
Pandas와 PySpark가 힘을 합쳐 기능성과 속도를 모두 달성했습니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-01 21:19:052007검색
데이터 처리를 위해 Python을 사용하는 데이터 과학자나 데이터 실무자는 데이터 과학 패키지 pandas가 낯설지 않으며, 윤두준처럼 pandas를 많이 사용하는 사람들도 있습니다. 프로젝트 초기에 작성된 첫 번째 코드 줄은 대부분 다음과 같습니다. 팬더를 pd로 가져옵니다. 팬더는 데이터 처리를 위한 yyds라고 할 수 있습니다! 그리고 단점도 매우 분명합니다. Pandas는 단일 시스템에서만 처리할 수 있으며 데이터 양에 따라 선형적으로 확장할 수 없습니다. 예를 들어, pandas가 머신의 사용 가능한 메모리보다 큰 데이터 세트를 읽으려고 시도하면 메모리 부족으로 인해 실패합니다.
또한 Pandas는 대용량 데이터를 처리하는 데 매우 느립니다. 데이터 처리 속도를 최적화하고 향상시키는 Dask 또는 Vaex와 같은 다른 라이브러리가 있지만 빅 데이터 처리 신 프레임워크 Spark 앞에선 식은 죽 먹기입니다.
다행히도 새로운 Spark 3.2 버전에는 대부분의 pandas 기능을 PySpark에 통합하는 새로운 Pandas API가 등장했습니다. Spark의 Pandas API는 백그라운드에서 Spark를 사용하기 때문에 pandas 인터페이스를 사용하면 Spark를 사용할 수 있습니다. 매우 강력하고 편리하다고 할 수 있는 강력한 협력 효과를 얻을 수 있습니다.
모든 것은 Spark + AI Summit 2019에서 시작되었습니다. Koalas는 Spark 위에 Pandas를 사용하는 오픈 소스 프로젝트입니다. 처음에는 Pandas 기능의 일부만 다루었지만 점차 크기가 커졌습니다. 이제 새로운 Spark 3.2 버전에서는 Koalas가 PySpark에 병합되었습니다.
Spark는 이제 Pandas API를 통합하므로 Spark에서 Pandas를 실행할 수 있습니다. 코드 한 줄만 변경하면 됩니다.
import pyspark.pandas as ps
이를 통해 많은 이점을 얻을 수 있습니다.
- Python 및 Pandas 사용에는 익숙하지만 Spark에는 익숙하지 않은 경우 복잡한 학습 과정을 생략하고 PySpark를 사용할 수 있습니다. 즉시.
- 하나의 코드베이스는 소규모 및 대규모 데이터, 단일 및 분산 시스템 등 모든 것에 사용할 수 있습니다.
- Spark 분산 프레임워크에서 Pandas 코드를 더 빠르게 실행할 수 있습니다.
마지막 포인트가 특히 주목할 만합니다.
한편으로는 분산 컴퓨팅을 Pandas의 코드에 적용할 수 있습니다. 그리고 Spark 엔진을 사용하면 단일 머신에서도 코드가 더 빨라집니다! 아래 그래프는 96개의 vCPU와 384GiB의 메모리를 갖춘 머신에서 Spark를 실행하는 것과 Pandas만 호출하여 130GB CSV 데이터 세트를 분석하는 것의 성능 비교를 보여줍니다.
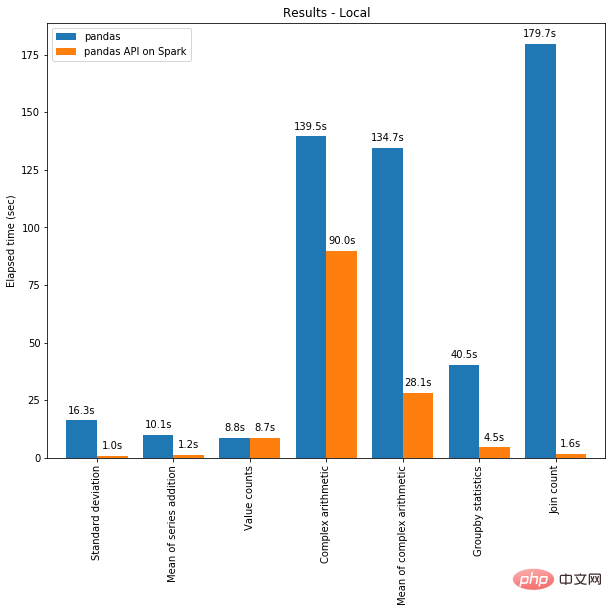
멀티 스레딩과 Spark SQL Catalyst Optimizer는 모두 성능 최적화에 도움이 됩니다. 예를 들어, 조인 카운트 작업은 전체 단계 코드 생성 시 4배 더 빠릅니다. 즉, 코드 생성 시 5.9초, 코드 생성 시 1.6초입니다.
Spark는 체인 작업에서 특히 중요한 이점을 가지고 있습니다. Catalyst 쿼리 최적화 프로그램은 필터를 인식하여 데이터를 지능적으로 필터링하고 디스크 기반 조인을 적용할 수 있는 반면, Pandas는 각 단계에서 모든 데이터를 메모리에 로드하는 것을 선호합니다.
Spark에서 Pandas API를 사용하여 코드를 작성하는 방법을 시험해보고 싶으신가요? 지금 시작해 보세요!
Pandas / Pandas-on-Spark / Spark 간 전환
가장 먼저 알아야 할 것은 우리가 정확히 무엇을 사용하고 있는지입니다. Pandas를 사용하는 경우 pandas.core.frame.DataFrame 클래스를 사용하세요. Spark에서 pandas API를 사용하는 경우 pyspark.pandas.frame.DataFrame을 사용하세요. 둘은 유사하지만 동일하지는 않습니다. 주요 차이점은 전자는 단일 시스템에 있고 후자는 분산되어 있다는 것입니다.
Pandas-on-Spark를 사용하여 데이터 프레임을 생성하고 이를 Pandas로 변환하거나 그 반대로 변환할 수 있습니다.
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
여러 시스템을 사용하는 경우 Pandas-on-Spark 데이터 프레임을 Pandas 데이터 프레임으로 변환하면 데이터 프레임이 여러 머신에서 한 머신으로 또는 그 반대로 전송됩니다(PySpark 가이드 [1] 참조).
Pandas-on-Spark 데이터프레임을 Spark 데이터프레임으로 또는 그 반대로 변환할 수도 있습니다.
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
데이터 유형은 어떻게 변경되나요?
Pandas-on-Spark와 Pandas를 사용할 때 데이터 유형은 기본적으로 동일합니다. Pandas-on-Spark DataFrame을 Spark DataFrame으로 변환하면 데이터 유형이 자동으로 적절한 유형으로 변환됩니다(PySpark 가이드 [2] 참조)
다음 예는 변환 시 PySpark DataFrame에서 데이터 유형이 변환되는 방법을 보여줍니다. pandas-on-Spark DataFrame으로 변환합니다.
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
Pandas-on-Spark 대 Spark 함수
Spark의 DataFrame 및 Pandas-on-Spark에서 가장 일반적으로 사용되는 기능입니다. Pandas-on-Spark와 Pandas의 유일한 구문 차이점은 import pyspark.pandas as ps 라인입니다.
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
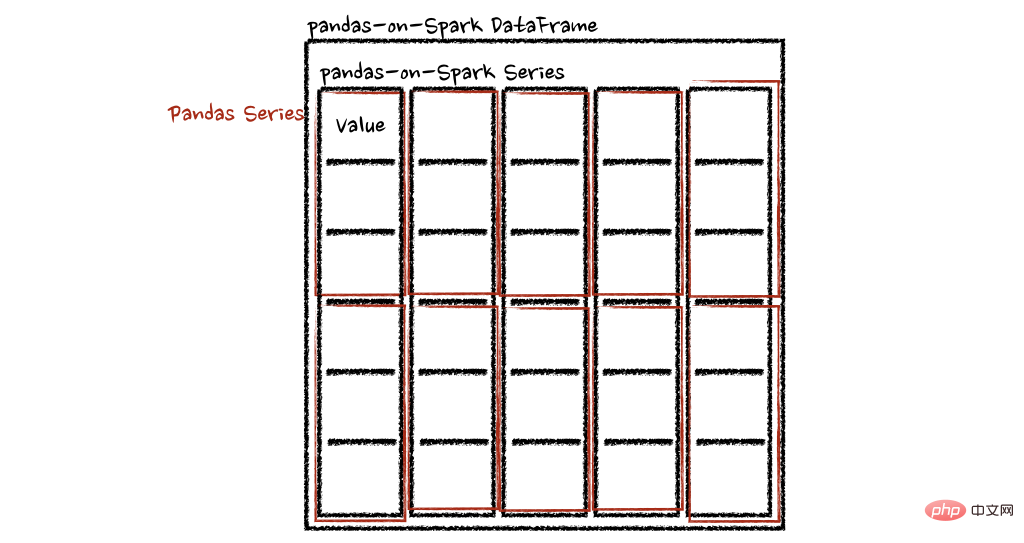
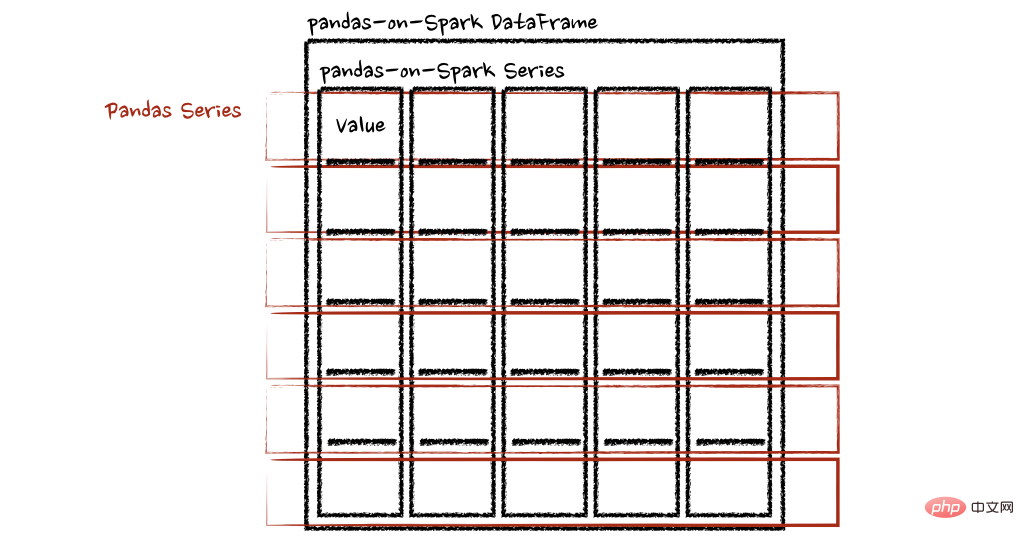
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
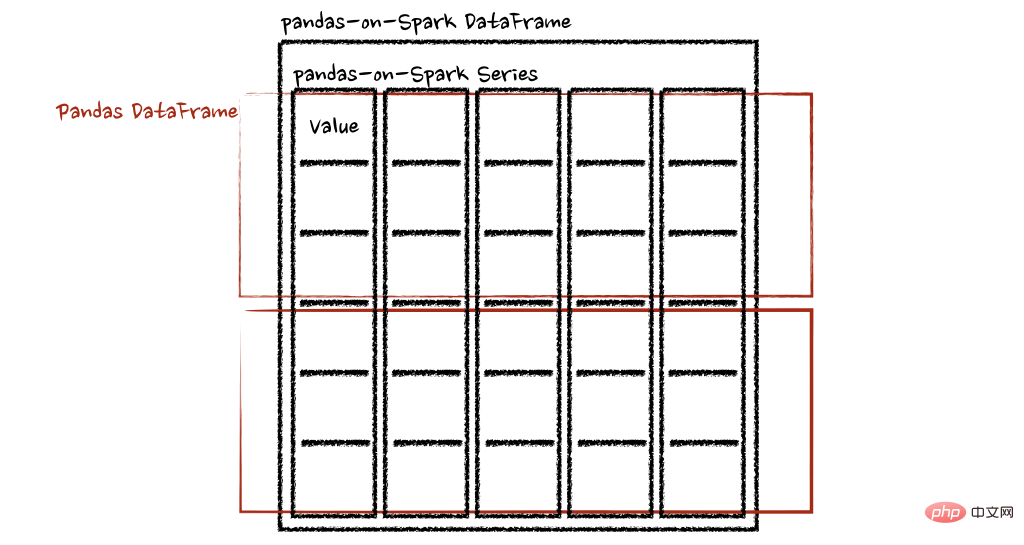
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
위 내용은 Pandas와 PySpark가 힘을 합쳐 기능성과 속도를 모두 달성했습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!