
직장에서의 Java 잠금 사용 시나리오 분석

- PHPz앞으로
- 2023-04-28 15:34:141180검색
1. 동기화됨
synchronized는 ReentrantLock 잠금과 유사한 기능을 가지고 있습니다. 두 잠금의 가장 큰 유사점은 ReentrantLock입니다. 주요 차이점은 다음과 같습니다.
ReentrantLock에는 조건 제공, 중단 가능한 잠금 API, 잠금 + 대기열 등의 복잡한 시나리오를 충족할 수 있는 등 더욱 풍부한 기능이 있습니다.
ReentrantLock은 공정한 잠금과 불공정한 잠금으로 나눌 수 있습니다. 동기화된 잠금은 둘 다 불공평한 잠금입니다. - 둘의 사용 자세도 다릅니다. ReentrantLock은 잠금 및 해제를 위한 API가 있음을 선언해야 하지만 동기화는 자동으로 잠금 및 해제 작업을 수행합니다. 잠금을 해제하고 동기화하는 것이 사용하기 더 편리합니다.
- synchronized와 ReentrantLock은 비슷한 기능을 갖고 있으므로 동기화를 예로 들어보겠습니다.
1.1. 공유 리소스 초기화
분산 시스템에서는 프로젝트가 시작될 때 일부 작동하지 않는 구성 리소스를 JVM 메모리에 잠가서 이러한 공유 구성 리소스를 요청할 때 대신 메모리에서 직접 가져올 수 있습니다. 매번 데이터베이스에서 가져오므로 시간 오버헤드가 줄어듭니다.
일반적으로 이러한 공유 리소스에는 죽은 비즈니스 프로세스 구성 + 죽은 비즈니스 규칙 구성이 포함됩니다.
공유 리소스를 초기화하는 단계는 일반적으로 다음과 같습니다. 프로젝트 시작 -> 초기화 작업 트리거 -> 단일 스레드로 데이터베이스에서 데이터 검색 -> JVM 메모리.
프로젝트가 시작되면 공유 리소스가 여러 번 로드되는 것을 방지하기 위해 종종 배타적 잠금을 추가하므로 한 스레드가 공유 리소스 로드를 완료한 후 다른 스레드가 계속 로드될 수 있습니다. 배타적 잠금 동기화 또는 ReentrantLock을 예로 들어 동기화를 다음과 같이 모의 코드를 작성했습니다.
// 共享资源
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// 有无初始化完成的标志位
private static boolean loaded = false;
/**
* 初始化共享资源
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// 再次 check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// 从数据库中捞取数据,组装成 SHARED_MAP 的数据格式
loaded = true;
log.info("SynchronizedDemo init end");
}
}위 코드에서 @PostConstruct 주석을 찾았는지 모르겠습니다. @PostConstruct 주석의 기능은 다음과 같습니다. Spring 컨테이너가 초기화될 때 @PostConstruct 주석을 실행하기 위해 주석으로 표시된 메소드는 Spring 컨테이너가 시작될 때 위 그림에 표시된 init 메소드가 트리거된다는 것을 의미합니다.
데모 코드를 다운로드하고, DemoApplication 시작 파일을 찾은 다음, DemoApplication 파일에서 실행을 마우스 오른쪽 버튼으로 클릭하여 전체 Spring Boot 프로젝트를 시작하고, init 메서드에 중단점을 넣어 디버그할 수 있습니다.
코드에서 동기화를 사용하여 하나의 스레드만 공유 리소스 초기화 작업을 동시에 수행할 수 있도록 하고, 로드가 완료되었는지 확인하기 위해 공유 리소스 로딩 완료 플래그(로드됨)를 추가합니다. 이면 다른 로딩 스레드가 직접 반환됩니다.
Synchronized를 ReentrantLock으로 바꾸는 경우 구현은 동일하지만 ReentrantLock을 잠그고 해제하려면 명시적으로 ReentrantLock의 API를 사용해야 합니다. ReentrantLock을 사용할 때 주의할 점은 try 메서드 블록을 잠가야 한다는 것입니다. , 그리고 finally에서 메서드 블록의 잠금을 해제하여 try에서 잠긴 후 예외가 발생하더라도 finally에서 잠금이 올바르게 해제될 수 있도록 합니다.
ConcurrentHashMap을 직접 사용할 수는 없나요? 왜 잠궈야 하나요? ConcurrentHashMap은 스레드로부터 안전하지만 Map 내부 데이터 작업 중에만 스레드 안전성을 보장할 수 있습니다. 다중 스레드 상황에서 데이터베이스 쿼리 및 데이터 수집의 전체 작업이 한 번만 실행된다는 것을 보장할 수는 없습니다. add syncised는 전체 작업을 잠그므로 전체 작업이 한 번만 실행됩니다.
2. CountDownLatch
2.1. 시나리오
1: 샤오밍이 타오바오에서 제품을 구매했는데 제품이 좋지 않아서 반품했습니다(제품이 아직 배송되지 않았으며 금액만 환불되었습니다). 이를 단일 제품 환불이라고 합니다. 단일 제품 환불이 백그라운드 시스템에서 실행될 때 전체 시간 소비는 30밀리초입니다.
2: Double 11에 Xiao Ming은 Taobao에서 40개의 제품을 구매하고 동일한 주문을 생성했습니다(실제로 여러 주문이 생성될 수 있으며 설명의 편의를 위해 이를 하나라고 부릅니다). 다음날 Xiao Ming은 30개의 제품을 발견했습니다. .. 충동구매였는데 30개를 한꺼번에 반품해야 합니다.
2.2. 구현
현재 백엔드에는 단일 상품 환불 기능만 있고, 일괄 상품 환불 기능은 없습니다. (한 번에 30개 상품을 일괄 반품하는 것을 일괄 반품이라고 합니다.) 이 기능을 구현하면 학생 A는 다음 계획을 따랐습니다. for 루프는 단일 제품 환불 인터페이스를 30번 호출합니다. QA 환경 테스트 중에 30개의 제품을 환불하려면 30 * 30 = 900이 소요되는 것으로 나타났습니다. 밀리초. .
同学 B 当时就提出,你可以使用线程池进行执行呀,把任务都提交到线程池里面去,假如机器的 CPU 是 4 核的,最多同时能有 4 个单商品退款可以同时执行,同学 A 觉得很有道理,于是准备修改方案,为了便于理解,我们把两个方案都画出来,对比一下:
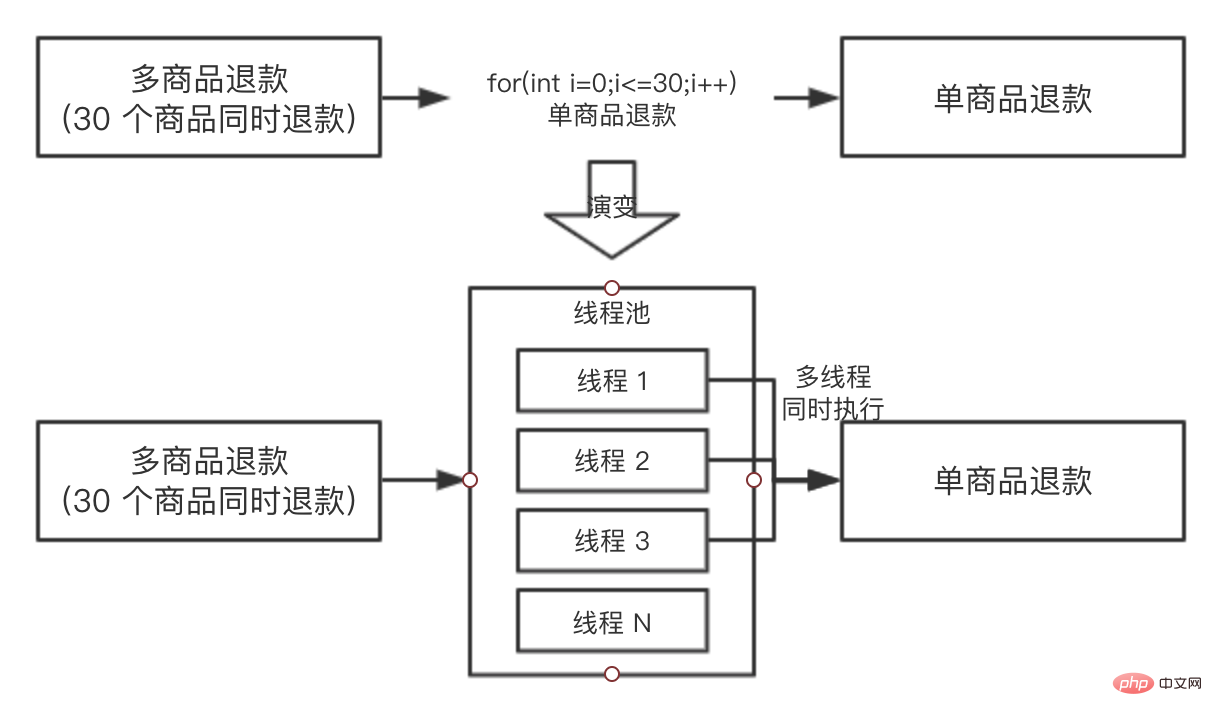
同学 A 于是就按照演变的方案去写代码了,过了一天,抛出了一个问题:向线程池提交了 30 个任务后,主线程如何等待 30 个任务都执行完成呢?因为主线程需要收集 30 个子任务的执行情况,并汇总返回给前端。
大家可以先不往下看,自己先思考一下,我们前几章说的那种锁可以帮助解决这个问题?
CountDownLatch 可以的,CountDownLatch 具有这种功能,让主线程去等待子任务全部执行完成之后才继续执行。
此时还有一个关键,我们需要知道子线程执行的结果,所以我们用 Runnable 作为线程任务就不行了,因为 Runnable 是没有返回值的,我们需要选择 Callable 作为任务。
我们写了一个 demo,首先我们来看一下单个商品退款的代码:
// 单商品退款,耗时 30 毫秒,退款成功返回 true,失败返回 false
@Slf4j
public class RefundDemo {
/**
* 根据商品 ID 进行退款
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// 线程沉睡 30 毫秒,模拟单个商品退款过程
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}接着我们看下 30 个商品的批量退款,代码如下:
@Slf4j
public class BatchRefundDemo {
// 定义线程池
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state 初始化为 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// 准备 30 个商品
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// 准备开始批量退款
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// 使用 Callable,因为我们需要等到返回值
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// 每个子线程都会执行 countDown,使 state -1 ,但只有最后一个才能真的唤醒主线程
countDownLatch.countDown();
return result;
}
});
// 收集批量退款的结果
futures.add(future);
}
log.info("30 个商品已经在退款中");
// 使主线程阻塞,一直等待 30 个商品都退款完成,才能继续执行
countDownLatch.await();
log.info("30 个商品已经退款完成");
// 拿到所有结果进行分析
List<Boolean> result = futures.stream().map(fu-> {
try {
// get 的超时时间设置的是 1 毫秒,是为了说明此时所有的子线程都已经执行完成了
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// 打印结果统计
long success = result.stream().filter(r->r.equals(true)).count();
log.info("执行结果成功{},失败{}",success,result.size()-success);
}
}上述代码只是大概的底层思路,真实的项目会在此思路之上加上请求分组,超时打断等等优化措施。
我们来看一下执行的结果:
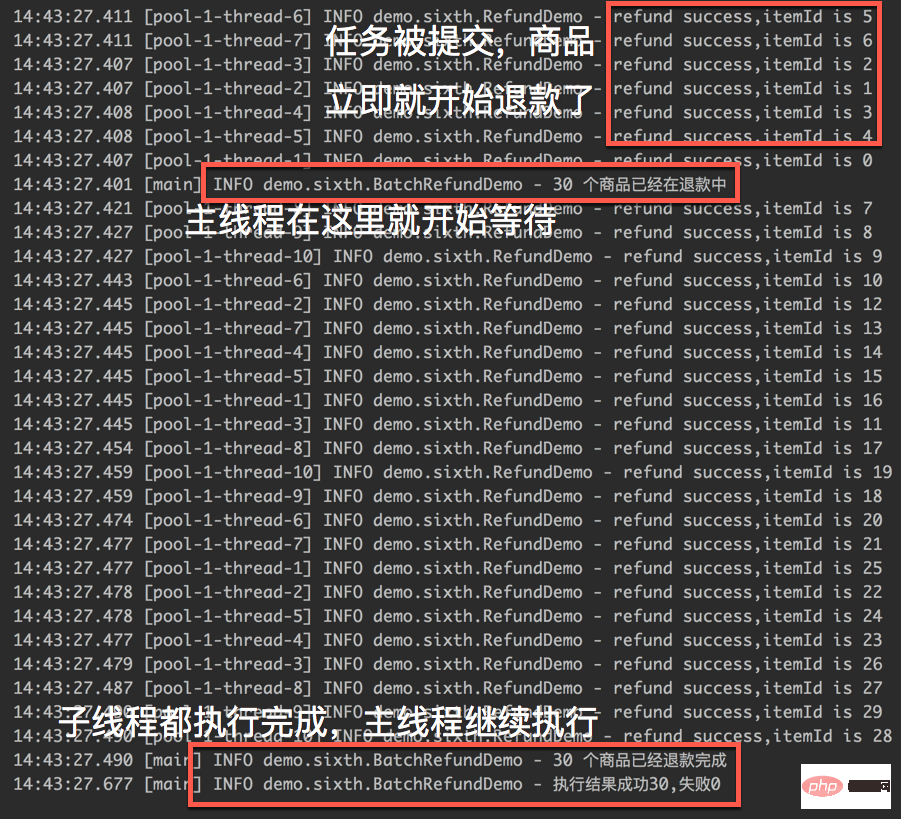
从执行的截图中,我们可以明显的看到 CountDownLatch 已经发挥出了作用,主线程会一直等到 30 个商品的退款结果之后才会继续执行。
接着我们做了一个不严谨的实验(把以上代码执行很多次,求耗时平均值),通过以上代码,30 个商品退款完成之后,整体耗时大概在 200 毫秒左右。
而通过 for 循环单商品进行退款,大概耗时在 1 秒左右,前后性能相差 5 倍左右,for 循环退款的代码如下:
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for 循环单个退款耗时{}",System.currentTimeMillis()-begin1);性能的巨大提升是线程池 + 锁两者结合的功劳。
위 내용은 직장에서의 Java 잠금 사용 시나리오 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!