
사진 + 오디오가 단 몇 초 만에 비디오로 변환됩니다! Xi'an Jiaotong University의 오픈 소스 SadTalker: 초자연적인 머리와 입술 움직임, 중국어와 영어 이중 언어 가능, 노래도 가능

- 王林앞으로
- 2023-05-01 15:16:062013검색
디지털 피플이라는 개념의 대중화와 세대 기술의 지속적인 발전으로 인해 오디오 입력에 따라 사진 속 캐릭터를 움직이는 것은 더 이상 문제가 되지 않습니다.
그러나 "얼굴 이미지와 음성 오디오를 통해 말하는 캐릭터 아바타 영상을 생성하는 것"에는 부자연스러운 머리 움직임, 왜곡된 표정, 영상과 사진의 과도한 얼굴 차이 등 여전히 많은 문제점이 있습니다. 및 기타 문제.
최근 시안교통대학교 연구진 등이 3차원 모션장에서 학습하여 오디오로부터 3DMM의 3차원 모션 계수(머리 포즈, 표정)를 생성하고, 머리 움직임을 생성하는 새로운 3D 얼굴 렌더러.

논문 링크: https://arxiv.org/pdf/2211.12194.pdf
프로젝트 홈페이지: https://sadtalker.github.io/
오디오는영어, 중국어, 노래로 제공되며, 영상 속 캐릭터는 깜빡이는 속도도 제어할 수 있습니다!
실제적인 모션 계수를 배우기 위해 연구자들은 오디오와 다양한 유형의 모션 계수 간의 연결을 명시적으로 별도로 모델링합니다. 계수와 3D 렌더링된 얼굴을 추출하여 오디오에서 정확한 얼굴을 학습합니다. 조건부 VAE를 통해 PoseVAE를 설계하여 다양한 스타일의 머리를 합성합니다. 동정.마지막으로 생성된 3차원 모션 계수를 얼굴 렌더링의 비지도 3차원 키포인트 공간에 매핑하고 최종 영상을 합성합니다.
마지막으로 이 방법이 모션 동기화 및 비디오 품질 측면에서 최첨단 성능을 달성한다는 것이 실험적으로 입증되었습니다.
stable-diffusion-webui 플러그인도 출시되었습니다!
사진 + 오디오 = 비디오
디지털 휴먼 창작, 화상 회의 등 다양한 분야에는 "음성 오디오를 사용하여 정지 사진에 애니메이션을 적용하는" 기술이 필요하지만 현재 이는 여전히 매우 어려운 작업입니다.입술 움직임과 말의 관계가 가장 강력하기 때문에 이전 작업에서는 주로 "입술 움직임"을 생성하는 데 중점을 두었습니다. 다른 작업에서도 다른 관련 움직임(예: 머리 자세)의 얼굴 동영상을 생성하려고 합니다. 결과 비디오의 품질은 여전히 매우 부자연스럽고 선호하는 포즈, 흐림, 신원 수정 및 얼굴 왜곡으로 인해 제한됩니다.
또 다른 인기 있는 방법은 대화형 얼굴 애니메이션에서 특정 동작 범주에 주로 초점을 맞춘 잠재 기반 얼굴 애니메이션입니다. 3D 얼굴 모델에는 높은 해상도가 포함되어 있지만 고품질 비디오를 합성하는 것도 어렵습니다. 결합된 표현을 사용하면 얼굴의 다양한 위치의 동작 궤적을 독립적으로 학습할 수 있지만 여전히 부정확한 표현과 부자연스러운 동작 시퀀스가 생성됩니다.
위의 관찰을 바탕으로 연구원들은 암시적 3차원 계수 변조를 통해 양식화된 오디오 기반 비디오 생성 시스템인 SadTalker(Stylized Audio-Driven Talking-head)를 제안했습니다.
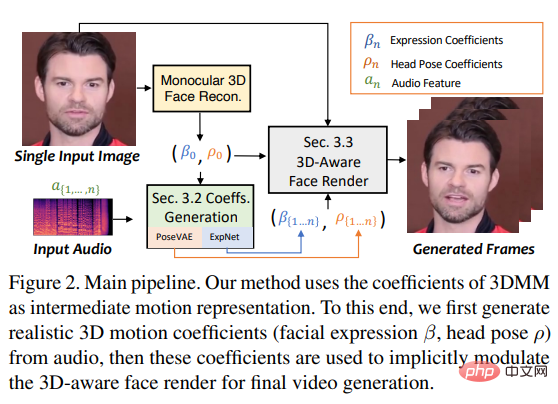
마지막으로 Face-vid2vid에서 영감을 받은 3D 인식 얼굴 렌더링을 통해 소스 이미지를 구동합니다.
3D 얼굴 실제 영상은 3차원 환경에서 촬영되기 때문에 생성된 영상의 진정성을 높이기 위해서는 3차원 정보가 중요하지만, 이전 작품에서는 평면만으로는 얻기 어렵기 때문에 3차원 공간을 거의 고려하지 않았습니다. image 원래의 3차원은 희박하고 고품질의 얼굴 렌더러는 디자인하기 어렵습니다. 최근 단일 이미지 심도 3D 재구성 방법에서 영감을 받아 연구원들은 예측된 3D 변형 모델(3DMM)의 공간을 중간 표현으로 사용합니다. 3DMM에서 3D 얼굴 모양 S는 다음과 같이 분리될 수 있습니다. 여기서 S는 3D 얼굴의 평균 모양이고 Uid와 Uexp는 LSFM 변형 가능 모델의 정체성과 표현의 정규식입니다. , 계수 α(80차원)와 β(64차원)는 자세의 차이를 유지하기 위해 각각 캐릭터의 정체성과 표현을 설명하고, 계수 r과 t는 정체성 독립적을 달성하기 위해 각각 머리 회전과 이동을 나타냅니다. 계수 생성, 이동만 매개변수는 {β, r, t}로 모델링됩니다. 즉, 구동 오디오와 별도로 머리 포즈 ρ = [r, t]와 표현 계수 β를 학습한 후, 최종 영상 합성을 위해 이러한 모션 계수를 사용하여 얼굴 렌더링을 암묵적으로 변조합니다. 오디오를 통해 희소 모션 생성 3차원 모션 계수에는 머리 포즈와 표현이 포함됩니다. 여기서 머리 포즈는 전역 모션인 반면 표현은 상대적으로 지역적이므로 모든 계수를 완전히 학습하면 네트워크에 많은 문제를 가져온다. 머리 자세는 오디오와 관련성이 상대적으로 약한 반면, 입술 움직임은 오디오와 관련성이 높기 때문에 불확실성이 크다. 그래서 SadTalker는 다음과 같은 PoseVAE와 ExpNet을 사용하여 각각 머리 자세와 표정의 움직임을 생성합니다. ExpNet 두 가지 이유로 "오디오에서 정확한 표현 계수를 생성"할 수 있는 일반 모델을 학습하는 것은 매우 어렵습니다. 1) Audio-to -expression)은 하나가 아닙니다. 다양한 문자에 대한 일대일 매핑 작업 2) 표현 계수에는 예측의 정확성에 영향을 미치는 오디오 관련 작업이 있습니다. ExpNet의 디자인 목표는 캐릭터 정체성 문제에 대한 이러한 불확실성을 줄이는 것입니다. 연구원들은 첫 번째 프레임의 표현 계수를 통해 표현 동작을 특정 캐릭터에 연결했습니다. 자연스러운 대화에서 다른 얼굴 구성 요소의 모션 가중치를 줄이기 위해 Wav2Lip의 사전 훈련된 네트워크와 심층 3D 재구성을 통해 입술 모션 계수(입술 모션만 해당)만 계수 대상으로 사용됩니다. 기타 미묘한 얼굴 움직임(예: 눈 깜박임)의 경우 렌더링된 이미지의 추가적인 랜드마크 손실로 인해 발생할 수 있습니다. PoseVAE 연구원들은 대화 비디오에서 현실적이고 신원을 인식하는 양식화된 머리 움직임을 학습하기 위해 VAE 기반 모델을 설계했습니다. 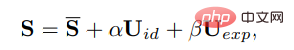
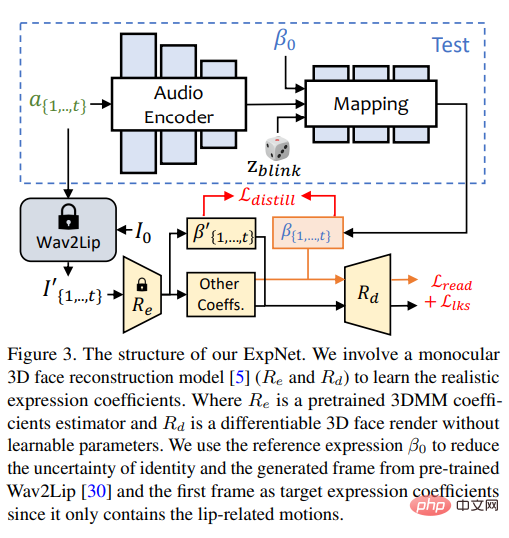
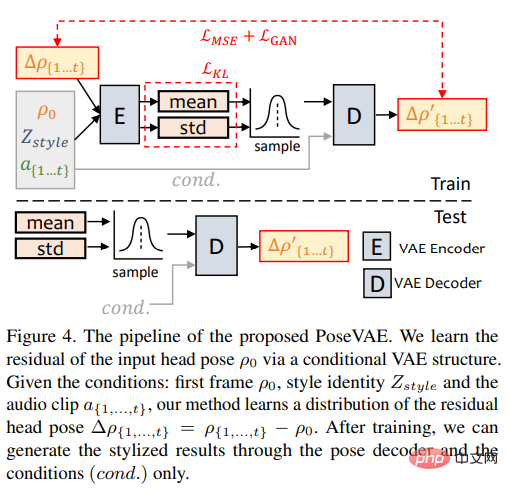
훈련에서 포즈 VAE는 인코더-디코더 기반 구조를 사용하여 고정 n 프레임에서 훈련됩니다. 여기서 인코더와 디코더는 모두 2계층 MLP이고 입력에는 연속적인 머리 포즈가 포함됩니다. 프레임 t는 디코더에서 가우스 분포에 포함되며, 네트워크는 샘플링 분포에서 프레임 t의 포즈를 생성하는 방법을 학습합니다.
PoseVAE는 포즈를 직접 생성하지 않지만 첫 번째 프레임의 조건부 포즈의 잔차를 학습합니다. 이를 통해 첫 번째 프레임의 조건에서 더 길고 안정적이며 긴 포즈를 생성할 수 있습니다. 더 지속적인 머리 움직임.
CVAE에 따르면 해당 오디오 기능과 스타일 식별자도 리듬 인식 및 아이덴티티 스타일의 조건으로 PoseVAE에 추가됩니다.
모델은 KL 발산을 사용하여 생성된 모션의 분포를 측정합니다. 평균 제곱 손실과 적대적 손실을 사용하여 생성 품질을 보장합니다.
3D 인식 얼굴 렌더링
실제적인 3D 모션 계수를 생성한 후 연구원들은 신중하게 설계된 3D 이미지 애니메이터를 통해 최종 비디오를 렌더링했습니다.
최근 제안된 이미지 애니메이션 방법인 face-vid2vid는 단일 이미지로부터 3D 정보를 암묵적으로 학습할 수 있지만, 이 방법은 동작 구동 신호로 실제 비디오가 필요한 반면, 본 논문에서 제안하는 얼굴 렌더링은 3DMM 계수에 의해 구동될 수 있습니다.
연구원들은 명시적인 3DMM 모션 계수(머리 자세 및 표현)와 암시적인 비지도 3D 키포인트 간의 관계를 학습하기 위해 mappingNet을 제안합니다.
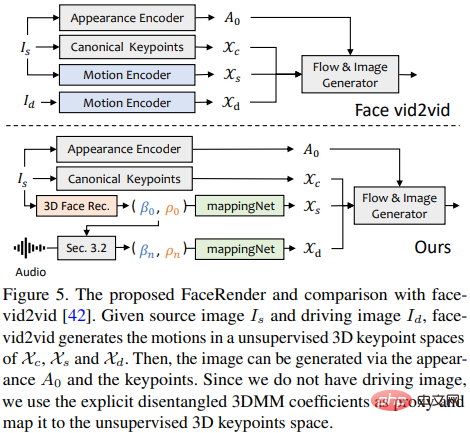
mappingNet은 여러 개의 1차원 컨볼루션 레이어를 통해 구축되었으며 PIRenderer처럼 스무딩을 위해 시간 창의 시간 계수를 사용합니다. 차이점은 연구원들이 PIRenderer의 얼굴 정렬 동작 계수가 큰 영향을 미친다는 것을 발견했다는 것입니다. 오디오 기반 비디오는 자연스러운 동작을 생성하므로 mappingNet은 표현 계수와 머리 자세만 사용합니다.
교육 단계는 두 단계로 구성됩니다. 먼저 원본 논문에 따라 Face-vid2vid를 자체 감독 방식으로 교육한 다음, 외관 인코더, 표준 키포인트 추정기 및 이미지 생성기의 모든 매개변수를 동결한 후 재구성된 방식 MappingNet은 미세 조정을 위해 실제 영상의 3DMM 계수에 대해 학습됩니다.
비지도 키포인트 영역의 지도 교육에 L1 손실을 사용하고 원래 구현에 따라 최종 생성된 비디오를 제공합니다.
실험 결과
이 방법의 우수성을 입증하기 위해 연구원들은 FID(Frechet Inception Distance) 및 CPBD(Cumulative Probability BlurDetection) 지표를 선택하여 이미지 품질을 평가했으며, FID는 주로 이미지 품질을 평가합니다. 생성된 프레임의 신뢰성, CPBD는 생성된 프레임의 선명도를 평가합니다.
신원 보존 정도를 평가하기 위해 ArcFace를 사용하여 이미지의 신원 임베딩을 추출한 후 원본 이미지와 생성된 프레임 간의 신원 임베딩의 코사인 유사성(CSIM)을 계산합니다.
입술 동기화와 입 모양을 평가하기 위해 연구원들은 거리 점수(LSE-D)와 신뢰도 점수(LSE-C)를 포함하여 Wav2Lip의 입 모양에 대한 인식 차이를 평가했습니다.
머리 모션 평가에서는 Hopenet에서 생성된 프레임에서 추출한 머리 모션 특징 임베딩의 표준 편차를 사용하여 생성된 머리 모션의 다양성을 계산하고 Beat Align Score를 계산하여 오디오와 생성된 머리를 평가합니다. 움직임의 일관성.
비교 방법에서는 MakeItTalk, Audio2Head 및 오디오 표현 생성 방법(Wav2Lip, PC-AVS)을 포함하여 가장 진보된 여러 가지 말하기 아바타 생성 방법이 선택되었으며 공개 체크포인트 가중치를 사용하여 평가되었습니다.
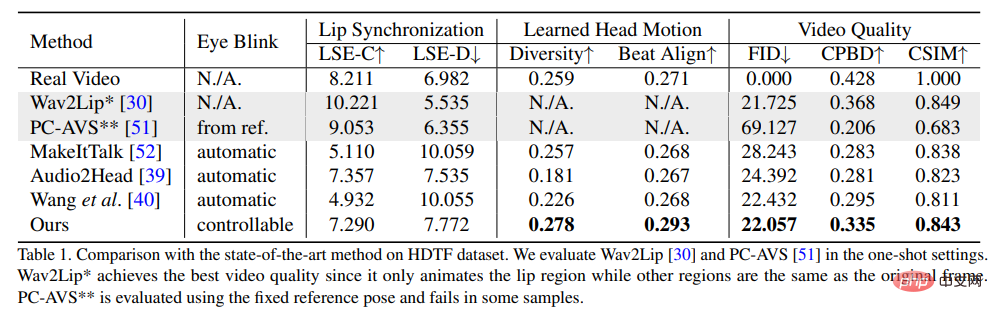
논문에서 제안한 방법이 전반적인 영상 품질과 머리 자세의 다양성을 보여줄 수 있으며, 립싱크 지표 측면에서도 다른 방법보다 좋은 성능을 보인다는 것을 실험 결과에서 확인할 수 있습니다. 완전히 말하는 머리 생성 방법에 대한 성능입니다.
연구원들은 이러한 립싱크 지표가 오디오에 너무 민감하여 부자연스러운 입술 움직임이 더 좋은 점수를 얻을 수 있다고 생각하지만, 기사에서 제안한 방법은 실제 비디오와 비슷한 점수를 얻었으며 또한 이 방법의 장점은 다음과 같습니다. 표시됩니다.

다양한 방법으로 생성된 시각적 결과에서 볼 수 있듯이 이 방법의 시각적 품질은 원본 대상 비디오와 매우 유사하며 예상되는 다양한 머리 포즈와도 매우 유사합니다.
다른 방법과 비교하여 Wav2Lip은 흐릿한 반쪽 얼굴을 생성합니다. PC-AVS 및 Audio2Head는 소스 이미지의 정체성을 유지하는 데 어려움이 있습니다. MakeItTalk 및 Audio2Head는 2D 왜곡으로 인해 흐릿한 얼굴을 생성할 수 있습니다. 얼굴 영상.
위 내용은 사진 + 오디오가 단 몇 초 만에 비디오로 변환됩니다! Xi'an Jiaotong University의 오픈 소스 SadTalker: 초자연적인 머리와 입술 움직임, 중국어와 영어 이중 언어 가능, 노래도 가능의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!