
Java 로드 밸런싱 알고리즘의 역할은 무엇입니까?

- PHPz앞으로
- 2023-05-07 14:37:18893검색
머리말
로드 밸런싱에는 Java 분야에서 광범위하고 심층적인 응용 프로그램이 있습니다. 유명한 nginx이든 dubbo, feign 등과 같은 마이크로서비스 거버넌스 구성 요소이든 로드 밸런싱 알고리즘이 실제로 사용됩니다.
핵심입니다. 로드 밸런싱의 아이디어는 기본 알고리즘 아이디어에 있습니다. 예를 들어 잘 알려진 알고리즘에는 폴링, 무작위, 최소 연결, 가중 폴링 등이 포함됩니다. 실제로는 어떻게 구성하든 핵심 원칙 없이는 할 수 없습니다. 다음은 일반적으로 사용되는 로드 밸런싱 알고리즘에 대한 포괄적인 요약을 만들기 위해 실제 코드와 결합됩니다.
폴링 알고리즘
폴링은 대기열에 줄을 서서 차례로 차례대로 진행하는 것을 의미합니다. 데이터 구조를 보면 링 모양의 노드가 있고, 그 위에 서버가 덮여 있고, 서버들은 끝에서 끝까지 연결되어 있고 순차적이다. 요청이 오면 특정 노드의 서버가 응답하기 시작하고 다음 번에 요청이 오면 후속 서버가 차례로 응답하고 거기서부터 계속됩니다. 이 알고리즘을 시뮬레이션하고 구현하기 위한 양방향(양방향 끝) 연결 목록 데이터 구조
1. 서버에서 연결 목록 노드를 식별하기 위한 서버 클래스를 정의합니다class Server {
Server prev;
Server next;
String name;
public Server(String name) {
this.name = name;
}
}
코드를 이해하기 위해 주석과 결합하여 이 코드에 대한 설명은 이중 끝 연결 목록의 기본 기능을 검사하는 것입니다. 연결 목록 구조를 작동할 때 가장 중요한 것은 노드의 앞/뒤 포인팅을 명확히 하는 것입니다. 노드를 추가하고 제거하면 더 이상 어려움이 없습니다. 아래 프로그램을 실행하세요
폴링 알고리즘의 장점과 단점을 요약합니다
머신이 간단합니다. 목록은 자유롭게 추가하거나 뺄 수 있습니다. 노드 검색 시간 복잡도는 o(1)
노드에 대해 편향된 사용자 정의를 수행할 수 없습니다. 예를 들어, 강력한 처리 기능과 높은 구성을 갖춘 일부 서버는 가능합니다. 더 많은 요청을 견딜 수 없습니다.
무작위 알고리즘
from 응답은 사용 가능한 서버 목록에서 무작위로 제공됩니다.
랜덤 액세스 시나리오이기 때문에 배열을 사용하면 첨자를 통해 더 효율적으로 랜덤 읽기를 완료할 수 있다고 생각하기 쉽습니다. 이 알고리즘의 시뮬레이션은 비교적 간단합니다. 아래 코드가 바로 표시됩니다.
/**
* 轮询
*/
public class RData {
private static Logger logger = LoggerFactory.getLogger(RData.class);
//标识当前服务节点,每次请求过来时,返回的是current节点
private Server current;
public RData(String serverName) {
logger.info("init servers : " + serverName);
String[] names = serverName.split(",");
for (int i = 0; i < names.length; i++) {
Server server = new Server(names[i]);
//当前为空,说明首次创建
if (current == null) {
//current就指向新创建server
this.current = server;
//同时,server的前后均指向自己
current.prev = current;
current.next = current;
} else {
//说明已经存在机器了,则按照双向链表的功能,进行节点添加
addServer(names[i]);
}
}
}
//添加机器节点
private void addServer(String serverName) {
logger.info("add new server : " + serverName);
Server server = new Server(serverName);
Server next = this.current.next;
//在当前节点后插入新节点
this.current.next = server;
server.prev = this.current;
//由于是双向链表,修改下一节点的prev指针
server.next = next;
next.prev = server;
}
//机器节点移除,修改节点的指向即可
private void removeServer() {
logger.info("remove current = " + current.name);
this.current.prev.next = this.current.next;
this.current.next.prev = this.current.prev;
this.current = current.next;
}
//请求。由当前节点处理
private void request() {
logger.info("handle server is : " + this.current.name);
this.current = current.next;
}
public static void main(String[] args) throws Exception {
//初始化两台机器
RData rr = new RData("192.168.10.0,192.168.10.1");
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
rr.request();
}
}
}).start();
//3s后,3号机器加入清单
Thread.currentThread().sleep(2000);
rr.addServer("192.168.10.3");
//3s后,当前服务节点被移除
Thread.currentThread().sleep(3000);
rr.removeServer();
}
}코드를 실행해 보세요. 그리고 결과를 관찰하세요:
랜덤 알고리즘 요약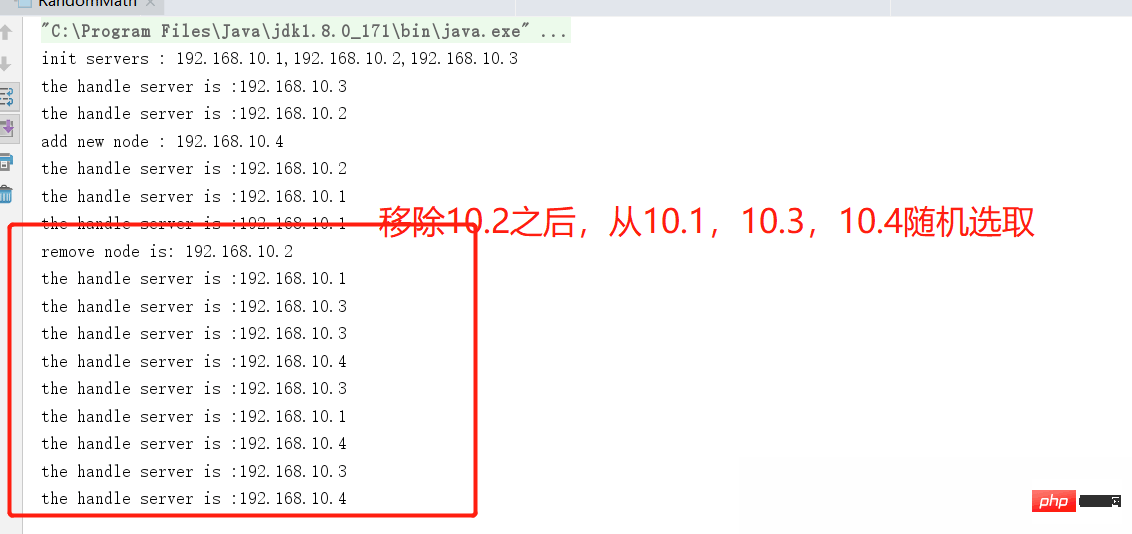
랜덤 알고리즘은 간단하고 효율적입니다.
폴링처럼 각 머신의 구성이 유사한 서버 클러스터에 적합합니다. , 각 서버 자체의 구성을 기반으로 일부 방향성을 구분하는 것은 불가능합니다.
Weighted Random Algorithm
무작위 선택을 기반으로 기계는 여전히 무작위로 선택되지만 가중치 집합은 다음과 같습니다. 서로 다른 가중치에 따라 기계 목록의 각 기계가 선택될 확률이 다릅니다. 이러한 관점에서 이해하면 무작위성은 각각의 기계를 제외하고는 동일한 가중치의 특별한 경우로 간주될 수 있습니다. 기계는 가중치의 크기에 따라 다른 수의 노드를 생성해야 합니다. 노드가 대기열에 추가되면 무작위로 획득됩니다. 여기의 데이터 구조는 주로 무작위 읽기를 포함하므로 배열이 바람직합니다
/**
* 随机
*/
public class RandomMath {
private static List<String> ips;
public RandomMath(String nodeNames) {
System.out.println("init servers : " + nodeNames);
String[] nodes = nodeNames.split(",");
//初始化服务器列表,长度取机器数
ips = new ArrayList<>(nodes.length);
for (String node : nodes) {
ips.add(node);
}
}
//请求处理
public void request() {
Random ra = new Random();
int i = ra.nextInt(ips.size());
System.out.println("the handle server is :" + ips.get(i));
}
//添加节点,注意,添加节点可能会造成内部数组扩容
void addnode(String nodeName) {
System.out.println("add new node : " + nodeName);
ips.add(nodeName);
}
//移除
void remove(String nodeName) {
System.out.println("remove node is: " + nodeName);
ips.remove(nodeName);
}
public static void main(String[] args) throws Exception {
RandomMath rd = new RandomMath("192.168.10.1,192.168.10.2,192.168.10.3");
//使用一个线程,模拟不间断的请求
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
rd.request();
}
}
}).start();
//间隔3秒之后,添加一台新的机器
Thread.currentThread().sleep(3000);
rd.addnode("192.168.10.4");
//3s后,当前服务节点被移除
Thread.currentThread().sleep(3000);
rd.remove("192.168.10.2");
}
}
가중치 값 10.1을 더 큰 값(예: 3)으로 조정하고 다시 실행하면 효과는 다음과 같습니다. 더 확실해
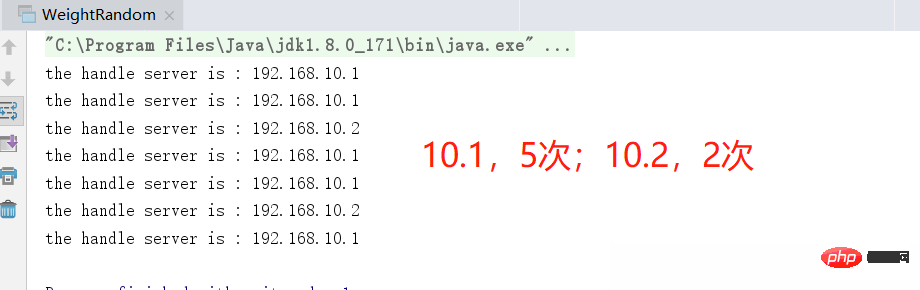
가중 무작위 알고리즘 요약

은 무작위 알고리즘의 업그레이드 및 최적화
- 서버 노드 편향 문제를 어느 정도 해결했으며, 편향을 개선할 수 있습니다. 가중치를 지정하여 특정 기계
- 가중 폴링 알고리즘
이전 폴링 알고리즘에서 폴링은 양방향 연결 목록에서 계속 이동하는 기계적 회전일 뿐인 반면, 가중치 폴링은 단점을 보완하는 것이라고 보았습니다. 모든 기계는 동등하게 취급됩니다. 폴링을 기반으로 서버가 초기화되면 각 기계는 가중치 값을 전달합니다.
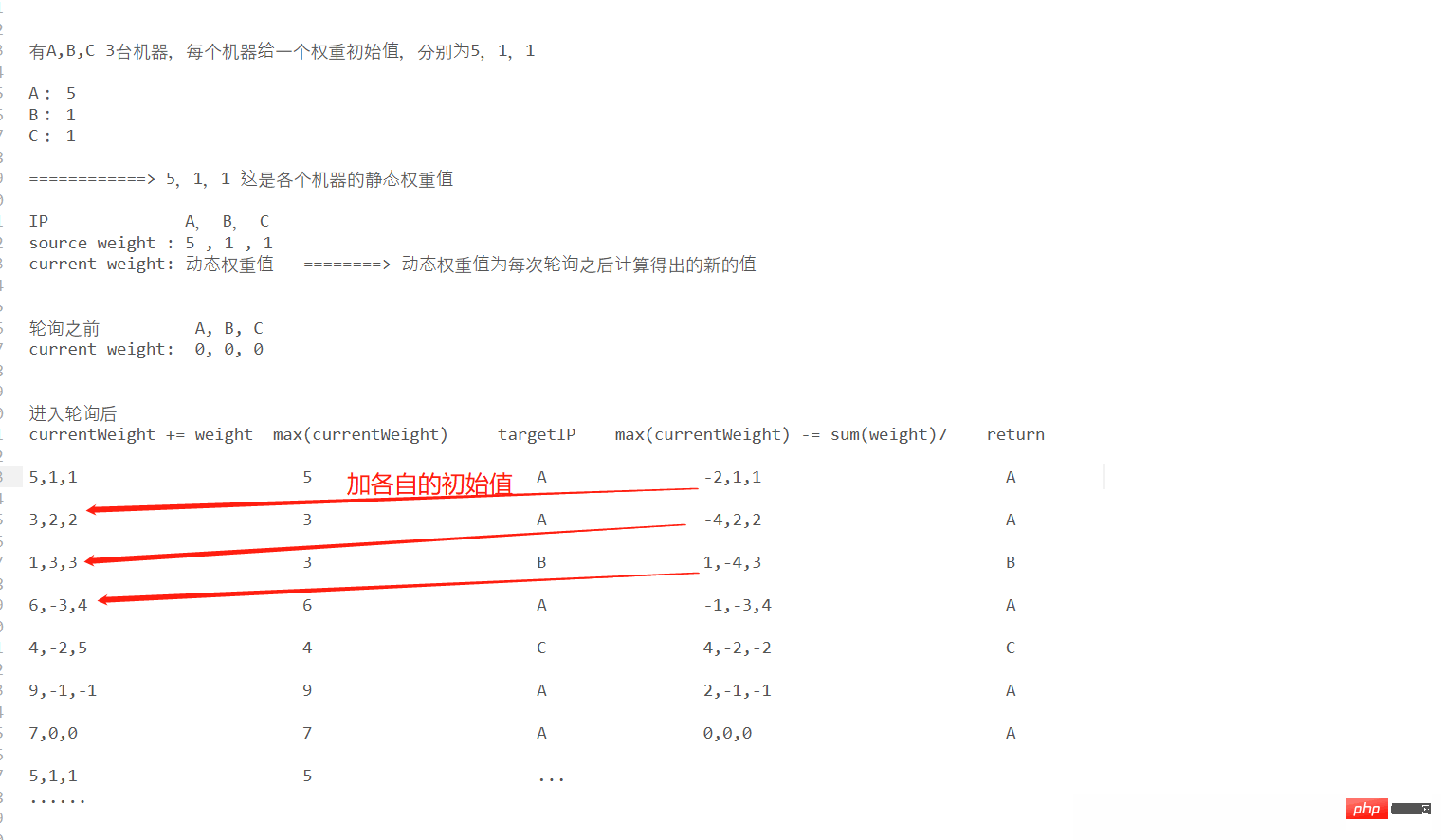
가중 폴링 알고리즘의 원래 의도는 이러한 일련의 알고리즘을 통해 전반적인 요청의 원활성을 보장하는 것입니다. 원래 결과와 특정 여론 조사에서 서로 다른 기계는 서로 다른 가중치 값을 기반으로 요청을 읽을 확률이 다릅니다
实现思路和轮询差不多,整体仍然是链表结构,不同的是,每个具体的节点需加上权重值属性
1、节点属性类
class NodeServer {
int weight;
int currentWeight;
String ip;
public NodeServer(String ip, int weight) {
this.ip = ip;
this.weight = weight;
this.currentWeight = 0;
}
@Override
public String toString() {
return String.valueOf(currentWeight);
}
}2、核心代码
/**
* 加权轮询
*/
public class WeightRDD {
//所有机器节点列表
ArrayList<NodeServer> list;
//总权重
int total;
//机器节点初始化 , 格式:a#4,b#2,c#1,实际操作时可根据自己业务定制
public WeightRDD(String nodes) {
String[] ns = nodes.split(",");
list = new ArrayList<>(ns.length);
for (String n : ns) {
String[] n1 = n.split("#");
int weight = Integer.valueOf(n1[1]);
list.add(new NodeServer(n1[0], weight));
total += weight;
}
}
public NodeServer getCurrent() {
for (NodeServer node : list) {
node.currentWeight += node.weight;
}
NodeServer current = list.get(0);
int i = 0;
//从列表中获取当前的currentWeight最大的那个作为待响应的节点
for (NodeServer node : list) {
if (node.currentWeight > i) {
i = node.currentWeight;
current = node;
}
}
return current;
}
//请求,每次得到请求的节点之后,需要对当前的节点的currentWeight值减去 sumWeight
public void request() {
NodeServer node = this.getCurrent();
System.out.print(list.toString() + "‐‐‐");
System.out.print(node.ip + "‐‐‐");
node.currentWeight -= total;
System.out.println(list);
}
public static void main(String[] args) throws Exception {
WeightRDD wrr = new WeightRDD("192.168.10.1#4,192.168.10.2#2,192.168.10.3#1");
//7次执行请求,观察结果
for (int i = 0; i < 7; i++) {
Thread.currentThread().sleep(2000);
wrr.request();
}
}
}从打印输出结果来看,也是符合预期效果的,具有更大权重的机器,在轮询中被请求到的可能性更大

源地址hash算法
即对当前访问的ip地址做一个hash值,相同的key将会被路由到同一台机器去。常见于分布式集群环境下,用户登录 时的请求路由和会话保持
源地址hash算法可以有效解决在跨地域机器部署情况下请求响应的问题,这一特点使得源地址hash算法具有某些特殊的应用场景
该算法的核心逻辑是需要自定义一个能结合实际业务场景的hash算法,从而确保请求能够尽可能达到源IP机器进行处理
源地址hash算法的实现比较简单,下面直接上代码
/**
* 源地址请求hash
*/
public class SourceHash {
private static List<String> ips;
//节点初始化
public SourceHash(String nodeNames) {
System.out.println("init list : " + nodeNames);
String[] nodes = nodeNames.split(",");
ips = new ArrayList<>(nodes.length);
for (String node : nodes) {
ips.add(node);
}
}
//添加节点
void addnode(String nodeName) {
System.out.println("add new node : " + nodeName);
ips.add(nodeName);
}
//移除节点
void remove(String nodeName) {
System.out.println("remove one node : " + nodeName);
ips.remove(nodeName);
}
//ip进行hash
private int hash(String ip) {
int last = Integer.valueOf(ip.substring(ip.lastIndexOf(".") + 1, ip.length()));
return last % ips.size();
}
//请求模拟
void request(String ip) {
int i = hash(ip);
System.out.println("req ip : " + ip + "‐‐>" + ips.get(i));
}
public static void main(String[] args) throws Exception {
SourceHash hash = new SourceHash("192.168.10.1,192.168.10.2");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.addnode("192.168.10.3");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.remove("192.168.10.1");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
}
}请关注核心的方法 hash(),我们模拟9个随机请求的IP,下面运行下这段程序,观察输出结果
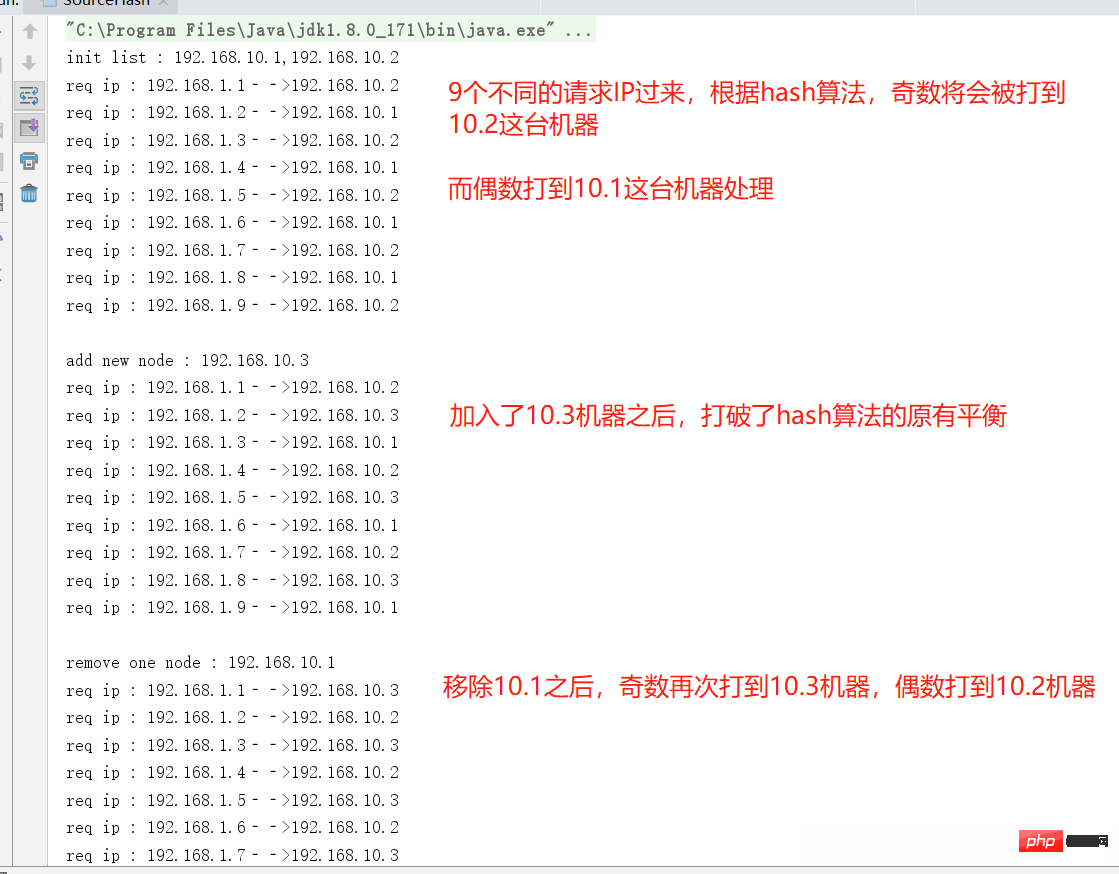
源地址hash算法小结
可以有效匹配同一个源IP从而定向到特定的机器处理
如果hash算法不够合理,可能造成集群中某些机器压力非常大
未能很好的解决新节点加入之后打破原来的请求平衡(一致性hash可解决)
最小请求数算法
即通过统计当前机器的请求连接数,选择当前连接数最少的机器去响应新请求。前面的各种算法是基于请求的维度,而最小 连接数则是站在机器的连接数量维度
从描述来看,实现这种算法需要定义一个链接表记录机器的节点IP,和机器连接数量的计数器
而为了比较并选择出最小的连接数的机器,内部采用最小堆做排序处理,请求响应时取堆顶节点即是 最小连接数(可以参考最小顶堆算法)
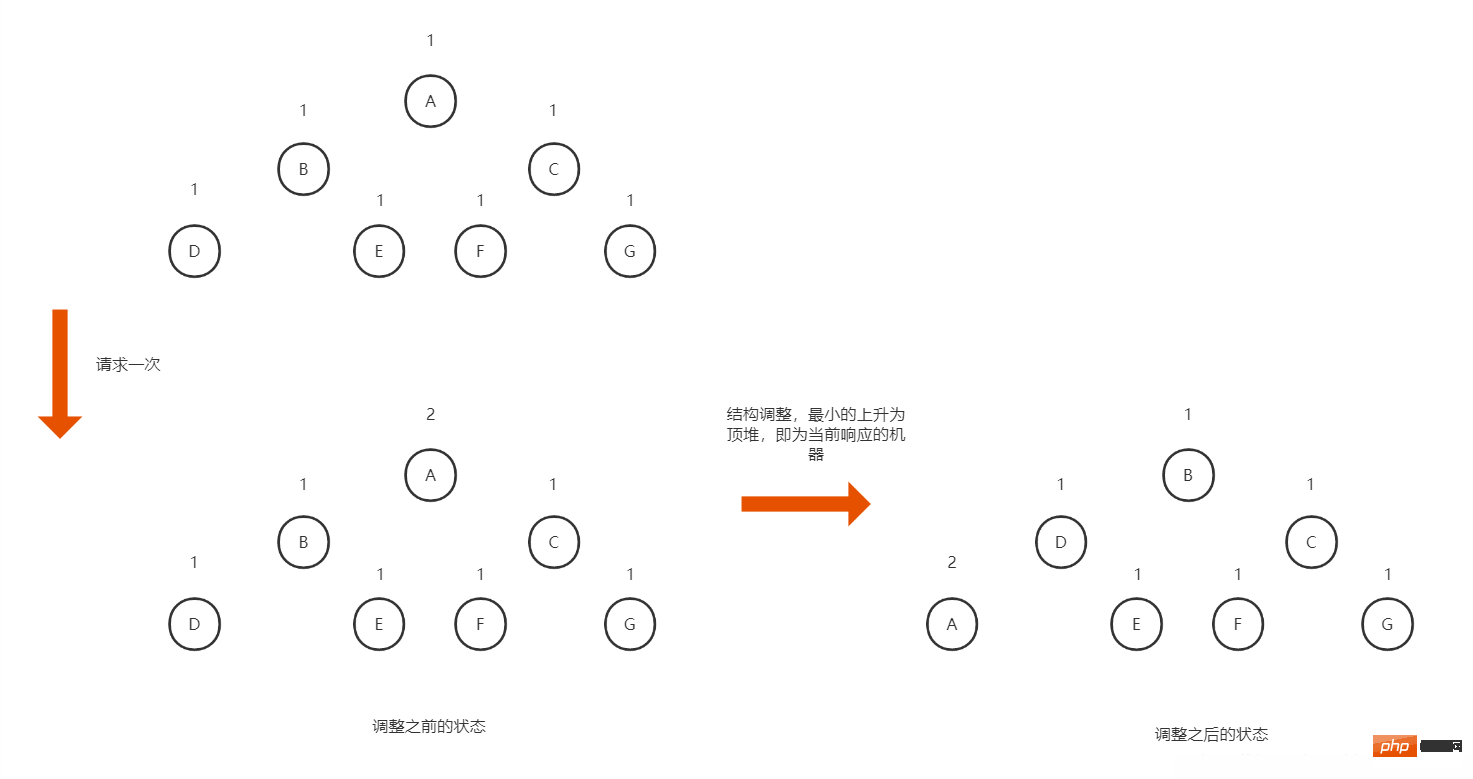
如图所示,所有机器列表按照类二叉树的结构进行组装,组装的依据按照不同节点的访问次数,某次请求过来时,选择堆顶的元素(待响应的机器)返回,然后堆顶机器的请求数量加1,然后通过算法将这个堆顶的元素下沉,把请求数量最小的元素上升为堆顶,以便下次响应最新的请求
1、机器节点
该类记录了节点的IP以及连接数
class Node {
String name;
AtomicInteger count = new AtomicInteger(0);
public Node(String name) {
this.name = name;
}
public void inc() {
count.getAndIncrement();
}
public int get() {
return count.get();
}
@Override
public String toString() {
return name + "=" + count;
}
}2、核心代码
/**
* 最小连接数算法
*/
public class LeastRequest {
Node[] nodes;
//节点初始化
public LeastRequest(String ns) {
String[] ns1 = ns.split(",");
nodes = new Node[ns1.length + 1];
for (int i = 0; i < ns1.length; i++) {
nodes[i + 1] = new Node(ns1[i]);
}
}
///节点下沉,与左右子节点比对,选里面最小的交换
//目的是始终保持最小堆的顶点元素值最小【结合图理解】
//ipNum:要下沉的顶点序号
public void down(int ipNum) {
//顶点序号遍历,只要到1半即可,时间复杂度为O(log2n)
while (ipNum << 1 < nodes.length) {
int left = ipNum << 1;
//右子,左+1即可
int right = left + 1;
int flag = ipNum;
//标记,指向 本节点,左、右子节点里最小的,一开始取自己
if (nodes[left].get() < nodes[ipNum].get()) {
flag = left;
}
//判断右子
if (right < nodes.length && nodes[flag].get() > nodes[right].get()) {
flag = right;
}
//两者中最小的与本节点不相等,则交换
if (flag != ipNum) {
Node temp = nodes[ipNum];
nodes[ipNum] = nodes[flag];
nodes[flag] = temp;
ipNum = flag;
} else {
//否则相等,堆排序完成,退出循环即可
break;
}
}
}
//请求,直接取最小堆的堆顶元素就是连接数最少的机器
public void request() {
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
//取堆顶元素响应请求
Node node = nodes[1];
System.out.println(node.name + " accept");
//连接数加1
node.inc();
//排序前的堆
System.out.println("ip list before:" + Arrays.toString(nodes));
//堆顶下沉,通过算法将堆顶下层到合适的位置
down(1);
//排序后的堆
System.out.println("ip list after:" + Arrays.toString(nodes));
}
public static void main(String[] args) {
//假设有7台机器
LeastRequest lc = new LeastRequest("10.1,10.2,10.3,10.4,10.5,10.6,10.7");
//模拟10个请求连接
for (int i = 0; i < 10; i++) {
lc.request();
}
}
}请关注 down 方法,该方法是实现每次请求之后,将堆顶元素进行移动的关键实现,运行这段代码,结合输出结果进行理解


위 내용은 Java 로드 밸런싱 알고리즘의 역할은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!