
슈퍼 프로그래밍된 AI가 사이언스 표지에 등장! AlphaCode 프로그래밍 콘테스트: 프로그래머의 절반이 콘테스트에 참가합니다.

- 王林앞으로
- 2023-04-30 13:19:061324검색
OpenAI의 ChatGPT가 각광받는 올 12월, 한때 프로그래머의 절반을 압도했던 알파코드가 사이언스 표지를 장식했습니다!

논문 링크: https://www.science.org/doi/10.1126/science.abq1158
AlphaCode라고 하면 누구나 익숙할 텐데요.
올해 2월 초, 유명 코드포스의 프로그래밍 대회 10개에 조용히 참가해 인간 코더 절반을 단숨에 물리쳤습니다.
코더의 절반이 누워있습니다
우리 모두는 이러한 테스트가 프로그래머-프로그래밍 대회에서 매우 인기가 있다는 것을 알고 있습니다.
대회에서 주요 테스트는 경험을 통해 비판적으로 사고하고 예상치 못한 문제에 대한 해결책을 만들어내는 프로그래머의 능력입니다.
이것은 인간 지능의 핵심을 구현하며, 기계 학습 모델은 이러한 인간 지능을 모방하기 어려운 경우가 많습니다.
그러나 DeepMind의 과학자들은 이 규칙을 어겼습니다.
YujiA Li 외 연구진은 자기 지도 학습 및 인코더-디코더 변환기 아키텍처를 사용하여 AlphaCode를 개발했습니다.

AlphaCode의 개발 작업은 집에서 완료되었습니다
AlphaCode도 표준 Transformer 코덱 아키텍처를 기반으로 하지만 DeepMind는 이를 "서사시적인 수준"으로 향상시켰습니다 ——
Transformer 기반 언어 모델을 사용하여 전례 없는 규모로 코드를 생성한 다음 사용 가능한 작은 프로그램 세트를 교묘하게 필터링합니다.
구체적인 단계는 다음과 같습니다.
1) 다중 요청 주의: 각 주의 블록이 키와 값 헤더를 공유하고 동시에 인코더-디코더 모델과 결합하여 샘플링 속도가 향상되도록 합니다. AlphaCode가 10배 이상 개선되었습니다.
2) Masked Language Modeling (MLM): 인코더에 MLM 손실을 추가하여 모델의 해결 속도가 향상됩니다.
3) Tempering: 훈련 분포를 더 날카롭게 만들어 과적합의 정규화 효과를 방지합니다.
4) 가치 조건화 및 예측: CodeContests 데이터 세트에서 올바른 질문 제출과 잘못된 질문 제출을 구별하여 추가 교육 신호를 제공합니다.
5) 예시적인 전략 외 학습 생성(GOLD): 각 문제에 대해 가장 가능성이 높은 솔루션에 교육을 집중하여 모델이 각 문제에 대한 올바른 솔루션을 생성하도록 합니다.
뭐, 결과는 다들 아시죠.
Elo 점수 1238점으로 AlphaCode는 이 10개 게임에서 상위 54.3%를 기록했습니다. 지난 6개월을 보면 이 결과는 상위 28%에 달했다.
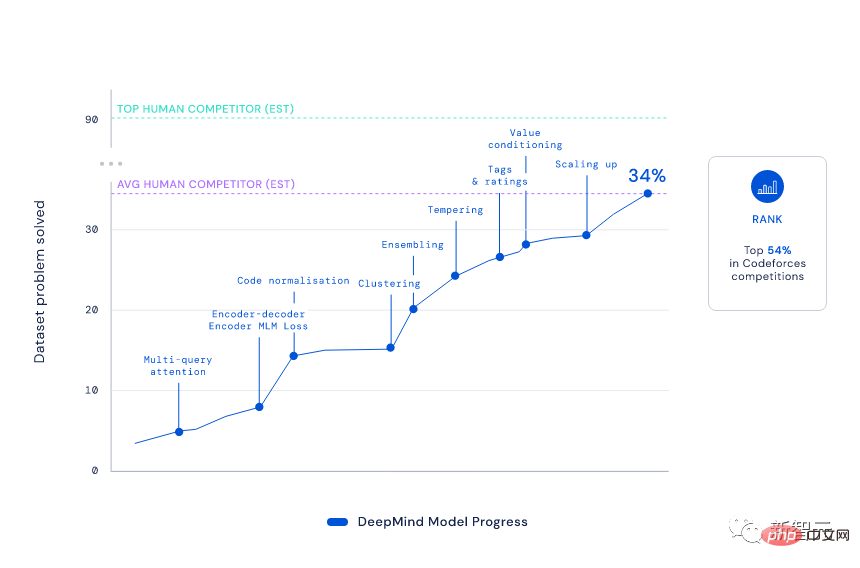
이 순위를 달성하려면 AlphaCode가 "5개 레벨을 통과하고 6명의 장군을 물리쳐야" 하고 비판적 사고, 논리, 알고리즘, 코딩 및 자연어 이해를 결합하여 다양하고 새로운 문제를 해결해야 한다는 것을 알아야 합니다. .
결과에 따르면 AlphaCode는 CodeContests 데이터 세트의 프로그래밍 문제 중 29.6%를 해결했을 뿐만 아니라 첫 번째 제출에서 그 중 66%를 해결했습니다. (총 제출 횟수는 10회로 제한됩니다.)
이에 비해 기존 Transformer 모델의 해결률은 한 자릿수로 상대적으로 낮습니다.
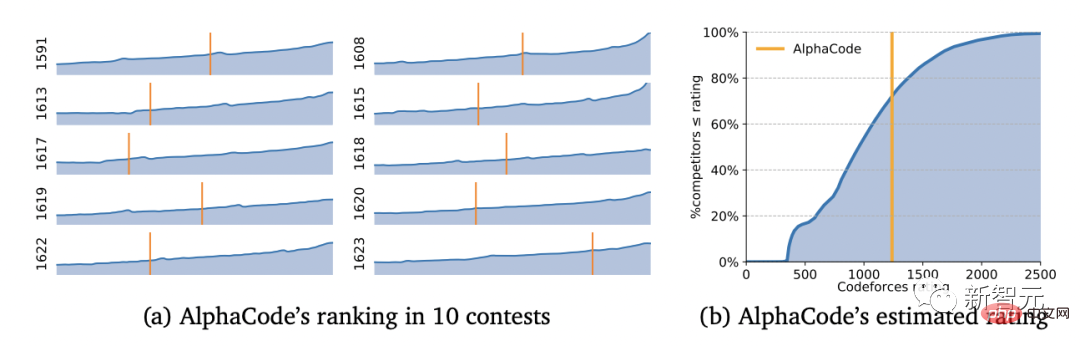
Codeforces 창립자 Mirzayanov도 이 결과에 매우 놀랐습니다.
결국 프로그래밍 대회는 항상 AI의 약점이자 인간의 강점이었던 알고리즘 발명 능력을 테스트하는 것입니다.
AlphaCode의 결과가 기대 이상이었다고 확실히 말할 수 있습니다. 단순한 경쟁 문제에서도 알고리즘을 구현해야 할 뿐만 아니라 이를 발명해야 하기 때문에 처음에는 회의적이었습니다(가장 어려운 부분임). AlphaCode는 많은 인간에게 강력한 상대가 되었습니다. 미래가 어떻게 될지 정말 기대됩니다!
——Codeforces 창립자 Mike Mirzayanov
그렇다면 AlphaCode가 프로그래머의 일자리를 훔칠 수 있을까요?
물론 아직은 아닙니다.
AlphaCode는 단순한 프로그래밍 작업만 완료할 수 있습니다. 작업이 더 복잡해지고 문제가 더 "예측 불가능"해지면 명령만 코드로 변환하는 AlphaCode는 무력해질 것입니다.
결국 어떤 관점에서 보면 1238점은 이제 막 프로그래밍을 배우는 중학생의 수준에 해당합니다. 이 수준에서는 실제 프로그래밍 전문가에게는 위협이 되지 않습니다.
그러나 이러한 유형의 코딩 플랫폼의 개발이 프로그래머 생산성에 큰 영향을 미칠 것이라는 데는 의심의 여지가 없습니다.
전체 프로그래밍 문화도 바뀔 수 있습니다. 아마도 미래에는 인간이 문제를 공식화하는 책임만 맡고 코드 생성 및 실행 작업은 기계 학습에 넘겨질 수 있습니다.
프로그래밍 대회가 뭐가 그렇게 어렵나요?
우리는 기계 학습이 텍스트를 생성하고 이해하는 데 큰 진전을 이루었지만 현재 대부분의 AI는 여전히 단순한 수학과 프로그래밍 문제로 제한되어 있다는 것을 알고 있습니다.
그들이 할 일은 기존 솔루션을 검색하고 복사하는 것입니다(최근 ChatGPT를 플레이해본 사람이라면 누구나 이 점을 잘 이해할 것이라고 믿습니다).
그렇다면 AI가 올바른 프로그램을 생성하는 방법을 배우는 것이 왜 그렇게 어려운가요?
1. 지정된 작업을 해결하는 코드를 생성하려면 가능한 모든 문자 시퀀스를 검색해야 하며 그 중 일부만이 효과적인 올바른 프로그램에 해당합니다.
2. 단일 문자를 편집하면 프로그램의 동작이 완전히 바뀌거나 심지어 충돌이 발생할 수도 있으며, 각 작업에는 다양하고 유효한 솔루션이 있습니다.
매우 어려운 프로그래밍 대회의 경우 AI는 단순히 코드 조각을 암기하는 것이 아니라 이전에 본 적이 없는 문제에 대해 추론해야 하며 다양한 알고리즘과 데이터 구조를 정확하게 숙달해야 합니다. 수백 줄 길이의 완전한 코드입니다.
또한 생성된 코드를 평가하기 위해 AI는 철저한 숨겨진 테스트 세트에 대한 작업을 수행하고 실행 속도와 엣지 케이스의 정확성을 확인해야 합니다.

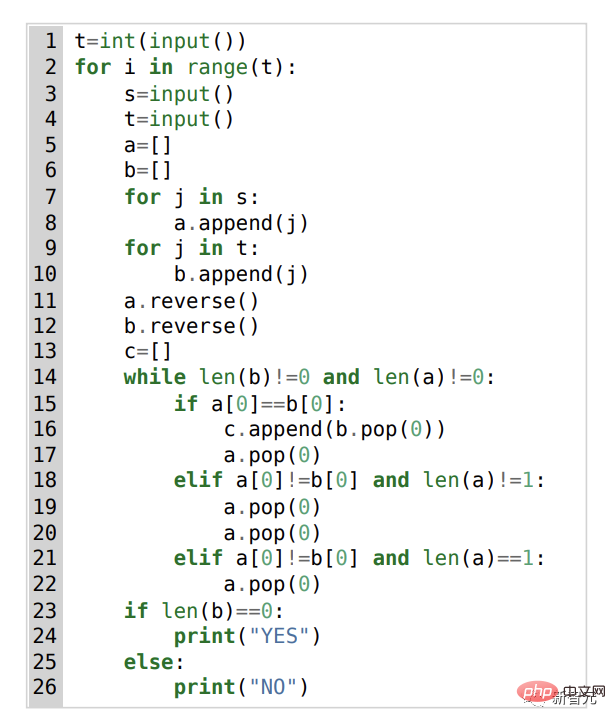
(A) 문제 1553D, 중간 난이도 점수는 1500입니다. (B) AlphaCode에서 생성된 문제 해결 방법
이 1553D 문제를 예로 들어, 참가자는 변환 방법을 찾아야 합니다. 제한된 입력 세트를 사용하여 무작위로 반복되는 s 및 t 문자 문자열을 동일한 문자의 다른 문자열로 변환합니다.
참가자는 새 문자를 입력할 수 없으며 "백스페이스" 명령을 사용하여 원래 문자열에서 여러 문자를 삭제해야 합니다. 구체적인 질문은 다음과 같습니다.

이와 관련하여 AlphaCode의 솔루션은 다음과 같습니다.
또한 AlphaCode의 "문제 해결 아이디어"는 더 이상 블랙 박스가 아니라 코드와 주목 하이라이트 위치도 표시할 수 있습니다.
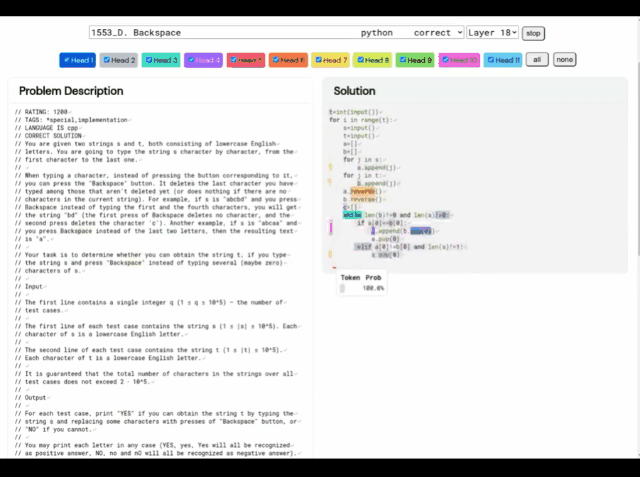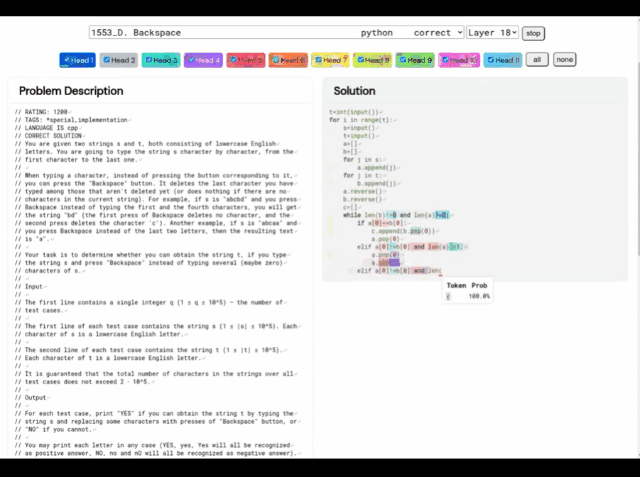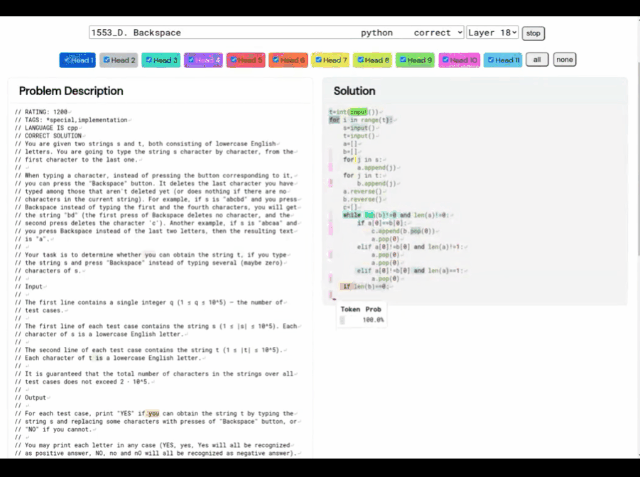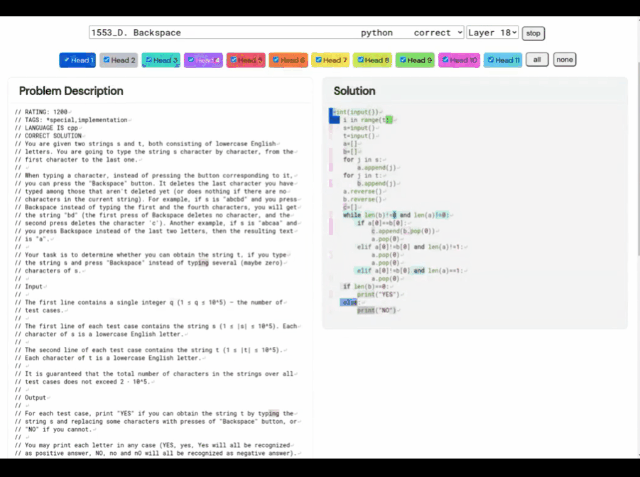
AlphaCode의 학습 시스템
프로그래밍 대회에 참가할 때 AlphaCode가 직면하는 주요 과제는 다음과 같습니다.
(i) 거대한 프로그램 공간에서 검색해야 하고, (ii) 약 13,000개의 예제 작업만 받아야 합니다. 교육용, (iii) 질문당 제출 횟수가 제한되어 있습니다.
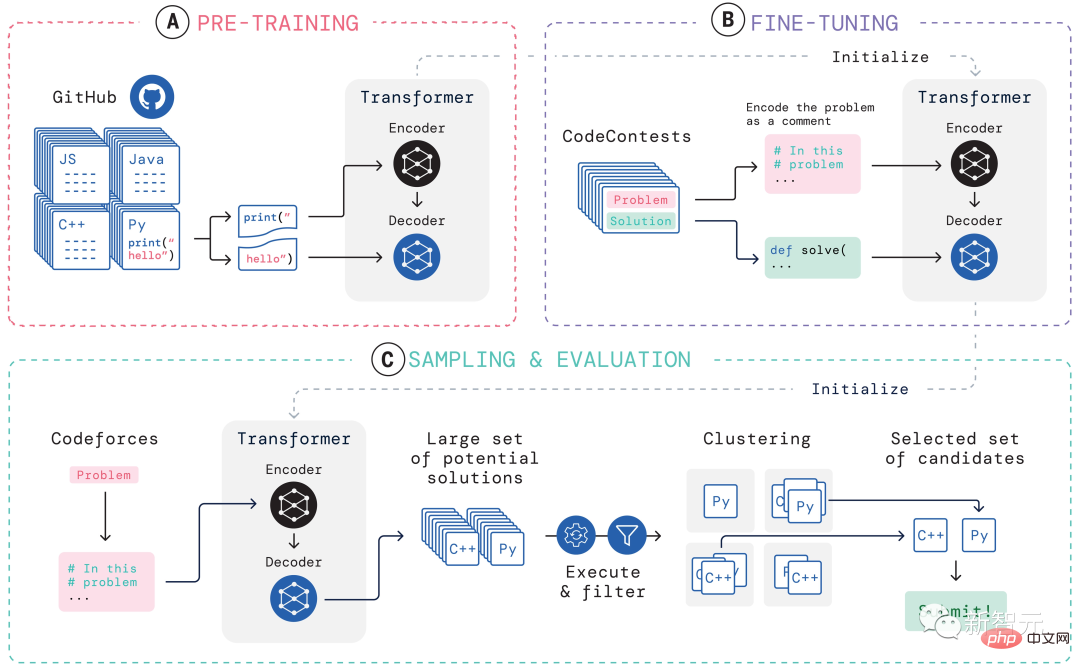
이러한 문제를 해결하기 위해 AlphaCode의 전체 학습 시스템 구성은 위 그림과 같이 사전 훈련, 미세 조정, 샘플링 및 평가의 세 가지 링크로 구분됩니다.
사전 교육
사전 교육 단계에서는 GitHub에서 수집된 인간 코더의 715GB 코드 스냅샷을 사용하여 모델을 사전 교육하고 크로스 엔트로피 다음 토큰을 사용하여 예측합니다. 손실. 사전 학습 과정에서 코드 파일은 무작위로 두 부분으로 나뉘며, 첫 번째 부분은 인코더의 입력으로 사용되고, 모델은 인코더를 제거하여 두 번째 부분을 생성하도록 학습됩니다.
이 사전 훈련은 인코딩에 대한 강력한 사전 학습을 통해 더 작은 데이터 세트에서 후속 작업별 미세 조정을 수행할 수 있습니다.
미세 조정
미세 조정 단계에서 모델은 DeepMind에서 생성하고 CodeContests로 공개적으로 공개된 2.6GB 경쟁 프로그래밍 문제 데이터 세트에서 미세 조정 및 평가되었습니다.
CodeContests 데이터 세트에는 질문과 테스트 사례가 포함되어 있습니다. 훈련 세트에는 13,328개의 질문이 포함되어 있으며, 질문당 평균 922.4개의 답변이 제출되었습니다. 검증 세트와 테스트 세트에는 각각 117개와 165개의 질문이 포함되어 있습니다.
미세 조정 중에 자연어 문제 설명을 프로그램 주석으로 인코딩하여 사전 훈련 중에 표시된 파일(확장된 자연어 주석을 포함할 수 있음)과 더 유사하게 보이고 동일한 다음 토큰 예측을 사용합니다. 손실.
Sampling
제출할 최고의 샘플 10개를 선택하기 위해 필터링 및 클러스터링 방법을 사용하여 문제 설명에 포함된 예제 테스트를 사용하여 샘플을 실행하고 이 테스트 샘플에 실패한 샘플을 제거합니다.
거의 99%의 모델 샘플을 필터링하고, 나머지 후보 샘플을 클러스터링하고, 별도의 변환기 모델에서 생성된 입력에서 이러한 샘플을 실행하고, 생성된 입력 프로그램에서 동일한 출력을 생성하고 하나의 범주로 그룹화합니다.
그런 다음 가장 큰 10개의 클러스터 각각에서 하나의 샘플을 선택하여 제출하세요. 직관적으로 올바른 프로그램은 동일하게 동작하고 대규모 클러스터를 형성하는 반면, 잘못된 프로그램은 다양한 방식으로 실패합니다.
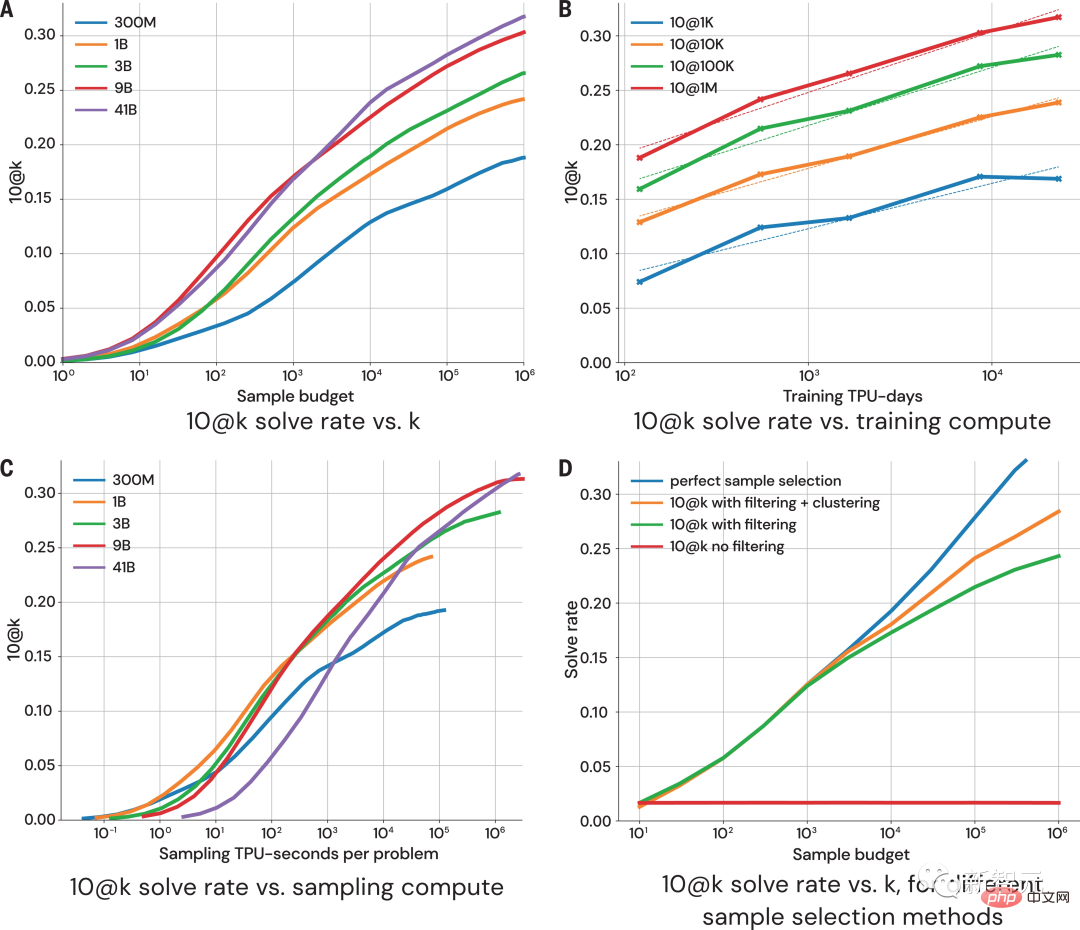
Evaluation
위 그림은 10@k 지표에서 표본 크기와 계산량이 많아짐에 따라 모델 성능이 어떻게 변하는지 보여줍니다. 샘플링 결과의 성능 평가에서 연구원들은 다음과 같은 네 가지 결론에 도달했습니다.
1. 샘플 크기가 커질수록 솔루션 속도가 대수적으로 선형으로 확장됩니다.
2 모델의 기울기가 더 높습니다. 스케일링 곡선; 3. 솔루션 비율은 더 많은 계산에 대해 로그 선형 비례합니다. 4. 솔루션 비율을 확장하려면 샘플 선택이 중요합니다. 순수한 "데이터 기반" AlphaCode의 도입이 기계 학습 모델 개발에 있어 중요한 단계를 의미한다는 것은 의심의 여지가 없습니다. 흥미롭게도 AlphaCode에는 컴퓨터 코드 구조에 대한 명시적인 내장 지식이 포함되어 있지 않습니다. 대신, 단순히 대량의 기존 코드를 관찰하여 컴퓨터 프로그램의 구조를 배우는 순전히 "데이터 기반" 코드 작성 접근 방식을 사용합니다. 기사 주소: https://www.science.org/doi/10.1126/science.add8258 기본적으로 AlphaCode는 경쟁력 있는 프로그래밍 작업에서 다른 시스템보다 성능이 뛰어납니다. 이유는 두 가지로 요약됩니다. 주요 속성: 1. 훈련 데이터 2. 후보 솔루션의 후처리 그러나 컴퓨터 코드는 고도로 구조화된 매체이고 프로그램은 정의된 구문을 준수해야 하며 명시적인 사전-처리를 생성해야 합니다. 솔루션의 여러 부분에 대한 사후 조건이 있습니다. 코드를 생성할 때 AlphaCode에서 사용하는 방법은 다른 텍스트 콘텐츠를 생성할 때와 완전히 동일합니다. 즉, 한 번에 하나의 토큰이며, 프로그램의 정확성은 전체 프로그램이 작성된 후에만 확인됩니다. 적절한 데이터와 모델 복잡성이 주어지면 AlphaCode는 일관된 구조를 생성할 수 있습니다. 그러나 이 순차 생성 절차의 최종 방법은 LLM 매개 변수 내에 깊이 묻혀 있어 파악하기 어렵습니다. 그러나 AlphaCode가 프로그래밍 문제를 실제로 "이해"할 수 있는지 여부에 관계없이 코딩 대회에서는 평균적인 인간 수준에 도달합니다. "프로그래밍 경쟁 문제를 해결하는 것은 매우 어려운 일이며 좋은 코딩 기술과 문제 해결 창의성을 갖춘 인간이 필요합니다. AlphaCode가 이 분야에서 진전을 이룰 수 있다는 사실에 깊은 인상을 받았습니다. 어떻게 될지 기대됩니다. 모델은 명령문 이해를 활용하여 코드를 생성하고 확률론적 탐색을 안내하여 솔루션을 만듭니다. — Google 소프트웨어 엔지니어이자 세계적 수준의 경쟁력 있는 프로그래머인 Petr Mitrichev AlphaCode가 상위 54%에 선정되었습니다. 비판적 사고가 필요한 작업에서 딥 러닝 모델의 잠재력을 보여주는 프로그래밍 대회입니다. 그리고 이것은 시작에 불과합니다. 미래에는 문제를 해결할 수 있는 더욱 강력한 AI가 탄생할 날이 멀지 않았을 것입니다. 
이 모델은 최신 기계 학습을 우아하게 활용하여 문제에 대한 해결책을 코드로 표현하며 수십 년 전 AI의 상징적 추론 뿌리로 돌아갑니다.
위 내용은 슈퍼 프로그래밍된 AI가 사이언스 표지에 등장! AlphaCode 프로그래밍 콘테스트: 프로그래머의 절반이 콘테스트에 참가합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!