
Java에서 캐시 일관성을 보장하는 방법

- 王林앞으로
- 2023-05-02 13:13:161277검색
옵션 1: 캐시 업데이트, 데이터베이스 업데이트
이 방법은 쉽게 제거할 수 있습니다. 캐시가 먼저 성공적으로 업데이트되었지만 데이터베이스 업데이트가 실패하면 확실히 데이터 불일치가 발생하기 때문입니다.
옵션 2: 데이터베이스 업데이트 및 캐시 업데이트
이 캐시 업데이트 전략은 일반적으로 이중 쓰기로 알려져 있습니다. 문제는 동시 데이터베이스 업데이트 시나리오에서 더티 데이터가 캐시로 플러시된다는 것입니다
updateDB(); updateRedis();
예: 두 작업 사이에 후속 요청에 의해 데이터베이스와 캐시가 수정되는 경우 현재 캐시 업데이트는 이미 만료된 데이터입니다.

옵션 3: 캐시 삭제 및 데이터베이스 업데이트
문제: 데이터베이스를 업데이트하기 전에 쿼리 요청이 있으면 더티 데이터가 캐시로 플러시됩니다.
deleteRedis(); updateDB();
예: 두 작업 사이에 있는 경우 데이터 쿼리가 발생하면 오래된 데이터가 캐시에 저장됩니다.

이 솔루션을 사용하면 요청 데이터가 일관되지 않게 됩니다
업데이트 작업에 대한 요청 A가 하나 있고 쿼리 작업에 대한 다른 요청 B가 있는 경우. 그러면 다음과 같은 상황이 발생합니다.
A에게 쓰기 작업을 수행하고 캐시를 삭제하도록 요청
B에게 쿼리하여 캐시가 존재하지 않음을 확인하도록 요청
B에게 데이터베이스에 쿼리하여 캐시를 쿼리하도록 요청 이전 값
B에게 이전 값을 변경하도록 요청 쓰기 캐시
A에게 데이터베이스에 새 값을 쓰도록 요청
위의 상황은 불일치로 이어질 것입니다. 또한 캐시에 대한 만료 시간 전략을 설정하지 않으면 데이터는 항상 더티 데이터가 됩니다.
옵션 4: 데이터베이스를 업데이트하고 캐시를 삭제합니다.
문제가 있습니다. 데이터베이스를 업데이트하기 전에 쿼리 요청이 있으며 캐시가 유효하지 않아 데이터베이스를 쿼리한 후 캐시가 업데이트됩니다. . 데이터베이스 쿼리와 캐시 업데이트 사이에 데이터베이스 업데이트 작업이 수행되면 더티 데이터는 캐시로 플러시됩니다
updateDB(); deleteRedis();
예:데이터베이스를 쿼리하고 저장하는 두 작업 사이에 데이터 업데이트가 발생하는 경우 캐시에 저장하고 캐시를 삭제하면 오래된 데이터가 캐시에 저장됩니다.
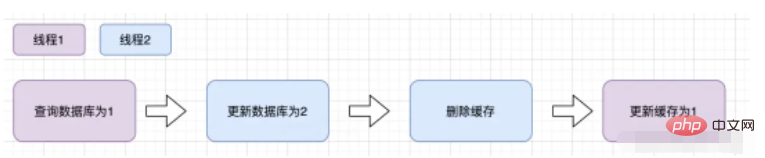
A에게 쿼리 작업을 수행하도록 요청하는 요청과 B에 업데이트 작업을 수행하도록 요청하는 요청이 있다고 가정하면 다음과 같은 상황이 발생합니다
캐시가 방금 만료됩니다
요청하는 중 A가 데이터베이스를 쿼리하면
값은 B에게 새 값을 데이터베이스에 쓰도록 요청
B는 캐시를 삭제하도록 요청
A는 발견된 이전 값을 데이터베이스에 쓰도록 요청합니다. 캐시
위의 상황이 발생하면 실제로 데이터가 더러워지게 됩니다. 그러나 위와 같은 상황이 발생하기 위해서는 선천적인 조건이 있습니다. 즉, 데이터베이스 작업을 쓰는 것이 데이터베이스 작업을 읽는 것보다 시간이 덜 걸립니다. 그러나 데이터베이스 읽기 작업의 속도가 쓰기 작업의 속도보다 훨씬 빠르기 때문에 이러한 상황이 발생합니다. 발생하기 어렵습니다.
계획 비교
계획 1과 계획 2의 일반적인 단점:데이터베이스를 동시에 업데이트하는 시나리오에서는 더티 데이터가 캐시로 플러시되지만 일반적으로 동시 쓰기 확률은 상대적으로 적습니다.
스레드 안전 관점에서는 다음과 같은 더티 데이터가 생성됩니다.
스레드 A가 데이터베이스를 업데이트했습니다
- 스레드 B가 데이터베이스를 업데이트했습니다
- 스레드 B가 캐시를 업데이트했습니다
- 캐시
- Scheme 3과 4의 공통 단점: 어떤 순서를 채택하든 2가지 방법에는 몇 가지 문제가 있습니다.
마스터-슬레이브 지연 문제: 먼저 삭제되는지 마지막에 삭제되는지 여부 , 데이터베이스 마스터-슬레이브 지연으로 인해 더티 데이터가 생성될 수 있습니다.
- 캐시 삭제 실패: 캐시 삭제에 실패하면 더티 데이터가 생성됩니다.
- 문제 해결 아이디어: 이중 삭제를 지연하고 아래에 소개된 재시도 메커니즘을 추가하세요!
- 캐시를 업데이트하거나 캐시를 삭제하시겠습니까?
1. 캐시를 업데이트하려면 일정 유지 비용이 필요하며 동시 업데이트에 문제가 발생합니다
- 2. 쓰기가 많고 읽기가 적은 경우 아직 읽기 요청이 오지 않고 캐시가 발생합니다. 여러번 업데이트되어 캐싱 역할을 하지 않습니다
- 3. 캐시에 입력되는 값이 업데이트될 때마다 계산이 복잡해질 수 있습니다
- 캐시 삭제의 장점:
간단하고 비용이 저렴하며 개발이 쉽다. 단점: 캐시 누락이 발생합니다.
캐시 업데이트 비용이 적고 읽기 횟수가 많고 쓰기 횟수가 적고 기본적으로 쓰기 동시성이 없으면 캐시를 업데이트할 수 있습니다. 그렇지 않은 경우 일반적인 접근 방식은 캐시를 삭제하는 것입니다.
总结
| 方案 | 问题 | 问题出现概率 | 推荐程度 |
|---|---|---|---|
| 更新缓存 -> 更新数据库 | 为了保证数据准确性,数据必须以数据库更新结果为准,所以该方案绝不可行 | 大 | 不推荐 |
| 更新数据库 -> 更新缓存 | 并发更新数据库场景下,会将脏数据刷到缓存 | 并发写场景,概率一般 | 写请求较多时会出现不一致问题,不推荐使用。 |
| 删除缓存 -> 更新数据库 | 更新数据库之前,若有查询请求,会将脏数据刷到缓存 | 并发读场景,概率较大 | 读请求较多时会出现不一致问题,不推荐使用 |
| 更新数据库 -> 删除缓存 | 在更新数据库之前有查询请求,并且缓存失效了,会查询数据库,然后更新缓存。如果在查询数据库和更新缓存之间进行了数据库更新的操作,那么就会把脏数据刷到缓存 | 并发读场景&读操作慢于写操作,概率最小 | 读操作比写操作更慢的情况较少,相比于其他方式出错的概率小一些。勉强推荐。 |
推荐方案
延迟双删
采用更新前后双删除缓存策略
public void write(String key,Object data){
redis.del(key);
db.update(data);
Thread.sleep(1000);
redis.del(key);
}先淘汰缓存
再写数据库
休眠1秒,再次淘汰缓存
大家应该评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
问题及解法:
1、同步删除,吞吐量降低如何处理
将第二次删除作为异步的,提交一个延迟的执行任务
2、解决删除失败的方式:
添加重试机制,例如:将删除失败的key,写入消息队列;但对业务耦合有些严重;
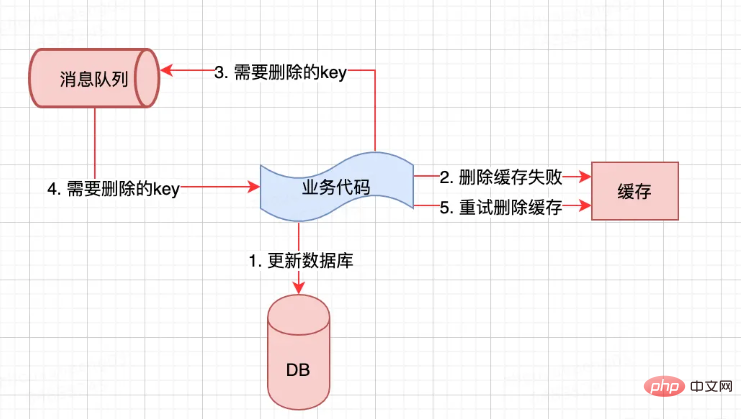
延时工具可以选择:
最普通的阻塞Thread.currentThread().sleep(1000);
Jdk调度线程池,quartz定时任务,利用jdk自带的delayQueue,netty的HashWheelTimer,Rabbitmq的延时队列,等等
实际场景
我们有个商品中心的场景,是读多写少的服务,并且写数据会发送MQ通知下游拿数据,这样就需要严格保证缓存和数据库的一致性,需要提供高可靠的系统服务能力。
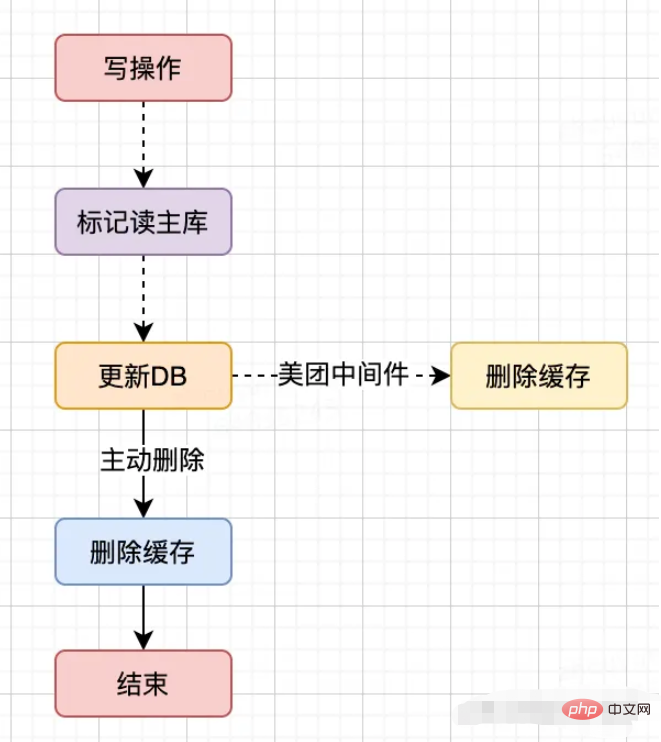
写缓存策略
缓存key设置失效时间
先DB操作,再缓存失效
写操作都标记key(美团中间件)强制走主库
接入美团中间件监听binlog(美团中间件)变化的数据在进行兜底,再删除缓存
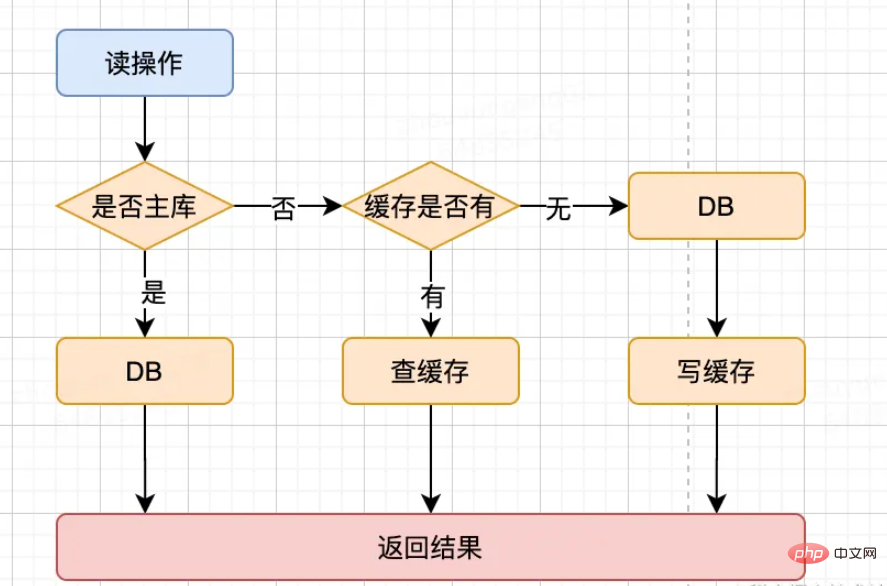
读缓存策略
先判断是否走主库
如果走主库,则使用标记(美团中间件)查主库
如果不是,则查看缓存中是否有数据
缓存中有数据,则使用缓存数据作为结果
如果没有,则查DB数据,再写数据到缓存
注意
关于缓存过期时间的问题
如果缓存设置了过期时间,那么上述的所有不一致情况都只是暂时的。
但是如果没有设置过期时间,那么不一致问题就只能等到下次更新数据时解决。
所以一定要设置缓存过期时间。
위 내용은 Java에서 캐시 일관성을 보장하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!