
Google은 확산 모델을 최적화하고 있습니다. 삼성 휴대폰은 Stable Diffusion을 실행하고 12초 안에 이미지를 생성합니다.

- 王林앞으로
- 2023-04-28 08:19:141066검색
Stable Diffusion은 대화형 대형 모델에서 ChatGPT만큼 이미지 생성 분야에서도 잘 알려져 있습니다. 수십 초 안에 주어진 입력 텍스트의 사실적인 이미지를 생성할 수 있습니다. Stable Diffusion에는 10억 개 이상의 매개변수가 있고 장치의 제한된 컴퓨팅 및 메모리 리소스로 인해 이 모델은 주로 클라우드에서 실행됩니다.
주의 깊게 설계하고 구현하지 않고 이러한 모델을 기기에서 실행하면 반복적인 노이즈 제거 프로세스와 과도한 메모리 소비로 인해 지연 시간이 늘어날 수 있습니다.
기기에서 Stable Diffusion을 실행하는 방법은 모든 사람의 연구 관심을 불러일으켰습니다. 이전에 한 연구원은 Stable Diffusion을 사용하여 단 1분 만에 이미지를 생성하고 약 2GiB를 사용하는 애플리케이션을 개발했습니다.
Apple은 이전에도 이에 대한 몇 가지 최적화를 수행했으며 iPhone, iPad, Mac 및 기타 장치에서 30분 안에 512x512 해상도의 이미지를 생성할 수 있습니다. Qualcomm은 Android 휴대폰에서 Stable Diffusion v1.5를 실행하여 15초 이내에 512x512 해상도의 이미지를 생성하여 바짝 뒤쫓고 있습니다.
최근 Google에서 발행한 "Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations"라는 논문에서 GPU 기반 장치에서 실행되는 Stable Diffusion 1.4를 구현하여 다음과 같은 목표를 달성했습니다. SOTA 추론 지연 성능(Samsung S23 Ultra에서는 20번의 반복을 통해 512 × 512 이미지를 생성하는 데 11.5초 밖에 걸리지 않습니다.) 또한, 이 연구는 하나의 장치에만 국한된 것이 아니라 모든 잠재적 확산 모델을 개선하는 데 적용할 수 있는 일반적인 접근 방식입니다.
이 연구는 데이터 연결이나 클라우드 서버 없이 휴대폰에서 로컬로 생성 AI를 실행할 수 있는 많은 가능성을 열어줍니다. Stable Diffusion은 지난 가을에야 출시되었으며 이미 장치에 연결하여 실행할 수 있습니다. 이는 이 분야가 얼마나 빠르게 발전하고 있는지 보여줍니다.

문서 주소: https://arxiv.org/pdf/2304.11267.pdf
Google은 이러한 세대의 속도를 달성하기 위해 몇 가지 최적화 제안을 제시했습니다. Google이 어떻게 하는지 살펴보겠습니다. 그것.
방법 소개
본 연구의 목적은 다른 대규모 확산 모델에도 적용할 수 있는 Stable Diffusion에 대한 몇 가지 최적화 제안을 포함하여 대규모 확산 모델 Vincentian 다이어그램의 속도를 향상시키는 최적화 방법을 제안하는 것입니다.
먼저 그림 1과 같이 텍스트 임베더, 노이즈 생성, 노이즈 제거 신경망 및 이미지 디코더를 포함한 Stable Diffusion의 주요 구성 요소를 살펴보겠습니다.
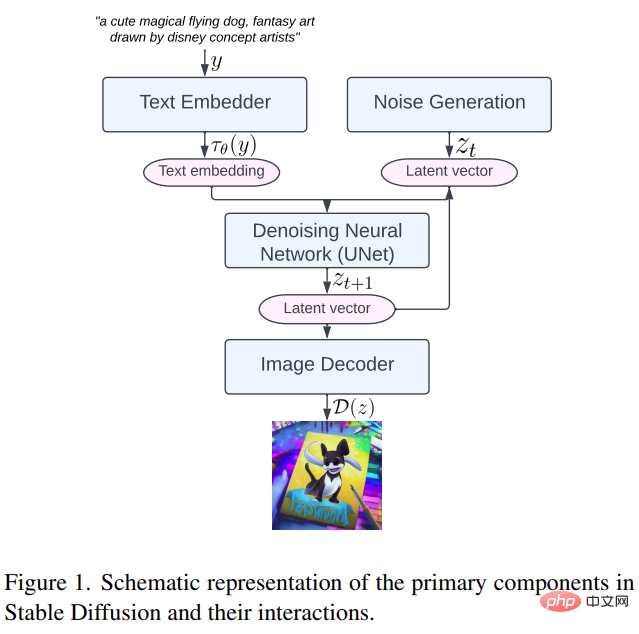
그런 다음 본 연구에서 제안된 세 가지 최적화 방법을 구체적으로 살펴봅니다.
특수 커널: Group Norm 및 GELU
( GN 방법의 작동 원리는 기능 맵의 채널을 더 작은 그룹으로 나누는 것입니다. 각 그룹을 독립적으로 정규화하여 GN이 배치 크기에 덜 의존하고 크기 및 네트워크 아키텍처에 더 적합하도록 만듭니다. 하나의 GPU 명령으로 이러한 모든 작업을 수행할 수 있습니다.
Gaussian Error Linear Unit(GELU)은 곱셈, 덧셈과 같은 많은 수치 계산을 포함하는 일반적으로 사용되는 모델 활성화 함수입니다. 및 가우스 오류 함수를 사용합니다. 이 연구에서는 이러한 수치 계산과 이에 수반되는 분할 및 곱셈 연산을 통합하여 단일 AI 페인트 호출로 수행할 수 있습니다.
주의 모듈의 효율성 향상
.Stable Diffusion의 텍스트-이미지 변환기는 텍스트-이미지 생성 작업에 중요한 조건부 분포를 모델링하는 데 도움이 됩니다. 그러나 self/cross-attention 메커니즘은 메모리 복잡성과 시간 복잡성으로 인해 긴 시퀀스를 처리하는 데 어려움을 겪습니다. 이를 바탕으로 본 연구에서는 계산 병목현상을 완화하기 위한 두 가지 최적화 방법을 제안한다.
한편, 대규모 행렬에서 전체 소프트맥스 계산을 수행하지 않기 위해 이 연구에서는 GPU 셰이더를 사용하여 계산 작업을 줄여 중간 텐서의 메모리 공간과 전체 대기 시간을 크게 줄입니다. 아래 그림 2에 나와 있습니다.

한편, 본 연구에서는 IO 인식 정밀 주의 알고리즘인 FlashAttention[7]을 사용하여 고대역폭 메모리(HBM) 액세스 횟수를 표준 주의 메커니즘보다 적게 만듭니다. 전반적인 효율성을 향상시킵니다.
Winograd 컨볼루션
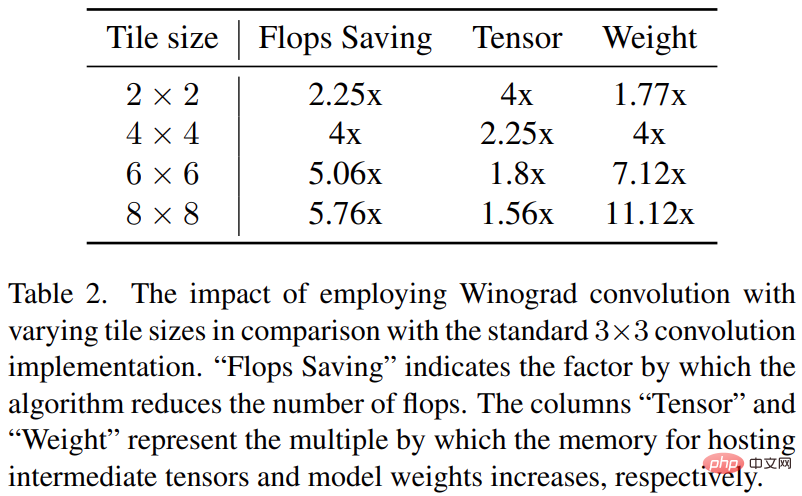
Winograd 컨볼루션은 컨볼루션 연산을 일련의 행렬 곱셈으로 변환합니다. 이 방법을 사용하면 많은 곱셈 연산을 줄이고 계산 효율성을 높일 수 있습니다. 그러나 이는 특히 더 큰 타일을 사용할 때 메모리 소비와 수치 오류를 증가시킵니다.
Stable Diffusion의 백본은 3×3 컨볼루션 레이어에 크게 의존하며, 특히 이미지 디코더에서 90%를 차지합니다. 이 연구는 3 × 3 커널 컨볼루션에서 다양한 타일 크기로 Winograd를 사용할 때의 잠재적 이점을 탐색하기 위해 이 현상에 대한 심층 분석을 제공합니다. 연구 결과에 따르면 타일 크기 4 × 4가 계산 효율성과 메모리 활용도 간의 최상의 균형을 제공하므로 최적인 것으로 나타났습니다.
이 연구는 Samsung S23 Ultra(Adreno 740) 및 iPhone 14 Pro Max(A16) 등 다양한 기기에서 벤치마킹되었습니다. 벤치마크 결과는 아래 표 1과 같습니다.
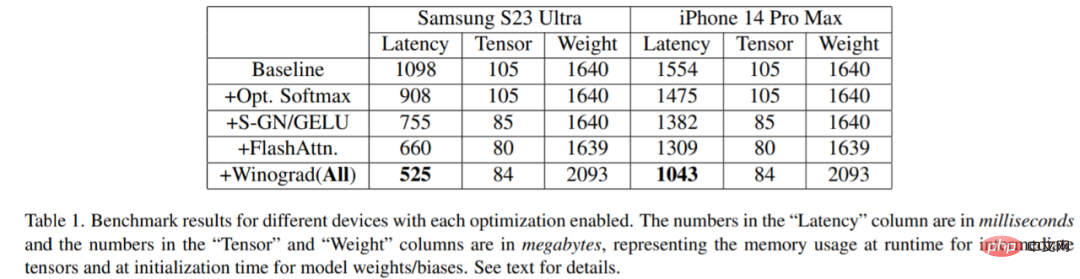
각 최적화가 활성화될 때마다 지연 시간이 점차 감소하는 것은 분명합니다(이미지 생성 시간이 감소하는 것으로 이해 가능). 구체적으로 기준선과 비교하면 Samsung S23 Ultra의 대기 시간은 52.2% 감소하고 iPhone 14 Pro Max의 대기 시간은 32.9% 감소합니다. 또한 이 연구에서는 20번의 잡음 제거 반복 단계 내에서 512×512 픽셀 이미지를 생성하여 12초 이내에 SOTA 결과를 달성하는 Samsung S23 Ultra의 종단 간 대기 시간도 평가합니다.
소형 장치는 자체 생성 AI 모델을 실행할 수 있습니다. 이는 미래에 무엇을 의미할까요? 우리는 파도를 기대할 수 있습니다.
위 내용은 Google은 확산 모델을 최적화하고 있습니다. 삼성 휴대폰은 Stable Diffusion을 실행하고 12초 안에 이미지를 생성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!