
입문자용 머신러닝에 필요한 알고리즘은 무엇인가요?

- PHPz앞으로
- 2023-05-02 20:19:05915검색
K-최근접 이웃 알고리즘
k-최근접 이웃 알고리즘이란?

은 이웃을 기반으로 카테고리를 추론하는 것입니다
개념:
K 이 알고리즘은 일반적으로 기계 학습의 고전적인 알고리즘입니다. , KNN 알고리즘은 비교적 이해하기 쉬운 알고리즘입니다.
정의
특징 공간에서 가장 유사한 k개(즉, 특징 공간에서 가장 가까운 이웃) 샘플 중 특정 범주에 샘플이 속하면 해당 샘플도 이 범주에 속합니다.
출처: KNN 알고리즘은 Cover and Hart가 분류 알고리즘으로 처음 제안했습니다.
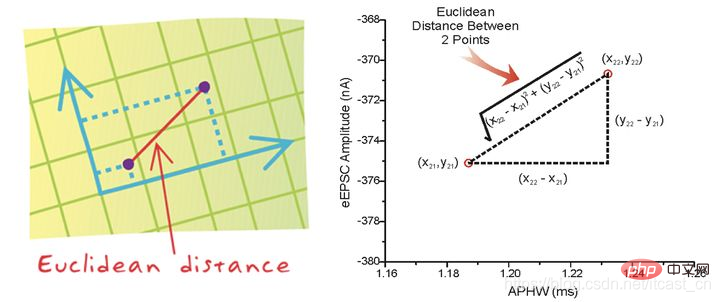
거리 공식
두 샘플 사이의 거리는 거리에 관해 유클리드 거리라고도 불리는 다음 공식으로 계산할 수 있습니다. 공식은 나중에 논의하겠습니다
선형 회귀
적용 시나리오는 다음과 같습니다. 주택 가격 예측, 매매 금액 예측, 대출 금액 예측
선형 회귀란 무엇인가요?
(1) 정의 및 수식
선형회귀는 회귀방정식(함수)을 이용하여 하나 이상의 독립변수(고유값)와 종속변수(목표값) 사이의 관계를 확립하는 모형을 분석하는 방법이다.
특징: 독립변수가 하나만 있는 상황을 단변량 회귀라고 하고, 독립변수가 두 개 이상인 상황을 다중 회귀라고 합니다.

행렬로 표현되는 선형 회귀의 예:
그럼 어떻게 이해하나요? 몇 가지 예를 살펴보겠습니다.
최종 성적: 0.7×시험 점수+0.3×평균 성적
집값 = 0.02×중심지로부터의 거리+0.04×도시 산화질소 농도+(-0.12×평균 이후) 주택 가격) + 0.254 × 도시 범죄율
위의 두 예에서 특성값과 목표값 사이에 관계가 설정되어 있는 것을 볼 수 있으며 이는 선형 모델로 이해할 수 있습니다.
로지스틱 회귀
로지스틱 회귀는 이름에 회귀가 있지만 분류 알고리즘입니다. 알고리즘의 단순성과 효율성으로 인해 실제로 널리 사용됩니다.
응용 시나리오: 광고 클릭률, 스팸 여부, 질병 여부, 금융 사기, 가짜 계정.
여기서 특징을 찾을 수 있습니다. 즉, 두 범주 간에 판단이 이루어진다는 것입니다. 로지스틱 회귀는 2분류 문제를 해결하는 강력한 도구입니다.
로지스틱 회귀를 마스터하려면 두 가지 점을 마스터해야 합니다.
로지스틱 회귀의 입력 값은 무엇입니까?
로지스틱 회귀의 결과를 어떻게 판단하나요?
입력:

활성화 함수: 시그모이드 함수

판정 기준
회귀 결과는 다음과 같이 입력됩니다. 시그모이드 함수에서 출력 결과는 다음과 같습니다. : [0, 1] 간격의 확률 값, 기본값은 임계값으로 0.5입니다.

로지스틱 회귀분석의 최종 분류는 특정 카테고리에 속할 확률값을 통해 특정 카테고리에 속하는지 판단하는 것으로 기본적으로 이 카테고리는 1(긍정적 예)로 표시되고, 다른 카테고리는 표시됩니다. 0(부정적인 예)으로 표시됩니다. (손실 계산 편리)
출력 결과 설명(중요): 두 개의 범주 A와 B가 있다고 가정하고, 우리의 확률 값은 범주 A(1)에 속하는 확률 값이라고 가정합니다. 이제 로지스틱 회귀 출력 결과 0.55에 대한 샘플 입력이 있으며, 이 확률 값은 0.5를 초과합니다. 이는 훈련 또는 예측 결과가 A(1) 범주임을 의미합니다. 반대로 결과가 0.3이면 훈련 또는 예측 결과는 B(0) 범주가 됩니다.
로지스틱 회귀의 임계값은 변경될 수 있습니다. 예를 들어 위의 예에서 임계값을 0.6으로 설정하면 출력 결과는 0.55로 카테고리 B에 속합니다.
결정 트리 알고리즘
결정 트리의 아이디어 유래는 매우 간단합니다. 프로그래밍의 조건 분기 구조는 최초의 결정 트리가 이를 이용한 분류 학습 방법입니다. 데이터를 분할하는 구조 종류
결정 트리: 각 내부 노드가 속성에 대한 판단을 나타내고, 각 가지가 판단 결과의 출력을 나타내고, 마지막으로 각 리프 노드가 분류 결과를 나타내는 트리 구조입니다. 본질은 여러 판단 노드로 구성된 A 트리입니다.
이 문장을 어떻게 이해해야 할까요? 대화 예시를 통해

위 사례는 질적 주관의식을 통해 나이를 최우선으로 생각하는 소녀입니다. 그렇다면 이 과정을 정량화해야 한다면 어떻게 처리해야 할까요?
이때 정보 이론의 지식인 정보 엔트로피와 정보 획득을 활용해야 합니다.
앙상블 알고리즘

앙상블 학습은 여러 모델을 구축하여 단일 예측 문제를 해결합니다. 여러 분류기/모델을 생성하여 각각 독립적으로 학습하고 예측하는 방식으로 작동합니다. 이러한 예측은 궁극적으로 단일 분류 예측보다 더 나은 결합된 예측으로 결합됩니다.
클러스터링 알고리즘

실용 응용 프로그램:
사용자 초상화, 광고 추천, 데이터 세분화, 검색 엔진 트래픽 추천, 악성 트래픽 식별
위치 정보 기반 비즈니스 푸시, 뉴스 클러스터링 , 필터링 및 정렬.
이미지 분할, 차원 감소, 인식, 이상치 감지, 동일한 기능을 가진 유전자 조각 발견.
클러스터링 알고리즘:
일반적인 비지도 학습 알고리즘으로, 유사한 샘플을 카테고리로 자동 분류하는 데 주로 사용됩니다.
클러스터링 알고리즘에서는 샘플 간의 유사성을 기준으로 여러 카테고리로 구분됩니다. 유사성 계산 방법이 다르면 클러스터링 결과도 달라집니다. 일반적으로 사용되는 유사성 계산 방법은 유럽식 거리법입니다.
위 내용은 입문자용 머신러닝에 필요한 알고리즘은 무엇인가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!