
Python을 사용하여 전국 대학의 분포를 표시하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-01 10:16:121179검색
데이터 획득
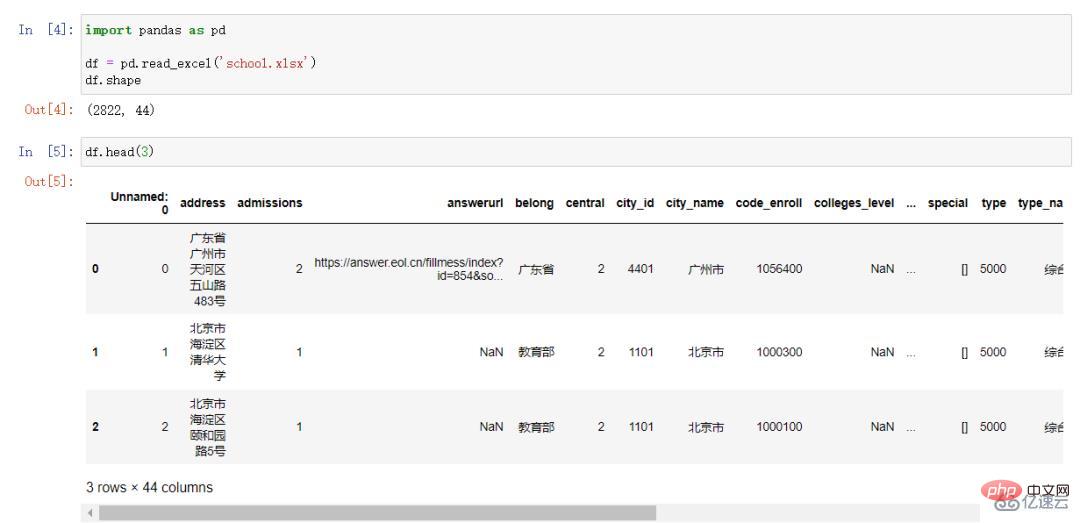
대학의 분포를 보여주기 위해서는 먼저 전국 대학의 위치 데이터를 획득해야 합니다. 이 글의 데이터는 Palm 대학 입시 네트워크
에서 가져온 것입니다. 이 글이 작성된 시점인 2022년 6월 기준 총 2,822개의 대학 정보를 얻었습니다. 데이터를 확인한 후 몇 가지 null 값을 제외하고 전체 데이터는 매우 완전하며 사용에 영향을 미치지 않습니다. 데이터에는 총 44개의 필드가 있습니다. 이 기사에서는 일부 필드만 사용하며 처리할 필요가 없으며 사용 시 필요할 때 얻을 수 있습니다.
데이터 수집 방법 소개(기본 크롤러 지식):
1 Palm College 입학 시험 네트워크에 등록하고 로그인합니다. 에서 모든 학교를 선택하세요.
2 F12 키를 누르고 네트워크 > Fetch/XHR을 클릭한 다음 페이지에서 접근한 API 등의 정보를 표시합니다.
3. 비교를 위해 페이지를 넘길 때마다 API를 복사하면 페이지와 signsafe라는 두 가지 매개변수가 변경되는 것으로 나타났습니다. Page는 현재 액세스한 페이지 수입니다. 되돌릴 수는 없지만 이전 값을 저장하고 나중에 임의로 사용할 수 있습니다. 이 정보를 이용하여 방문한 페이지 수와 signsafe 값을 지속적으로 변경함으로써 모든 학교 데이터를 얻을 수 있습니다.
응답의 numFound 매개변수 값은 총 학교 수입니다. 각 페이지에 표시된 학교 수로 나누어 페이지의 총 페이지 수를 확인하여 방문 빈도를 결정합니다.
4. 웹사이트를 이용하려면 로그인이 필요하기 때문에 접속 시 Request Method(이번에는 POST를 사용함), User-Agent 등 헤더를 얻어야 합니다.
5 위 정보를 사용하여 모든 페이지의 URL을 루프아웃하고 요청을 사용하여 모든 대학의 데이터를 가져온 다음 Pandas를 사용하여 Excel에 데이터를 작성합니다.
주의 사항: 데이터를 얻을 때 웹 사이트의 관련 설명을 준수해야 합니다. 크롤러 코드에 대한 특정 시간 간격을 설정하십시오. 액세스가 가장 많은 기간에는 크롤러 코드를 실행하지 마십시오.
위도 및 경도 획득
Palm 대학 입시 네트워크는 대학 입시 자원 봉사를 위한 웹사이트입니다. 얻은 데이터는 44개 필드이지만 해당 학교의 위도 및 경도는 포함되어 있지 않습니다. 지도에 대학의 위치를 더 잘 표시하려면 학교 주소를 기준으로 해당 경도와 위도를 얻어야 합니다.
이 기사는 Baidu 지도 개방형 플랫폼을 사용합니다: https://lbsyun.baidu.com/apiconsole/center#/home Baidu 지도의 개방형 인터페이스를 사용하여 지리적 위치의 경도와 위도를 얻을 수 있습니다.
단계는 다음과 같습니다.
1. Baidu 계정에 등록하고 로그인합니다. 이 계정은 전체 Baidu 생태계에 대한 공통 계정이 될 수 있습니다(예: 네트워크 디스크, Wenku 등의 계정이 일반적입니다).
2. Baidu Map Open Platform에 로그인하고 을 클릭한 후 에서 를 클릭하세요. 애플리케이션 이름을 사용자 정의하고 기타 정보를 안내에 따라 입력하고 실명 인증을 거쳐 개인 개발자가 됩니다.
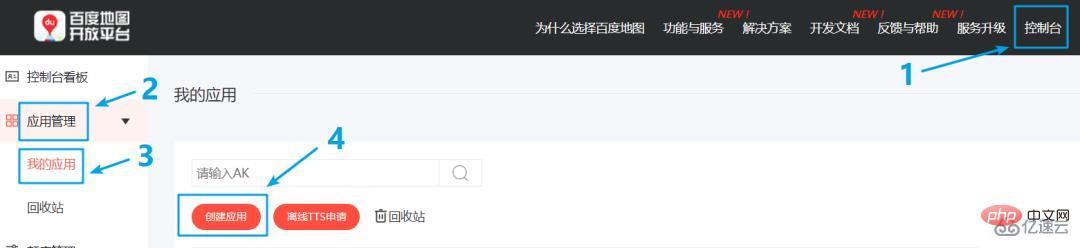
3. 애플리케이션을 생성한 후, 이 AK 값을 사용하여 Baidu의 API를 호출할 수 있습니다.
import requests
def baidu_api(addr):
url = "http://api.map.baidu.com/geocoding/v3/?"
params = {
"address": addr,
"output": "json",
"ak": "复制你创建的应用AK到此"
}
req = requests.get(url, params)
res = req.json()
if len(res["result"]) > 0:
loc = res["result"]["location"]
return loc
else:
print("获取{}经纬度失败".format(addr))
return {'lng': '', 'lat': ''}4. Baidu Map API를 성공적으로 호출한 후 모든 대학의 위치를 읽고 위 함수를 순차적으로 호출하여 모든 대학의 경도와 위도를 가져와 Excel에 다시 작성합니다.
import pandas as pd import numpy as np def get_lng_lat(): df = pd.read_excel('school.xlsx') lng_lat = [] for row_index, row_data in df.iterrows(): addr = row_data['address'] if addr is np.nan: addr = row_data['city_name'] + row_data['county_name'] # print(addr) loc = baidu_api(addr.split(',')[0]) lng_lat.append(loc) df['经纬度'] = lng_lat df['经度'] = df['经纬度'].apply(lambda x: x['lng']) df['纬度'] = df['经纬度'].apply(lambda x: x['lat']) df.to_excel('school_lng_lat.xlsx')
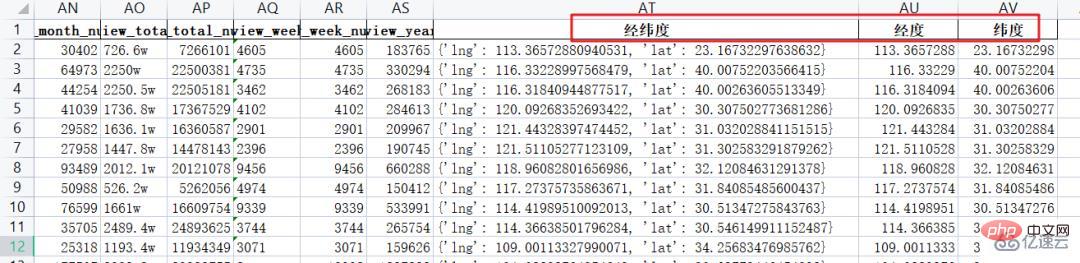
최종 데이터 결과는 아래와 같습니다.
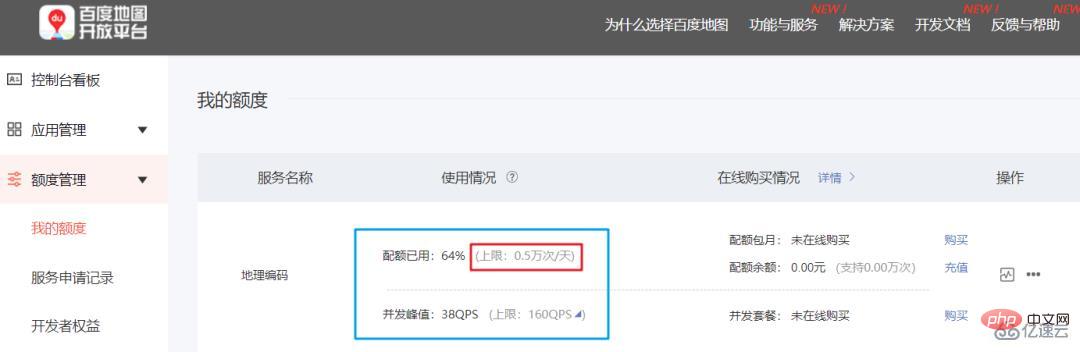
개인 개발자는 일일 할당량 제한이 있으므로 코드 디버깅 시 모든 데이터를 사용하지 마십시오. 먼저 데모를 먼저 실행해 보세요. 그렇지 않으면 하루 또는 구매 금액을 기다려야 합니다.
대학 위치 표시
데이터가 준비되었으니 지도에 표시해 보겠습니다.
이 기사에서는 Baidu의 오픈 소스 데이터 시각화 도구인 Echarts를 사용합니다. Echarts는 사용하기 매우 편리한 Python 언어용 pyecharts 라이브러리를 제공합니다.
설치 명령:
pip install pyecharts
1. 대학 위치 표시
from pyecharts.charts import Geo from pyecharts import options as opts from pyecharts.globals import GeoType import pandas as pd def multi_location_mark(): """批量标注点""" geo = Geo(init_opts=opts.InitOpts(bg_color='black', width='1600px', height='900px')) df = pd.read_excel('school_lng_lat.xlsx') for row_index, row_data in df.iterrows(): geo.add_coordinate(row_data['name'], row_data['经度'], row_data['纬度']) data_pair = [(name, 2) for name in df['name']] geo.add_schema( maptype='china', is_roam=True, itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#408080') ).add( '', data_pair=data_pair, type_=GeoType.SCATTER, symbol='pin', symbol_size=16, color='#CC3300' ).set_series_opts( label_opts=opts.LabelOpts(is_show=False) ).set_global_opts( title_opts=opts.TitleOpts(title='全国高校位置标注图', pos_left='650', pos_top='20', title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16)) ).render('high_school_mark.html')
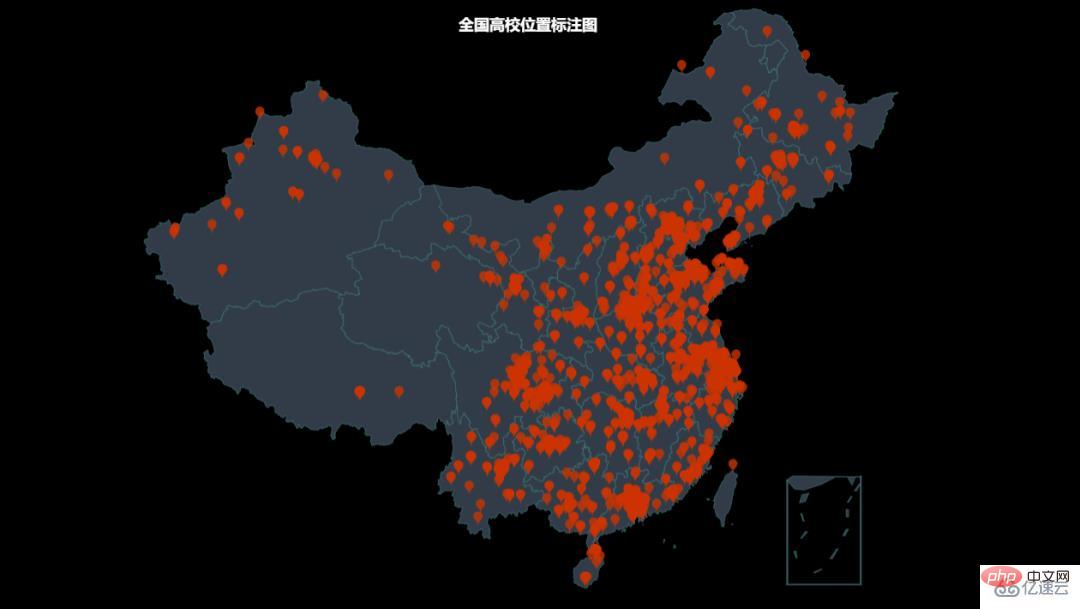
주석 결과에 따르면 대학은 주로 해안, 중부, 동부 지역에 분포되어 있으며 상대적으로 적습니다. 특히 고산지대에 분포한다.
2. 대학 분포 히트맵 그리기
from pyecharts.charts import Geo from pyecharts import options as opts from pyecharts.globals import ChartType import pandas as pd def draw_location_heatmap(): """绘制热力图""" geo = Geo(init_opts=opts.InitOpts(bg_color='black', width='1600px', height='900px')) df = pd.read_excel('school_lng_lat.xlsx') for row_index, row_data in df.iterrows(): geo.add_coordinate(row_data['name'], row_data['经度'], row_data['纬度']) data_pair = [(name, 2) for name in df['name']] geo.add_schema( maptype='china', is_roam=True, itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#408080') ).add( '', data_pair=data_pair, type_=ChartType.HEATMAP ).set_series_opts( label_opts=opts.LabelOpts(is_show=False) ).set_global_opts( title_opts=opts.TitleOpts(title='全国高校分布热力图', pos_left='650', pos_top='20', title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16)), visualmap_opts=opts.VisualMapOpts() ).render('high_school_heatmap.html')
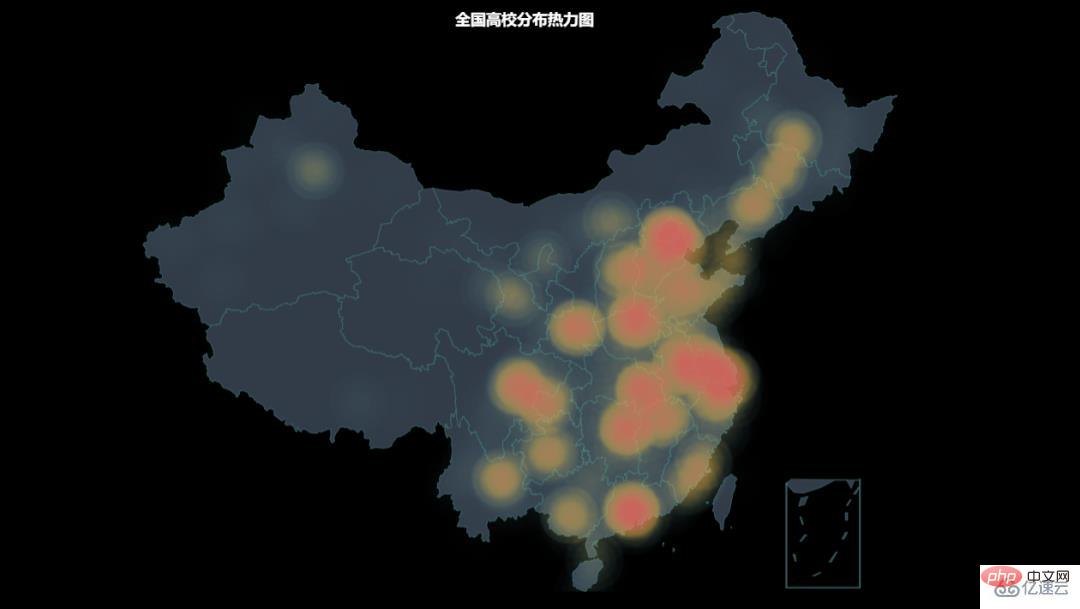
히트맵에서 대학이 더 밀집된 곳은 주로 해안 지역, 북부, 상하이, 광저우, 그리고 양쯔강과 황하 유역이 있으며, 쓰촨성과 충칭은 서쪽에 더 많은 곳이 있는 유일한 곳입니다.
3.绘制按省划分的分布密度图
from pyecharts.charts import Map
from pyecharts import options as opts
import pandas as pd
def draw_location_density_map():
"""绘制各省高校分布密度图"""
map = Map(init_opts=opts.InitOpts(bg_color='black', width='1200px', height='700px'))
df = pd.read_excel('school_lng_lat.xlsx')
s = df['province_name'].value_counts()
data_pair = [[province, int(s[province])] for province in s.index]
map.add(
'', data_pair=data_pair, maptype="china"
).set_global_opts(
title_opts=opts.TitleOpts(title='全国高校按省分布密度图', pos_left='500', pos_top='70',
title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16)),
visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True, pos_left='100', pos_bottom='100',textstyle_opts=opts.TextStyleOpts(color='white', font_size=16))
).render("high_school_density.html")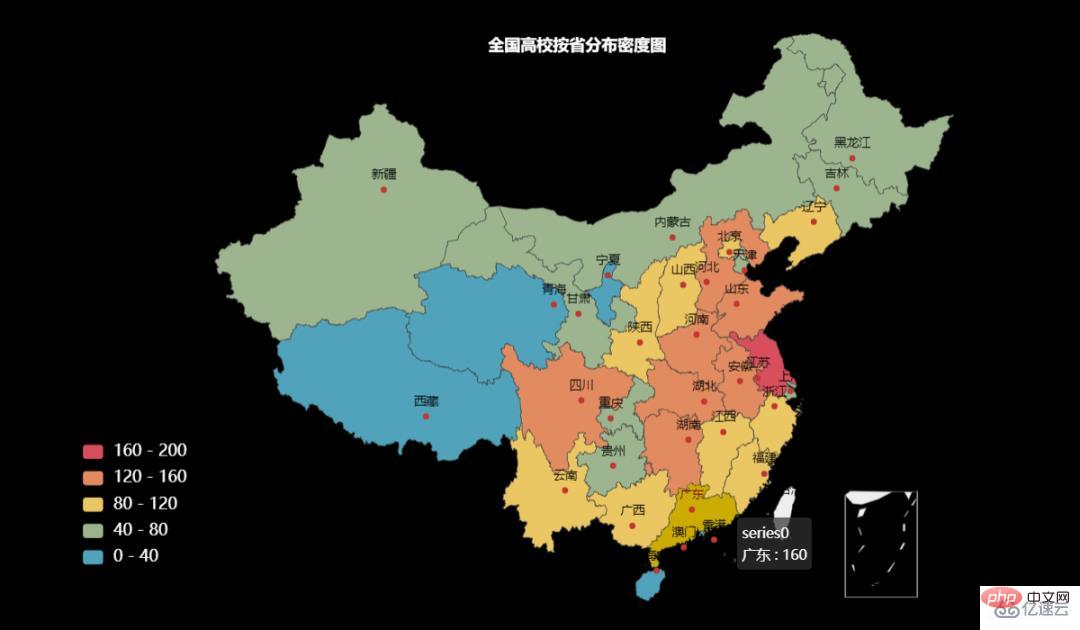
从省级分布密度图可以看出,高校数量多的省份集中在中部和东部,尤其是北京和上海附近的几个省。
4.211和985高校的分布情况
筛选出211和985的高校数据,再绘制一次。(代码不重复粘贴,只需要加一行筛选代码即可)
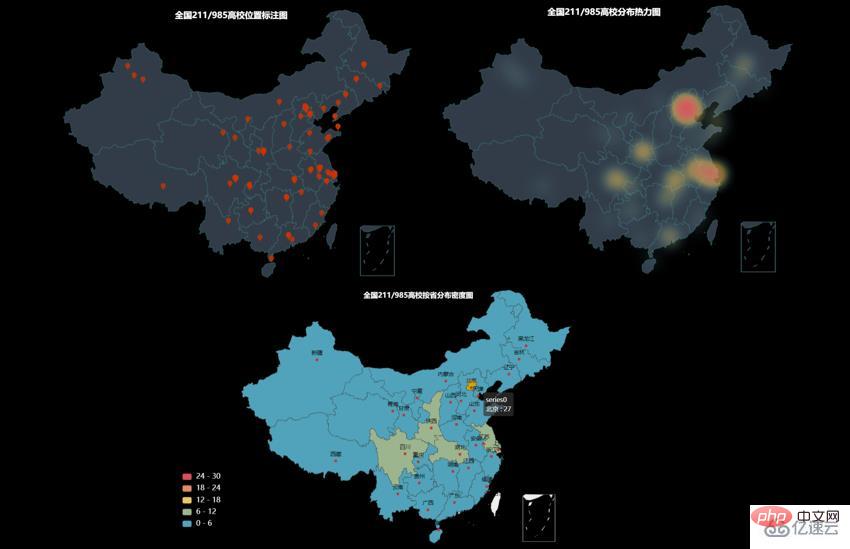
위 내용은 Python을 사용하여 전국 대학의 분포를 표시하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!