
유용한 정보가 가득! Python의 코루틴 구현 방법에 대한 포괄적인 소개입니다! 이해한다면 당신은 대단합니다!

- PHPz앞으로
- 2023-05-02 10:34:061164검색

파일 업로드 기능을 구현할 때와 같이 요청 처리를 완료하기 위해 여러 서비스에 액세스해야 하는 경우 먼저 Redis 캐시에 액세스하여 사용자가 로그인했는지 확인한 다음 HTTP 메시지로 본문을 받습니다. 그리고 디스크에 저장하고, 마지막으로 파일 경로와 기타 정보를 MySQL 데이터베이스에 쓰면 어떻게 될까요?
먼저 차단 API를 사용하여 동기화 코드를 작성하고 단계별로 직렬화하면 되지만, 당연히 이때 하나의 스레드는 동시에 하나의 요청만 처리할 수 있습니다. 스레드 수에는 제한이 있으므로 스레드 수 제한으로 인해 수만 개의 동시 연결을 달성할 수 없으며 과도한 스레드 전환으로 인해 CPU 시간이 소모되어 초당 처리할 수 있는 요청 수가 줄어듭니다.
따라서 높은 동시성을 달성하려면 비동기식 프레임워크를 선택하고 비차단 API를 사용하여 비즈니스 논리를 여러 콜백 함수로 중단하고 멀티플렉싱을 통해 높은 동시성을 달성할 수 있습니다. 하지만 이때 비즈니스 코드는 동시성 세부 사항에 너무 많은 주의를 기울여야 하고, 코드 로직에 오류가 발생하면 콜백 지옥에 빠지게 됩니다.
그래서 이렇게 하면 버그율이 매우 높을 뿐만 아니라 프로젝트 개발 속도도 느려지고 제품을 제때 출시하는 데 위험이 따르게 됩니다. 높은 동시성을 보장하면서 개발 효율성을 고려하려면 코루틴이 최선의 선택입니다. 비동기식 운영 메커니즘을 유지하면서 동기식으로 코드를 작성할 수 있습니다. 이는 높은 동시성을 달성할 뿐만 아니라 개발 주기를 단축하는 것이 고성능 서비스의 향후 개발 방향입니다.
여기서 동시성 측면에서 "코루틴" 방법이 "비차단 + 콜백" 방법보다 낫지 않다는 점을 지적해야 합니다. 그리고 우리가 코루틴을 선택하는 이유는 프로그래밍 모델이 For와 비슷하게 더 간단하기 때문입니다. 동기화를 사용하면 비동기식 코드를 동기식으로 작성할 수 있습니다. "논 블로킹 + 콜백" 방식은 프로그래밍 실력을 시험해 볼 수 있는 훌륭한 방법입니다. 일단 오류가 발생하면 문제 위치를 찾기 어렵고 콜백 지옥, 스택 찢어짐 등의 문제에 빠지기 쉽습니다.
따라서 높은 동시성 문제를 해결하는 기술은 멀티 프로세스 및 멀티 스레딩에서 비동기 및 코루틴에 이르기까지 끊임없이 변화하고 있으며 다양한 시나리오에 직면하여 모두 다른 방식으로 문제를 해결하고 있음을 알게 될 것입니다. 동시성이 높은 솔루션이 어떻게 발전했는지, 코루틴이 해결하는 문제는 무엇인지, 어떻게 적용해야 하는지 살펴보겠습니다.
비 차단 + 콜백 + IO 멀티플렉싱
우리는 호스트의 리소스가 제한되어 있고, CPU 한 개, 디스크 한 개, 네트워크 카드 한 개가 있다는 것을 알고 있습니다. 어떻게 동시에 수백 개의 요청을 처리할 수 있을까요? 다중 프로세스 모드는 원래 솔루션이었습니다. 커널은 CPU의 실행 시간을 여러 시간 조각(타임슬라이스)으로 나눕니다. 예를 들어 1초는 100개의 10밀리초 시간 조각으로 나눌 수 있습니다. 그런 다음 각 시간 조각은 일반적으로 여러 프로세스에 분산됩니다. 요청을 완료하려면 슬라이스를 사용하세요.
이런 방식으로, 예를 들어 미시적 관점에서 보면 CPU는 이 10밀리초 동안 하나의 프로세스만 실행할 수 있지만, 거시적 관점에서는 1초에 100개의 타임 슬라이스가 실행되므로 각 프로세스의 요청은 타임 슬라이스도 실행됩니다. 이를 통해 요청이 동시에 실행됩니다.
그러나 각 프로세스의 메모리 공간은 독립적이므로 동시성을 달성하기 위해 여러 프로세스를 사용하는 것은 두 가지 단점이 있습니다. 첫째, 커널 관리 비용이 높고, 둘째, 단순히 메모리를 통해 데이터를 동기화할 수 없다는 점입니다. 불편한. 그 결과 멀티스레드 모드가 등장했다. 멀티스레드 모드는 메모리 주소 공간을 공유해 이 두 가지 문제를 해결했다.
그러나 공유 주소 공간은 객체를 쉽게 공유할 수 있지만 문제도 발생합니다. 즉, 어떤 스레드라도 오류가 발생하면 프로세스의 모든 스레드가 함께 충돌하게 됩니다. 이것이 Nginx와 같이 안정성을 강조하는 서비스가 다중 프로세스 모드 사용을 고집하는 이유입니다.
그러나 실제로 멀티프로세스 기반이든 멀티스레딩 기반이든 높은 동시성을 달성하기 어려운 이유는 주로 다음 두 가지 이유 때문입니다.
- 먼저 단일 스레드가 너무 많은 메모리를 소비합니다. 예를 들어 64비트 Linux에서는 각 스레드의 스택에 8MB의 메모리를 할당합니다. 또한 후속 메모리 할당 성능을 향상시키기 위해 64MB의 메모리를 할당합니다. 각 스레드에 대해 사전 할당됩니다. 힙 메모리 풀(스레드 영역)입니다. 따라서 동시성을 달성하기 위해 수만 개의 스레드를 열 만큼 충분한 메모리가 없습니다.
- 두 번째로 스레드 전환을 통해 커널에서 전환 요청을 구현합니다. 타임 슬라이스가 소진될 뿐만 아니라 차단 메서드가 호출되면 커널은 CPU가 완전히 작동할 수 있도록 실행을 위해 다른 스레드로 전환합니다. 컨텍스트 전환 비용은 수십 나노초에서 수 마이크로초까지 다양합니다. 스레드가 사용 중이고 스레드 수가 많은 경우 이러한 스위치는 대부분의 CPU 컴퓨팅 성능을 소비합니다.
다음 그림은 디스크 IO를 예로 들어 멀티 스레드에서 디스크를 읽기 위한 차단 방법을 사용하여 두 스레드 간의 전환 방법을 설명합니다.
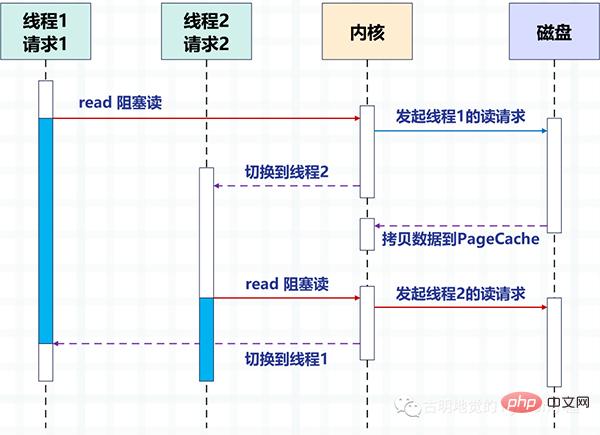
멀티스레딩을 통해 하나의 스레드가 하나의 요청을 처리하여 동시성을 달성합니다. 하지만 운영체제가 생성할 수 있는 스레드의 수는 제한되어 있는 것은 당연합니다. 스레드가 많을수록 더 많은 리소스를 점유하고, 스레드 간 전환 비용도 커널 모드와 사용자 간 전환을 수반하기 때문에 상대적으로 높기 때문입니다. 방법.
그럼 질문은 어떻게 높은 동시성을 달성할 수 있느냐는 것입니다. 대답은 "위 그림의 커널이 구현한 요청 전환 작업을 사용자 모드 코드에 맡기면 됩니다."입니다. 비동기 프로그래밍은 애플리케이션 계층 코드를 통해 요청 전환을 구현하여 전환 비용과 메모리 공간을 줄입니다.
비동기화는 Linux의 epoll과 같은 IO 다중화 메커니즘에 의존합니다. 동시에 커널 전환으로 인한 막대한 소비를 피하기 위해 차단 방법을 비차단 방식으로 변경해야 합니다. Nginx 및 Redis와 같은 고성능 서비스는 수백만 수준의 동시성을 달성하기 위해 비동기화에 의존합니다.
다음 그림은 비동기 IO의 비차단 읽기가 비동기 프레임워크와 결합된 후 요청이 전환되는 방법을 설명합니다.
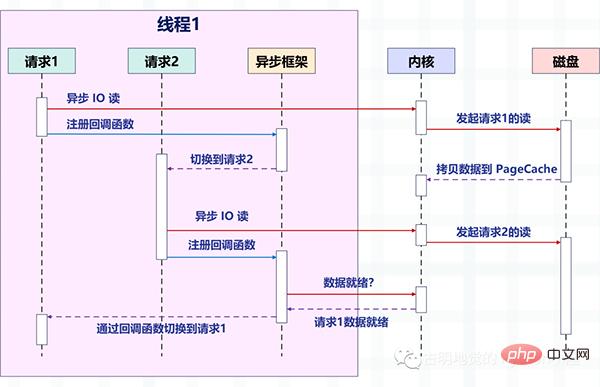
그림의 변화에 주목하세요. 이전에는 하나의 스레드가 하나의 요청을 처리했지만 이제는 하나의 스레드가 여러 요청을 처리합니다. 이것이 앞서 언급한 "비차단 + 콜백" 방식입니다. 이는 Linux의 epoll 및 BSD의 kqueue와 같은 운영 체제에서 제공하는 IO 다중화에 의존합니다.
이때 읽기 및 쓰기 작업은 이벤트와 동일하며 각 이벤트마다 해당 콜백 함수가 등록됩니다. 그러면 스레드는 차단되지 않지만(현재 읽기 및 쓰기 작업은 비차단이기 때문입니다) 그런 다음 이러한 이벤트는 epoll에 의해 균일하게 관리됩니다.
이벤트가 발생하면(읽기 및 쓰기가 가능해지면) epoll이 스레드에 이를 알리고, 스레드는 해당 이벤트에 등록된 콜백 함수를 실행합니다.
더 나은 이해를 위해 Redis를 예로 들어 비차단 IO 및 IO 다중화를 소개하겠습니다.
127.0.0.1:6379> get name "satori"
우선, get 명령을 사용하여 키에 해당하는 값을 얻을 수 있습니다. 그러면 위의 Redis 서버에 무슨 일이 일어났는가 하는 질문이 있습니다.
서버는 먼저 클라이언트의 요청을 수신해야 하며(바인딩/리스닝), 클라이언트가 도착하면 클라이언트와 연결을 설정하고(수락), 소켓에서 클라이언트의 요청을 읽고(recv), 요청을 구문 분석해야 합니다. 여기서 파싱된 요청 유형은 get이고, 키는 "name"이며, 키에 따라 해당 값을 얻은 다음 최종적으로 클라이언트에 반환합니다. 즉, 소켓에 데이터를 쓰는 것(보내기)입니다.
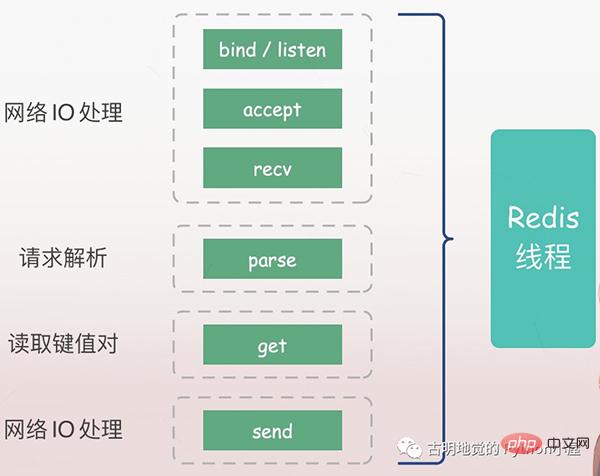
위의 모든 작업은 Redis 메인 스레드에 의해 순서대로 실행되지만 잠재적인 차단 지점, 즉 승인 및 수신이 있습니다.
IO를 차단하는 경우 Redis가 클라이언트의 연결 요청을 감지했지만 연결 설정에 실패하면 수락 기능에서 메인 스레드가 항상 차단되어 다른 클라이언트가 Redis와 연결을 설정할 수 없게 됩니다. 마찬가지로 Redis가 Recv를 통해 클라이언트로부터 데이터를 읽을 때 데이터가 도착하지 않으면 Recv 단계에서 Redis 메인 스레드가 항상 차단되므로 이로 인해 Redis의 효율성이 낮아집니다.
비차단 IO
그러나 분명히 Redis는 이러한 일이 발생하는 것을 허용하지 않을 것입니다. 위의 상황은 모두 차단 IO가 직면하게 되는 상황이고 Redis는 비차단 IO를 사용하므로 소켓을 비차단 모드로 설정한다는 의미입니다. 먼저, 소켓 모델에서 소켓() 메서드를 호출하면 활성 소켓이 반환됩니다. IP와 포트를 바인딩하기 위해 바인딩() 메서드를 호출한 다음, 활성 소켓을 수신 대기 소켓으로 변환하기 위해 Listen() 메서드를 호출합니다. 마지막으로 청취 소켓 소켓은 클라이언트 연결이 도착할 때까지 기다리기 위해 accept() 메소드를 호출합니다. 클라이언트와 연결이 설정되면 연결된 소켓을 반환한 다음 연결된 소켓을 사용하여 데이터를 수신하고 보냅니다. 클라이언트.
하지만 참고: Listen() 단계에서 활성 소켓이 청취 소켓으로 변환되며 이때 청취 소켓의 유형은 차단이라고 말했습니다. 수락을 사용할 때 청취 소켓의 차단 유형은 호출입니다. () 메서드를 사용하면 연결할 클라이언트가 없으면 항상 차단되며 이때 메인 스레드는 다른 작업을 수행할 수 없습니다. 따라서 listening() 시 비차단으로 설정할 수 있습니다. 비차단 청취 소켓이 accept()를 호출할 때 클라이언트 연결 요청이 도착하지 않으면 메인 스레드는 어리석게 기다리지 않고 직접 반환됩니다. 다른 것들.
마찬가지로 연결된 소켓을 생성할 때 해당 유형을 비차단으로 설정할 수도 있습니다. 예를 들어 다음과 같은 경우 send() / recv() 를 호출할 때 차단 유형의 연결된 소켓도 차단 상태가 되기 때문입니다. 클라이언트는 데이터를 전송하지 않으며 연결된 소켓은 항상 rev() 단계에서 차단됩니다. Non-Blocking 형태의 연결된 소켓이라면, recv()가 호출되었으나 데이터가 수신되지 않을 때, Blocking 상태에 있을 필요가 없고 직접 돌아와서 다른 일을 할 수도 있습니다.
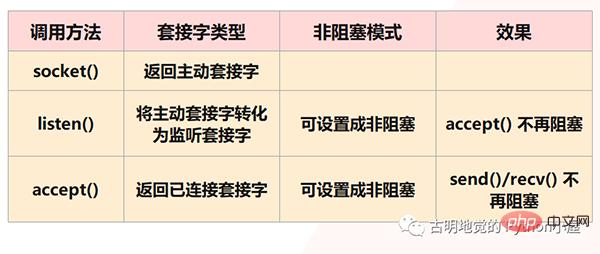
그러나 두 가지 주의할 점이 있습니다:
1) accept()가 더 이상 차단되지 않지만 Redis 메인 스레드는 클라이언트 연결이 없을 때 다른 작업을 수행할 수 있지만 클라이언트가 연결되면 Redis는 어떻게 될까요? 나중에 알았어? 따라서 청취 소켓에서 후속 연결 요청을 계속 기다리고 요청이 도착하면 Redis에 알릴 수 있는 메커니즘이 있어야 합니다.
2) send() / recv()가 더 이상 차단되지 않습니다. IO에 해당하는 읽기 및 쓰기 프로세스가 더 이상 차단되지 않습니다. 읽기 및 쓰기 메서드가 즉시 완료되고 반환됩니다. 읽고 쓸 수 있습니다. IO 작업을 수행하려는 만큼 많은 전략을 작성할 수 있으며 이는 분명히 우리의 성능 추구에 더 부합합니다. 그러나 이 역시 문제에 직면하게 됩니다. 즉, 읽기 작업을 수행할 때 데이터의 일부만 읽었고 나머지 데이터는 클라이언트에서 전송되지 않았을 수 있습니다. 그러면 이 데이터는 언제 전송됩니까? 읽을 수 있나요? 데이터를 쓰는 경우에도 마찬가지입니다. 버퍼가 가득 차고 데이터가 아직 쓰여지지 않은 경우 나머지 데이터는 언제 쓸 수 있습니까? 따라서 Redis 메인 스레드가 다른 작업을 수행하는 동안 연결된 소켓을 계속 모니터링하고, 읽고 쓸 데이터가 있으면 Redis에게 알릴 수 있는 메커니즘도 있어야 합니다.
이렇게 하면 Redis 스레드가 기본 IO 모델처럼 차단 지점에서 기다리지 않고 실제로 도착하는 클라이언트 연결 요청과 읽기 및 쓰기 가능한 데이터를 처리할 수 없게 됩니다. 위에 언급된 메커니즘은 IO 멀티플렉싱입니다.
IO 멀티플렉싱
I/O 멀티플렉싱 메커니즘은 다중 IO 스트림을 처리하는 스레드를 의미하며, 이는 우리가 자주 듣는 선택/폴링/에폴링입니다. 이 세 가지의 차이점에 대해서는 언급하지 않겠습니다. 모두 동일한 작업을 수행하지만 성능과 구현 원칙에는 차이가 있습니다. select는 모든 시스템에서 지원되는 반면 epoll은 Linux에서만 지원됩니다.
간단히 말하면 Redis가 단일 스레드만 실행할 때 이 메커니즘을 사용하면 여러 개의 수신 소켓과 연결된 소켓이 커널에 동시에 존재할 수 있습니다. 커널은 항상 이러한 소켓에 대한 연결 요청이나 데이터 요청을 모니터링합니다. 요청이 도착하면 처리를 위해 Redis 스레드로 전달되어 하나의 Redis 스레드가 여러 IO 스트림을 처리하는 효과를 얻습니다.
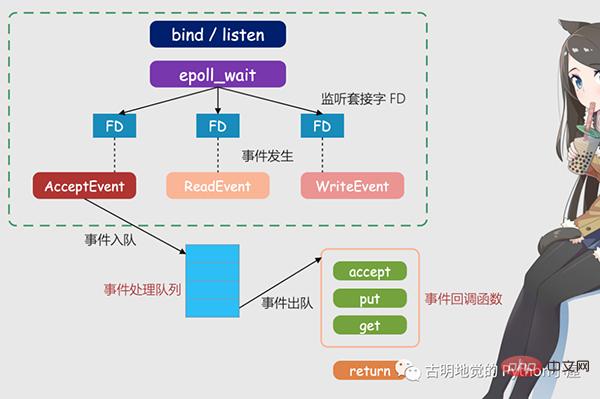
위 그림은 멀티플렉싱을 기반으로 한 Redis IO 모델입니다. 그림의 FD는 청취 소켓일 수도 있고 연결된 소켓일 수도 있습니다. Redis는 epoll 메커니즘을 사용하여 이를 수신합니다. 소켓. 이때 Redis 스레드나 메인 스레드는 특정 소켓에서 차단되지 않습니다. 즉, 특정 클라이언트 요청 처리 시 차단되지 않는다는 의미입니다. 따라서 Redis는 동시에 여러 클라이언트에 연결하고 요청을 처리할 수 있으므로 동시성이 향상됩니다.
하지만 요청이 도착할 때 Redis 스레드에 알리기 위해 epoll은 이벤트 기반 콜백 메커니즘을 제공합니다. 즉, 다양한 이벤트 발생에 대해 해당 처리 기능을 호출합니다.
그럼 콜백 메커니즘은 어떻게 작동하나요? 위 그림을 예로 들면, 먼저 epoll은 요청이 FD에 도착했음을 감지하면 해당 이벤트를 트리거합니다. 이러한 이벤트는 대기열에 들어가고 Redis 메인 스레드는 지속적으로 이벤트 대기열을 처리합니다. 이러한 방식으로 Redis는 요청이 있는지 계속 폴링할 필요가 없으므로 리소스 낭비를 피할 수 있습니다.
동시에 Redis는 이벤트 큐의 이벤트를 처리할 때 이벤트 기반 콜백을 구현하는 해당 처리 함수를 호출합니다. Redis는 이벤트 큐를 처리해왔기 때문에 적시에 클라이언트 요청에 응답할 수 있고 Redis의 응답 성능을 향상시킬 수 있습니다.
실제 연결 요청과 데이터 읽기 요청을 예로 들어 다시 설명해 보겠습니다. 연결 요청 및 데이터 읽기 요청은 각각 Accept 이벤트 및 Read 이벤트에 해당합니다. Linux 커널은 연결 요청 또는 데이터 읽기 요청을 모니터링할 때 Accept 이벤트 또는 Read 이벤트를 트리거합니다. , 그런 다음 메인 스레드에 알리고 등록된 승인 함수 또는 get 함수를 콜백합니다.
환자가 의사를 만나러 병원에 가는 것처럼, 각 환자(요청과 유사)는 의사가 실제로 진단하기 전에 선별, 측정, 등록 등을 거쳐야 합니다. 이 모든 업무를 의사가 수행한다면 업무 효율성은 매우 낮을 것입니다. 따라서 병원에서는 분류 스테이션을 설치했습니다. 분류 스테이션은 항상 이러한 사전 진단 작업(Linux 커널 청취 요청과 유사)을 처리한 다음 실제 진단을 위해 의사에게 전달합니다. (Redis의 메인 스레드와 동일) 매우 효율적일 수 있습니다.
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
为什么不推荐这种编程模式?
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
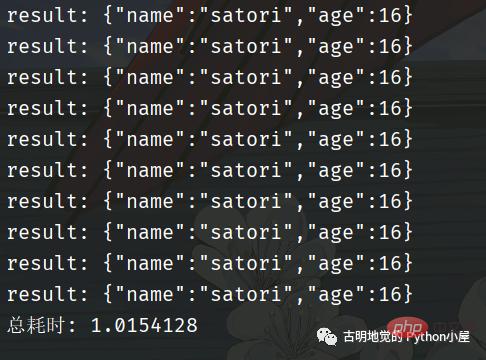
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
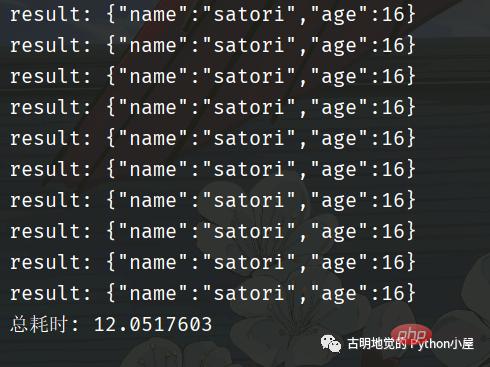
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程是如何实现高并发的?
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
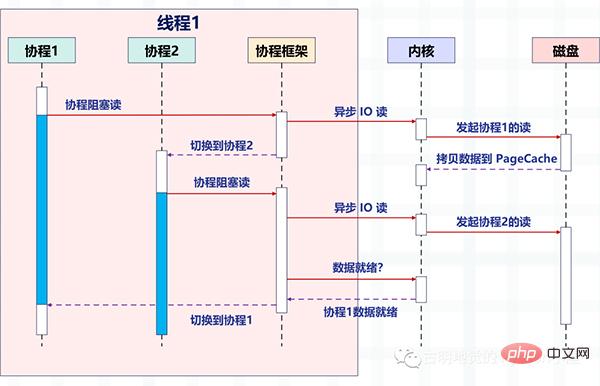
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
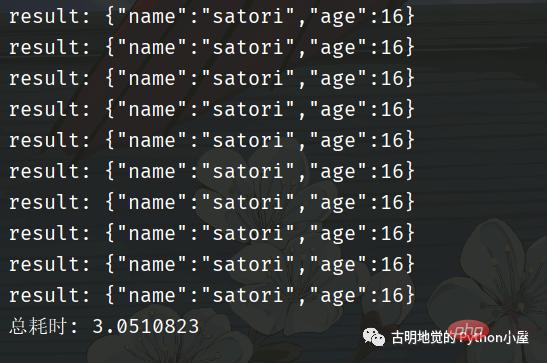
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
协程是如何切换的?
那么问题来了,协程的切换是如何完成的呢?
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
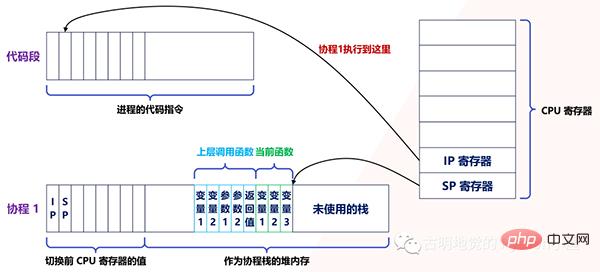
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
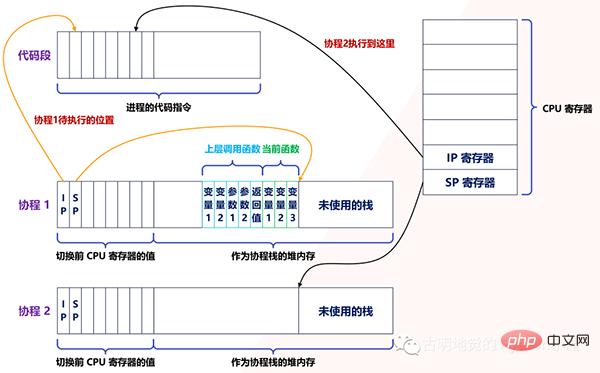
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
예를 들어 일반적인 sleep 함수는 현재 스레드를 절전 모드로 만들고 커널은 코루틴 변환 후 스레드를 깨웁니다. sleep은 현재 코루틴만 절전 모드로 만들고 코루틴 프레임워크는 지정된 후에 코루틴을 깨웁니다. time이므로 Python에서는 코루틴에 time.sleep을 쓸 수 없지만 asyncio.sleep을 써야 합니다. 또 다른 예로, 스레드 간의 뮤텍스 잠금은 세마포어를 사용하여 구현되며, 세마포어는 스레드를 절전 모드로 전환할 수도 있습니다. 뮤텍스 잠금이 코루틴으로 변환된 후 프레임워크는 각 코루틴의 실행을 조정하고 동기화합니다.
따라서 코루틴의 고성능은 전환이 사용자 모드 코드로 완료되어야 한다는 사실에 기반합니다. 이를 위해서는 코루틴 생태계가 완전하고 공통 구성 요소를 최대한 많이 포함해야 합니다.
Python을 예로 들어 보겠습니다. 사람들이 요청을 보내기 위해 비동기 def로 요청을 작성하는 것을 자주 봅니다. 요청에 대한 기본 호출은 동기적으로 차단된 소켓으로, 스레드가 차단되면 모든 코루틴이 차단되며 이는 직렬화와 동일합니다. 따라서 async def에 넣을 필요가 없습니다. 올바른 방법은 aiohttp 또는 httpx를 사용하는 것입니다. 따라서 코루틴을 사용하려면 기본 시스템 호출을 다시 캡슐화해야 합니다. 다른 방법이 없으면 이를 스레드 풀에 넣어 실행해야 합니다.
또 다른 예는 MySQL에서 공식적으로 제공하는 클라이언트 SDK입니다. 이 SDK는 네트워크 액세스를 위해 차단 소켓을 사용하므로 스레드가 잠자기 상태가 됩니다. SDK를 코루틴에서 사용하려면 먼저 비차단 소켓을 사용해야 합니다.
물론 디스크에서 비동기 IO 읽기와 같은 모든 기능을 코루틴으로 변환할 수 있는 것은 아닙니다. 비차단 기능이지만 시스템 처리량을 감소시키는 PageCache를 사용할 수 없습니다. 캐시된 IO를 사용하여 파일을 읽는 경우 PageCache가 적중되지 않으면 차단이 발생할 수 있습니다. 이때 더 높은 성능 요구 사항이 있는 경우 스레드를 코루틴과 결합하고, 잠재적으로 차단할 수 있는 작업을 스레드 풀에 넣어 실행하고, 생산자/소비자 모델을 통해 코루틴으로 작업해야 합니다.
사실 멀티 코어 시스템에서는 코루틴과 스레드도 함께 작동해야 합니다. 코루틴의 전달자는 스레드이고 스레드는 한 번에 하나의 CPU만 사용할 수 있으므로 더 많은 스레드를 열고 이러한 스레드 간에 모든 코루틴을 배포하면 CPU 리소스를 완전히 사용할 수 있습니다. Go 언어를 사용해 본 경험이 있다면 이 점을 잘 알고 있어야 합니다.
또한 코루틴이 더 많은 CPU 시간을 확보할 수 있도록 스레드 우선순위를 설정할 수도 있습니다. 예를 들어 Linux에서는 스레드 우선순위를 -20으로 설정하면 매번 더 긴 시간을 확보할 수 있습니다. . 조각. 또한 CPU 캐시는 프로그램 성능에 영향을 미치므로 CPU 캐시 실패 비율을 줄이기 위해 스레드를 CPU에 바인딩하여 코루틴이 실행될 때 CPU 캐시에 도달할 확률을 높일 수도 있습니다.
여기서는 코루틴 프레임워크가 코루틴을 예약한다고 했지만 많은 코루틴 라이브러리는 실행 생성, 일시 중지, 재개와 같은 기본적인 방법만 제공한다는 것을 알 수 있습니다. 코루틴 프레임워크가 없으며 비즈니스 코드가 필요합니다. 코루틴 자체적으로 예약됩니다. 이는 이러한 일반 코루틴 라이브러리(예: asyncio)가 서버용으로 특별히 설계되지 않았기 때문입니다. 서버에서 클라이언트 네트워크 연결을 설정하면 코루틴 생성이 구동되고 요청이 끝나면 종료될 수 있습니다.
코루틴의 실행 조건이 충족되지 않으면 멀티플렉싱 프레임워크는 이를 일시 중지하고 우선순위 정책에 따라 실행할 다른 코루틴을 선택합니다. 따라서 코루틴을 사용하여 서버 측에서 동시성이 높은 서비스를 구현하는 경우 코루틴 라이브러리를 선택할 뿐만 아니라 생태계의 IO 멀티플렉싱을 결합하는 코루틴 프레임워크(예: Tornado)를 찾아 개발 속도를 높일 수 있습니다.
한 문장으로 코루틴 요약
대체로 말하면 코루틴은 비교적 높은 수준의 가벼운 동시성 모델입니다. 하지만 좁은 의미에서 코루틴은 일시 중지 및 전환이 가능한 함수를 호출하는 것입니다. 예를 들어, async def를 사용하여 정의하는 것은 본질적으로 함수인 코루틴 함수입니다. 코루틴 함수를 호출하면 코루틴이 생성됩니다.
코루틴을 이벤트 루프에 넣으면 이벤트 루프가 실행을 구동합니다. 일단 차단되면 실행 권한이 이벤트 루프에 적극적으로 넘겨지고 이벤트 루프는 다른 코루틴을 실행하도록 유도합니다. 그래서 처음부터 끝까지 하나의 스레드만 있고 코루틴은 스레드의 구조를 참조하여 사용자 모드에서 시뮬레이션할 뿐입니다.
그래서 일반 함수가 호출되면 모든 내부 코드 로직이 모두 완료될 때까지 실행되고, 코루틴 함수가 호출되고 내부 차단이 발생하면 다른 코루틴으로 전환됩니다.
그러나 코루틴이 차단될 때 전환할 수 있으려면 중요한 전제 조건이 있습니다. 즉, 이 차단에는 time.sleep, 동기 소켓 등과 같은 시스템 호출이 포함될 수 없습니다. 이 모든 것에는 커널의 참여가 필요하며 일단 커널이 참여하면 발생하는 차단은 특정 코루틴을 차단하는 것(OS가 코루틴을 인식하지 못함)만큼 간단하지 않고 스레드를 차단하게 됩니다. 스레드가 차단되면 그 위의 모든 코루틴이 차단됩니다. 코루틴은 스레드를 캐리어로 사용하므로 실제 실행은 스레드여야 합니다.
따라서 코루틴을 사용하려면 차단된 시스템 호출을 다시 캡슐화해야 합니다.
@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
小结
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
따라서 코루틴을 사용할 때는 스레드 풀을 사용하는 것이 가장 좋습니다. 일부 차단이 커널을 통과해야 하고 코루틴화할 수 없는 경우 이를 스레드 풀에 넣고 스레드 수준에서 전환을 완료하세요. 여러 스레드를 시작하면 리소스가 소모되고 스레드 전환으로 인해 오버헤드가 발생하지만 커널 차단을 통해 전환하려면 이는 불가피하며 CPU를 너무 많이 사용하는 작업의 경우 스레드에만 희망을 둘 수 있습니다. 집중적이라면 스레드 풀에 던지는 것을 고려할 수도 있습니다. 어떤 사람들은 다중 코어를 사용할 수 있다면 스레드 풀에 던지는 것이 합리적이라고 궁금해할 수 있지만 Python의 다중 스레딩은 다중 코어를 사용할 수 없습니다. 왜 이렇게 합니까? 이유는 간단합니다. 스레드가 하나만 있는 경우 이러한 CPU 집약적 작업은 CPU 리소스를 오랫동안 차지하게 되어 다른 작업이 실행되지 않게 됩니다. 멀티스레딩을 켜면 아직 코어가 1개밖에 없는데도 GIL이 스레드 전환을 일으키기 때문에 '초왕은 허리가 가늘고 하렘은 굶어죽는다' 같은 상황은 발생하지 않는다. CPU가 균등하게 분산되어 모든 작업을 실행할 수 있습니다.
위 내용은 유용한 정보가 가득! Python의 코루틴 구현 방법에 대한 포괄적인 소개입니다! 이해한다면 당신은 대단합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!