
긴 코드 시나리오에서 성능을 향상시키기 위한 긴 코드 시퀀스에 대한 변환기 모델 최적화 방법

- PHPz앞으로
- 2023-04-29 08:34:061971검색
Alibaba 클라우드 머신 러닝 플랫폼 PAI는 중국 화동 사범 대학의 Gao Ming 교수팀과 협력하여 SIGIR2022에서 구조 인식 희소 관심 트랜스포머 모델 SASA를 발표했습니다. 이는 긴 코드 시퀀스를 개선하는 데 전념하는 트랜스포머 모델 최적화 방법입니다. 긴 코드 시퀀스의 성능 및 성능. self-attention 모듈의 복잡성은 시퀀스 길이에 따라 기하급수적으로 증가하므로 대부분의 프로그래밍 기반 PPLM(사전 훈련된 언어 모델)은 시퀀스 절단을 사용하여 코드 시퀀스를 처리합니다. SASA 방법은 self-attention 계산을 줄이고 코드의 구조적 특성을 결합하여 긴 시퀀스 작업의 성능을 향상시키고 메모리와 계산 복잡성을 줄입니다.
논문: Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao 및 Aoying Zhou. SIGIR 2022를 통한 긴 프로그래밍 언어 이해
모델 프레임워크
다음 그림은 SASA의 전체 프레임워크를 보여줍니다. :

그 중 SASA는 주로 전처리 단계와 Sparse Transformer 훈련 단계의 두 단계로 구성됩니다. 전처리 단계에서는 두 토큰 사이의 상호 작용 행렬이 얻어지며, 하나는 top-k 주파수 행렬이고 다른 하나는 AST 패턴 행렬입니다. Top-k 주파수 행렬은 코드 사전 훈련된 언어 모델을 사용하여 CodeSearchNet 코퍼스에서 토큰 간의 주의 상호 작용 빈도를 학습합니다. AST 패턴 행렬은 코드를 구문 분석하는 AST(Abstract Syntax Tree)입니다. 토큰 간의 대화형 정보에 대한 구문 트리의 연결 관계에 대한 정보입니다. Sparse Transformer 훈련 단계에서는 Transformer Encoder를 기본 프레임워크로 사용하고, 전체 self-attention을 구조 인식 sparse self-attention으로 대체하고, 특정 패턴을 따르는 토큰 쌍 간에 attention 계산을 수행하여 계산 복잡성을 줄입니다.
SASA sparse attention에는 총 4개의 모듈이 포함됩니다.
- Sliding window attention: 로컬 컨텍스트의 특성을 유지하면서 슬라이딩 윈도우의 토큰 간 self-attention만 계산합니다. 계산 복잡성은 시퀀스 길이입니다. 슬라이딩 윈도우 크기입니다.
- 글로벌 어텐션: 특정 글로벌 토큰을 설정합니다. 이 토큰은 시퀀스의 글로벌 정보를 얻기 위해 시퀀스의 모든 토큰에 대해 어텐션 계산을 수행합니다. 계산 복잡성은 글로벌 토큰의 수입니다.
- Top-k 희소 주의: Transformer 모델의 주의 상호 작용은 희박하고 긴 꼬리입니다. 각 토큰에 대해 주의 상호 작용이 가장 높은 상위 k 토큰만 계산됩니다.
- AST 인식 구조 어텐션: 코드는 자연어 시퀀스와 다르며 더 강력한 구조적 특성을 가집니다. 코드를 추상 구문 트리(AST)로 구문 분석하여 구문 트리의 연결 관계를 기반으로 어텐션 계산 범위가 결정됩니다. .
현대 하드웨어의 병렬 컴퓨팅 특성에 적응하기 위해 시퀀스를 토큰 단위로 계산하는 대신 여러 블록으로 나눕니다. 각 쿼리 블록에는

슬라이딩 윈도우 블록과

글로벌 블록이 있습니다. 그리고
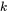
top-k 및 AST 블록은 attention을 계산합니다. 전체 계산 복잡도는

b는 블록 크기입니다.
각 희소 주의 패턴은 주의 행렬에 해당합니다. 예를 들어 슬라이딩 창 주의를 사용하면 주의 행렬의 계산은 다음과 같습니다.

ASA 의사 코드:

실험 결과
평가를 위해 CodeXGLUE[1]에서 제공하는 4가지 작업 데이터 세트, 즉 코드 복제 감지, 결함 감지, 코드 검색 및 코드 요약을 사용합니다. 긴 시퀀스 데이터 세트를 구성하기 위해 시퀀스 길이가 512보다 큰 데이터를 추출했습니다. 실험 결과는 다음과 같습니다.
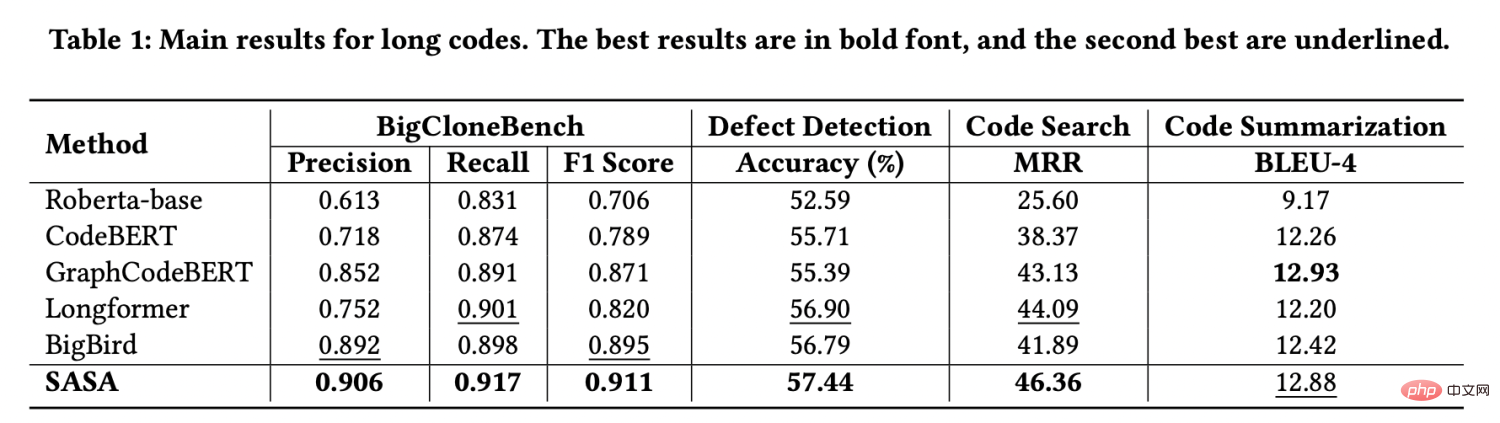
실험 결과에서 볼 수 있듯이 세 가지 데이터 세트에서 SASA의 성능이 크게 향상되었습니다. 모든 기준선을 초과합니다. 그 중 Roberta-base[2], CodeBERT[3], GraphCodeBERT[4]는 긴 시퀀스를 처리하기 위해 잘림을 사용하는데, 이로 인해 컨텍스트 정보의 일부가 손실됩니다. Longformer[5]와 BigBird[6]는 자연어 처리에서 긴 시퀀스를 처리하는 데 사용되는 방법이지만 코드의 구조적 특성을 고려하지 않아 코드 작업으로 직접 전달하는 것은 효과적이지 않습니다.
top-k sparse attention 및 AST-aware sparse attention 모듈의 효과를 검증하기 위해 BigCloneBench 및 DefectDetection 데이터 세트에 대한 절제 실험을 수행했습니다. 결과는 다음과 같습니다.

Sparse attention 모듈. 긴 코드 작업에만 적합하지 않습니다. 성능이 향상되었으며 비디오 메모리 사용량이 크게 줄어들 수 있습니다. 동일한 장치에서 SASA는 더 큰 배치 크기를 설정할 수 있지만 전체 self-attention 모델은 부족 문제에 직면합니다. 메모리의 구체적인 비디오 메모리 사용량은 다음과 같습니다.

SASA는 희소 주의 모듈로서 Transformer를 기반으로 하는 다른 사전 훈련된 모델로 마이그레이션하여 긴 시퀀스 자연어 처리 작업을 처리할 수 있습니다. 오픈 소스 프레임워크 EasyNLP(https://github.com/alibaba/EasyNLP)를 개발하고 오픈 소스 커뮤니티에 기여합니다.
논문 링크:
https://arxiv.org/abs/2205.13730
위 내용은 긴 코드 시나리오에서 성능을 향상시키기 위한 긴 코드 시퀀스에 대한 변환기 모델 최적화 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!