
Java String에서 인턴 메소드를 사용하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-05 17:28:131369검색
상수 풀 소개
JAVA 언어에는 8가지 기본 유형과 특수 유형 문자열이 있습니다. 더 빠르게 실행하고 더 많은 메모리를 절약하기 위해 이러한 유형은 (메소드 영역에서) 상수 풀 개념을 제공합니다. 상수 풀은 JAVA 시스템 레벨에서 제공하는 캐시와 유사합니다. 8가지 기본 유형의 상수 풀은 모두 시스템에 의해 조정되며 문자열 유형의 상수 풀은 특별합니다.
문자열 상수 풀을 사용하는 두 가지 주요 방법이 있습니다.
큰따옴표를 사용하여 직접 선언된 문자열 개체는 상수 풀에 직접 저장됩니다.
String 객체가 큰따옴표로 선언되지 않은 경우 String에서 제공하는 intern 메소드를 사용하여 상수 풀에 넣을 수 있습니다.
인턴 메소드 소개(JDK7)
Prototype: public Native String intern();
Description:
문자열 상수 풀에서 현재 문자열이 존재하는지 쿼리합니다(동일로 판단).
있는 경우 상수 풀의 문자열 참조를 반환합니다.
존재하지 않는 경우 String 개체 참조를 상수 풀에 저장한 다음 String 개체 참조를 반환합니다.
반환 값: 모두 String 변수에 해당하는 문자열 상수 풀에 대한 참조를 반환합니다.
예
package com.example;
public class Demo {
public static void main(String argv[]) {
String s = "test";
System.out.println(s == s.intern());
}
}JDK6 이전: false 출력
JDK7 이후: true 출력
Principle(JDK6 및 JDK7)
상수 풀에 있는 문자열의 출처
JDK6 및 String.intern 호출 이전 ( )
상수 풀에 상수가 있으면 상수 풀에 있는 문자열에 대한 참조를 반환합니다.
상수 풀에 상수가 없으면 객체의 복사본을 복사하여 상수 풀(영구 생성), 반환 값은 상수 풀(영구 생성)의 해당 문자열 인스턴스에 대한 참조입니다.
JDK7 이상에서는 String.intern()을 호출합니다.
상수 풀에 문자열이 있으면 상수 풀에 문자열 참조를 반환합니다.
상수 풀에 문자열이 없으면 참조를 복사하여 상수 풀(힙)에 넣습니다. (JDK1.7은 문자열 상수 풀을 Perm 영역에서 Java 힙 영역으로 이동했습니다.)
Routine test
Routine 1:
package org.example.a;
public class Demo {
public static void main(String argv[]) {
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
}Result
jdk6: false false
jdk7: false true
jdk8: false true
Routine 2:
package org.example.a;
public class Demo {
public static void main(String argv[]) {
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
}위 코드의 두 번째 부분에 swap이 있습니다.
Result
jdk6: false false
jdk7: false false
jdk8: false false
Routine analyze
아래 그림에서 녹색 선은 String 개체의 콘텐츠 포인터를 나타냅니다. 빨간색 선은 주소 지정을 나타냅니다.
jdk1.6
위 그림과 같이 루틴 1과 루틴 2
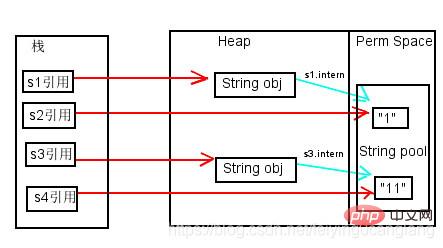
를 분석합니다. 먼저 jdk6의 상황에 대해 이야기해 보겠습니다. jdk6의 상수 풀은 Perm 영역에 배치되고 Perm 영역은 일반 JAVA Heap 영역과 완전히 분리되어 있기 때문에 위의 모든 인쇄는 거짓입니다. 위에서 언급한 것처럼 따옴표를 사용하여 문자열을 선언하면 문자열 상수 풀에 직접 생성되고, 새로운 String 객체가 JAVA Heap 영역에 배치됩니다. 따라서 JAVA Heap 영역의 객체 주소와 문자열 상수 풀의 객체 주소를 비교하는 것은 확실히 다릅니다. String.intern 메소드를 호출하더라도 아무런 관계가 없습니다.
jdk1.7
Jdk6 및 이전 버전에서는 문자열의 상수 풀이 힙의 Perm 영역에 배치됩니다. Perm 영역은 주로 로드된 클래스, 상수 풀, 프래그먼트 및 기타 콘텐츠의 기본 크기는 4m에 불과합니다. 인턴이 상수 풀에서 광범위하게 사용되면 java.lang.OutOfMemoryError:PermGen 공간 오류가 발생합니다. jdk7 버전에서는 문자열 상수 풀이 Perm 영역에서 일반 Java Heap 영역으로 이동되었습니다. 이전이 필요한 주된 이유는 Perm 영역이 너무 작기 때문입니다. 물론 뉴스에 따르면 jdk8은 Perm 영역을 직접 취소하고 새로운 메타 영역을 구축했습니다. jdk 개발자는 Perm 영역이 현재 JAVA 개발에 더 이상 적합하지 않다고 생각해야 합니다. 문자열 상수 풀이 JAVA Heap 영역으로 이동되었습니다. 이제 위와 같은 결과가 출력되는 이유를 설명하겠습니다.
루틴 1의 분석
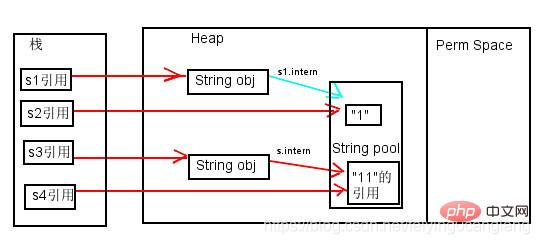
1.String s1 = new String("1");
분석: 이 코드 줄은 2개의 개체(상수에서 "1" 및 "1")를 생성합니다. JavaHeap의 풀 문자열 객체). s.intern(); 이 문장은 s1 객체가 상수 풀로 이동하여 검색한 결과 "1"이 이미 상수 풀에 있음을 발견했음을 의미합니다.
이때 s1은 Java Heap의 문자열 객체를 가리킵니다.
2.String s2 = "1";
분석: 이 코드 줄은 상수 풀의 "1" 개체를 가리키는 s2에 대한 참조를 생성합니다. 결과적으로 s1과 s2의 참조 주소가 다릅니다.
3.String s3 = new String("1") + new String("1");
分析:这行代码生成了2个对象(字符串常量池中的“1” 和 Java Heap中的 s3 引用指向的对象“11”(中间还有2个匿名的new String("1")我们不讨论它)。
此时s3 是Java Heap中的字符串对象的引用,对象内容是”11″,此时常量池中是没有 “11”对象的。
4.s3.intern();
分析:这行代码将 s3中的"11"字符串放入String 常量池中,因为此时常量池中不存在"11"字符串,因此常规做法是跟 jdk6 图中表示的那样,在常量池中生成一个"11"的对象,关键点是 jdk7 中常量池不在Perm区域,而是在堆中了。常量池中不需再存储一份对象了,可以直接存储堆中的引用。这份引用指向s3引用的对象。 也就是说引用地址是相同的。
此时,s3是Java Heap中的字符串对象的引用,对象内容是”11″,此时常量池中是有 “11”对象,它保存的就是s3引用地址。
5.String s4 = "11";
这行代码”11″是显式声明的,因此会直接去常量池中创建,创建时发现已经有这个对象了。
此时:s4 == 常量池的“11”对象引用 == s3引用对象的引用
例程2的分析
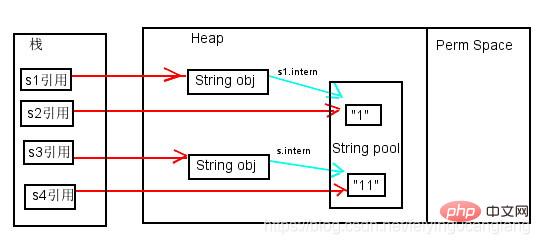
String s1 = new String("1");
s1.intern();
String s2 = "1";
分析:s1.intern();,这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s1 和 s2 的引用地址是不会相等的。
String s3 = new String("1") + new String("1");
分析:这行代码生成了2个对象(字符串常量池中的“1” 和 Java Heap中的 s3 引用指向的对象“11”(中间还有2个匿名的new String("1")我们不讨论它)。
此时s3 是Java Heap中的字符串对象的引用,对象内容是”11″,此时常量池中是没有 “11”对象的。
String s4 = "11";
分析:声明 s4 的时候常量池中是不存在“11”对象的,执行完后,s4是常量池里“11“对象的引用。
s3.intern();
分析:此时常量池中“11”对象已经存在了,不会有任何操作,s3仍然是堆中String对象的引用。因此 s3 != s4
应用实例
package org.example.a;
import java.util.Random;
public class Demo {
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String argv[]) {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for(int i = 0; i < DB_DATA.length; i++){
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for(int i = 0; i < MAX; i++){
//arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() -t) + "ms");
System.gc();
}
}上述代码是一个演示代码,其中有两条语句不一样,一条是使用 intern,一条是未使用 intern。
运行的参数是:-Xmx2g -Xms2g -Xmn1500M
不用intern
2160ms
使用intern
826ms
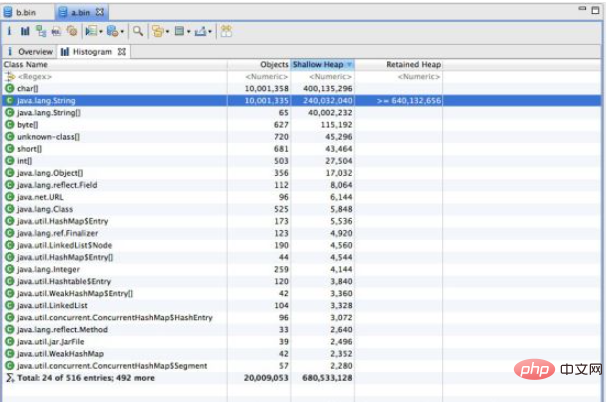
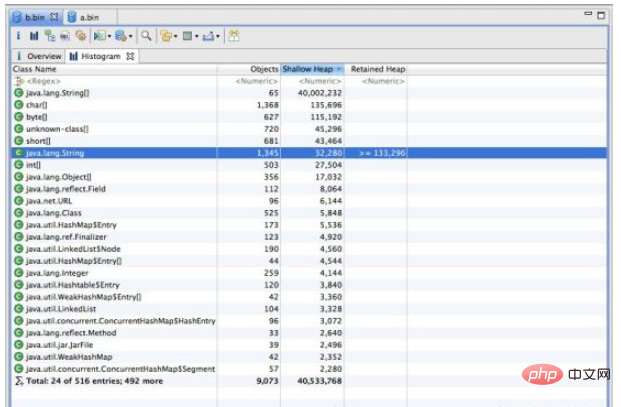
通过上述结果,我们发现不使用 intern 的代码生成了1000w 个字符串,占用了大约640m 空间。 使用了 intern 的代码生成了1345个字符串,占用总空间 133k 左右。其实通过观察程序中只是用到了10个字符串,所以准确计算后应该是正好相差100w 倍。虽然例子有些极端,但确实能准确反应出 intern 使用后产生的巨大空间节省。
细心的同学会发现使用了 intern 方法后时间上有了一些增长。这是因为程序中每次都是用了 new String 后, 然后又进行 intern 操作的耗时时间,这一点如果在内存空间充足的情况下确实是无法避免的,但我们平时使用时,内存空间肯定不是无限大的,不使用 intern占用空间导致 jvm 垃圾回收的时间是要远远大于这点时间的。 毕竟这里使用了1000w次intern 才多出来1秒钟多的时间。
위 내용은 Java String에서 인턴 메소드를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!