)을 기반으로 인덱스가 생성됩니다.
pd.MultiIndex.from_frame: 기존 데이터 프레임을 기반으로 직접 생성
groupby(): 데이터 그룹화 통계를 통해 획득
pivot_table(): 피벗 테이블 생성을 통해 획득
pd .MultiIndex.from_arrays()
In [1]:
import pandas as pd import numpy as np
는 일반적으로 목록의 요소를 지정하는 배열을 통해 생성됩니다.
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [ 3]:
type(m1) # 查看数据类型
type 함수를 통해 데이터 유형을 보고 그것이 실제로 맞는지 확인합니다. MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
생성할 때 각 수준의 이름을 지정할 수 있습니다:
In [4 ]:
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])다음 예에서는 세 가지 수준의 인덱스를 생성하고 이름을 지정합니다.
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])pd.MultiIndex.from_tuples ()
튜플 형태로 다중 레벨 인덱스 생성:
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5Out[7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)list 및 튜플은 다음과 같습니다. 혼합
가장 바깥쪽 레이어는 목록입니다
내부는 모두 튜플입니다
In [8]:
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"])
m6Out[8]:
MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)pd.MultiIndex. 반복 가능한 객체 목록을 매개변수로 지정하고 여러 반복 가능한 객체 요소의 데카르트 곱(요소 쌍별 조합)을 기반으로 인덱스를 생성합니다.
Python에서는
함수를 사용하여 Python 객체가 반복 가능한지 여부를 결정합니다.# 导入 collections 模块的 Iterable 对比对象 from collections import Iterable
isinstance()

 위의 예를 통해 요약하면 다음과 같습니다. 공통 문자열, 목록, 집합, 튜플 및 사전은 모두 반복 가능합니다. 개체
위의 예를 통해 요약하면 다음과 같습니다. 공통 문자열, 목록, 집합, 튜플 및 사전은 모두 반복 가능합니다. 개체
다음은 설명을 위한 예입니다.
In [18]:
names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7Out[18]:
MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number'])In [19]:
# 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8Out[19]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [20]:
# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9 Out[20]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [21]:
# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10Out[21]:
MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [22]:
# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18총 개수는 ``332=18`입니다:
Out[ 22 ]:
MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])pd.MultiIndex.from_frame()
기존 DataFrame을 통해 다단계 인덱스 직접 생성:
df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
df
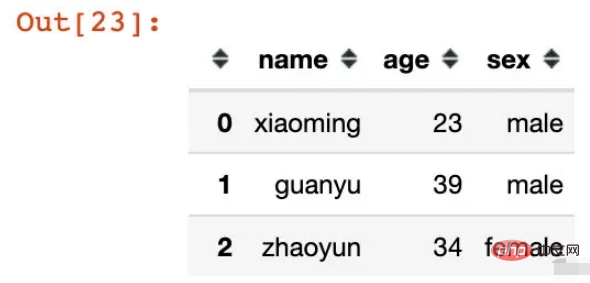 다단계 인덱스가 직접 생성되며 이름은 의 컬럼 필드입니다. 기존 데이터 프레임:
다단계 인덱스가 직접 생성되며 이름은 의 컬럼 필드입니다. 기존 데이터 프레임:
In [24]:
pd.MultiIndex.from_frame(df)
Out[24]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])names 매개변수를 통해 이름 지정:
In [25]:
# 可以自定义名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[25]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])groupby ()
groupby 함수를 통해 그룹화 함수는 다음과 같이 계산됩니다.
In [26]:
df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1Out[26]:
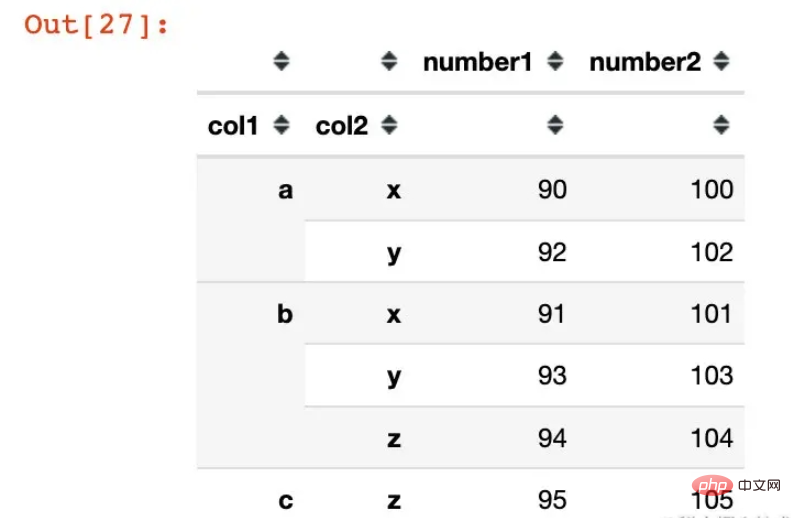
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2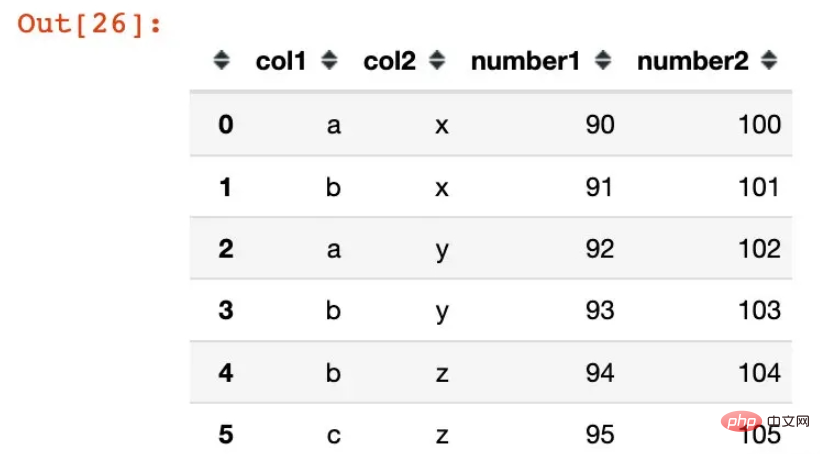
 데이터 인덱스 보기:
데이터 인덱스 보기:
In [ 28]:
df2.index
Out[28]:
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])pivot_table()
은 피벗 함수를 통해 얻습니다.
In [29]:
df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3
 In [30]:
In [30]:
df3.index
Out[30 ]:
아아아아위 내용은 Python의 pandas 라이브러리를 사용하여 다중 레벨 인덱스(MultiIndex)를 만드는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!