



ICLR(International Conference on Learning Representation)은 머신러닝 분야에서 가장 영향력 있는 국제 학술 컨퍼런스 중 하나로 인정받고 있습니다.
올해 ICLR 2023 컨퍼런스에서 Microsoft Research Asia는 기계 학습 견고성, 책임 있는 인공 지능 및 기타 분야의 최신 연구 결과를 발표했습니다.
그 중 마이크로소프트 리서치 아시아(Microsoft Research Asia)와 한국과학기술원(KAIST)이 양 기관의 학술 협력 프레임워크 하에 진행한 과학 연구 협력 성과는 탁월한 명확성, 통찰력, 창의성 및 잠재적으로 지속적인 영향을 미치는 에세이 상.

논문 주소: https://arxiv.org/abs/2303.14969
VTM: 모든 밀집 예측 작업에 적합한 최초의 소수 샘플 학습자
밀집 예측 작업은 컴퓨터 비전입니다. 의미론적 분할, 깊이 추정, 가장자리 탐지, 핵심 지점 탐지 등과 같은 현장의 중요한 작업 클래스입니다. 이러한 작업의 경우 픽셀 수준 라벨을 수동으로 주석 처리하는 데는 엄청난 비용이 듭니다. 따라서 적은 양의 라벨링된 데이터를 어떻게 학습하여 정확한 예측을 할 수 있는지, 즉 작은 표본 학습(Small Sample Learning)이 이 분야에서는 큰 관심사입니다. 최근 몇 년 동안 소규모 표본 학습에 대한 연구는 계속해서 획기적인 발전을 이루었으며, 특히 메타 학습 및 적대적 학습을 기반으로 한 일부 방법은 학계에서 많은 관심과 환영을 받았습니다.
그러나 기존 컴퓨터 비전 소표본 학습 방법은 일반적으로 분류 작업이나 의미론적 분할 작업과 같은 특정 유형의 작업을 목표로 합니다. 모델 아키텍처 및 교육 프로세스를 설계할 때 이러한 작업과 관련된 사전 지식과 가정을 활용하는 경우가 많으므로 임의의 조밀한 예측 작업에 대한 일반화에는 적합하지 않습니다. Microsoft Research Asia의 연구원들은 소수의 레이블이 지정된 이미지에서 보이지 않는 이미지의 임의 세그먼트에 대한 밀집된 예측 작업을 학습할 수 있는 일반적인 소수의 학습자가 있는지 여부라는 핵심 질문을 탐구하고 싶었습니다.
밀도 예측 작업의 목표는 입력 이미지에서 픽셀 단위로 주석이 달린 레이블로의 매핑을 학습하는 것입니다. 이는 다음과 같이 정의할 수 있습니다.
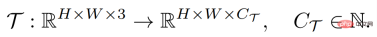
여기서 H와 W는 이미지의 높이와 너비입니다. 각각, 입력 이미지에는 일반적으로 3개의 RGB 채널이 포함되며, C_Τ는 출력 채널의 수를 나타냅니다. 서로 다른 밀집 예측 작업에는 서로 다른 출력 채널 번호 및 채널 속성이 포함될 수 있습니다. 예를 들어 의미론적 분할 작업의 출력은 다중 채널 이진인 반면 깊이 추정 작업의 출력은 단일 채널 연속 값입니다. 그러한 작업 Τ에 대해 일반적인 소수 샘플 학습기 F는 소수의 레이블이 지정된 샘플 지원 세트 S_Τ(샘플 X^i 및 레이블 Y^i의 N 그룹 포함)가 주어지면 보이지 않는 이미지 아키텍처 쿼리에 대해 학습할 수 있습니다. 이 구조는 임의로 조밀한 예측 작업을 처리할 수 있으며 일반화 가능한 지식을 얻기 위해 대부분의 작업에 필요한 매개변수를 공유하므로 적은 수의 샘플로 보이지 않는 작업을 학습할 수 있습니다.
 둘째, 학습자는 과적합을 방지할 수 있을 만큼 효율적이면서 다양한 의미론으로 보이지 않는 작업을 해결하기 위해 예측 메커니즘을 유연하게 조정해야 합니다.
둘째, 학습자는 과적합을 방지할 수 있을 만큼 효율적이면서 다양한 의미론으로 보이지 않는 작업을 해결하기 위해 예측 메커니즘을 유연하게 조정해야 합니다.
따라서 Microsoft Research Asia의 연구원들은 모든 조밀한 예측 작업에 사용할 수 있는 소표본 학습자 시각적 토큰 매칭 VTM(Visual Token Matching)을 설계하고 구현했습니다. 이것은 모든 집중 예측 작업에 적용되는
- 최초의 소표본 학습자
- 입니다. VTM은 컴퓨터 비전의 집중 예측 작업 및 소표본 학습 방법을 처리하는 데 새로운 사고 방식을 열어줍니다. 이 작품은 ICLR 2023 우수 논문상 을 수상했습니다.
VTM의 디자인은 인간의 사고 과정과의 유추에서 영감을 얻었습니다. 새로운 작업에 대한 소수의 예가 주어지면 인간은 예 간의 유사성을 기반으로 유사한 입력에 유사한 출력을 빠르게 할당할 수 있으며 유사한 출력을 할당할 수도 있습니다. 예제 간의 유사성을 기반으로 유사한 입력에 대한 컨텍스트는 입력과 출력이 유사한 수준에서 조정됩니다. 연구원들은 패치 수준을 기반으로 한 비모수적 매칭을 사용하여 조밀한 예측을 위한 유추 프로세스를 구현했습니다. 훈련을 통해 모델은 이미지 패치의 유사성을 포착하도록 영감을 받습니다.
새로운 작업에 대한 소수의 레이블이 지정된 예제가 주어지면 VTM은 먼저 주어진 예제와 예제의 레이블을 기반으로 유사성에 대한 이해를 조정하고 이미지와 유사한 예제 이미지 패치에서 이미지 패치를 잠급니다. 예측할 패치, 레이블을 결합하여 보이지 않는 이미지 패치의 레이블을 예측합니다.

그림 1: VTM의 전체 아키텍처
VTM은 계층화된 인코더-디코더 아키텍처를 채택하여 여러 레벨의 이미지 블록을 기반으로 하는 비모수적 일치를 달성합니다. 이는 주로 이미지 인코더 f_Τ, 라벨 인코더 g, 매칭 모듈 및 라벨 디코더 h의 네 가지 모듈로 구성됩니다. 쿼리 이미지와 지원 세트가 주어지면 이미지 인코더는 먼저 각 쿼리에 대한 이미지 패치 수준 표현을 추출하고 이미지를 독립적으로 지원합니다. 태그 인코더는 태그를 지원하는 각 태그를 유사하게 추출합니다. 각 레벨의 레이블이 주어지면 일치 모듈은 비모수적 일치를 수행하고 레이블 디코더는 최종적으로 쿼리 이미지의 레이블을 추론합니다.
VTM의 핵심은 메타러닝 방식입니다. 훈련은 여러 에피소드로 구성되며, 각 에피소드는 작은 샘플 학습 문제를 시뮬레이션합니다. VTM 교육은 밀집된 예측 작업의 다양한 레이블이 지정된 예가 포함된 메타 교육 데이터 세트 D_train을 사용합니다. 각 훈련 에피소드는 지원 세트가 제공된 쿼리 이미지에 대한 올바른 레이블을 생성하는 것을 목표로 데이터 세트의 특정 작업 T_train에 대한 몇 번의 학습 시나리오를 시뮬레이션합니다. 여러 개의 작은 샘플을 통해 학습한 경험을 통해 모델은 새로운 작업에 빠르고 유연하게 적응할 수 있는 일반 지식을 학습할 수 있습니다. 테스트 시 모델은 훈련 데이터 세트 D_train에 포함되지 않은 모든 작업 T_test에 대해 소수 학습을 수행해야 합니다.
임의의 작업을 처리할 때 메타 훈련과 테스트에서 각 작업의 출력 차원 C_Τ가 다르기 때문에 모든 작업에 대해 통일된 일반 모델 매개 변수를 설계하는 것이 큰 과제가 됩니다. 간단하고 일반적인 솔루션을 제공하기 위해 연구자들은 작업을 C_Τ 단일 채널 하위 작업으로 변환하고 각 채널을 별도로 학습한 다음 공유 모델 F를 사용하여 각 하위 작업을 독립적으로 모델링했습니다.
VTM을 테스트하기 위해 연구원들은 또한 보이지 않는 조밀한 예측 작업에 대한 소규모 샘플 학습을 시뮬레이션하기 위해 Taskonomy 데이터 세트의 변형을 특별히 구성했습니다. Taskonomy에는 주석이 달린 다양한 실내 이미지가 포함되어 있으며, 이 중에서 연구원은 의미론과 출력 차원이 서로 다른 10개의 밀집된 예측 작업을 선택하고 교차 검증을 위해 이를 5개 부분으로 나눴습니다. 각 분할에서 2개의 작업은 소규모 평가(T_test)에 사용되고 나머지 8개의 작업은 훈련(T_train)에 사용됩니다. 연구원들은 새로운 의미론을 사용하여 작업을 평가할 수 있도록 에지 작업(TE, OE)을 테스트 작업으로 그룹화하는 등 교육 작업과 테스트 작업이 서로 충분히 다르도록 파티션을 신중하게 구성했습니다.
표 1: Taskonomy 데이터 세트(Few-shot 기준선)에 대한 정량적 비교 후 테스트할 파티션 작업에 대해 10샷 학습이 수행되었으며, 여기서 완전 감독 기준선이 훈련되었습니다. 각 접기(DPT) 또는 모든 접기(InvPT)에 대해 평가됩니다.
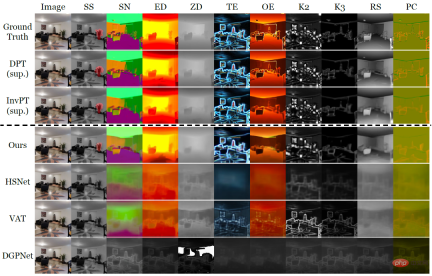
표 1과 그림 2는 각각 10개의 밀집된 예측 작업에 대한 VTM의 소표본 학습 성능과 두 가지 유형의 기준 모델을 정량적 및 정성적으로 보여줍니다. 그 중 DPT와 InvPT는 가장 발전된 두 가지 지도 학습 방법으로, DPT는 각 단일 작업에 대해 독립적으로 훈련할 수 있는 반면, InvPT는 모든 작업을 공동으로 훈련할 수 있습니다. VTM 이전에는 일반적인 조밀한 예측 작업을 위해 개발된 전용 소표본 방법이 없었기 때문에 연구원들은 VTM을 세 가지 최첨단 소표본 분할 방법, 즉 DGPNet, HSNet 및 VAT와 비교하고 일반 예측 작업을 처리하도록 확장했습니다. 밀집된 예측 작업을 위한 레이블 공간. VTM은 훈련 중에 테스트 작업 T_test에 액세스할 수 없었고 테스트 시 적은 수(10)의 레이블이 지정된 이미지만 사용했지만 모든 소규모 기준 모델 중에서 가장 잘 수행되었으며 전체 작업에 비해 많은 경쟁에서 좋은 성능을 보였습니다. 감독 기준 모델.
그림 2: Taskonomy의 10가지 조밀한 예측 작업에 대해 단 10개의 레이블이 지정된 이미지를 사용하여 새로운 작업에 대한 소수 학습 방법의 질적 비교. 다른 방법이 실패한 경우 VTM은 다양한 의미와 라벨 표현을 사용하여 모든 새로운 작업을 성공적으로 학습했습니다.
그림 2에서 점선 위에는 실제 레이블과 두 가지 지도 학습 방법 DPT 및 InvPT가 각각 있습니다. 점선 아래에는 작은 샘플 학습 방법이 있습니다. 특히, 다른 소규모 표본 기준선은 새로운 작업에 대해 심각한 과소적합을 겪었지만 VTM은 모든 작업을 성공적으로 학습했습니다. 실험에 따르면 이제 VTM은 매우 적은 수의 라벨이 지정된 예(
요약하자면, VTM의 기본 아이디어는 매우 간단하지만 VTM은 임의의 조밀한 예측 작업에 사용할 수 있는 통합 아키텍처를 가지고 있습니다. 왜냐하면 일치 알고리즘은 본질적으로 모든 작업과 레이블 구조를 포함하기 때문입니다(예: 연속 또는 이산). 또한 VTM은 소수의 작업별 매개변수만 도입하여 과적합에 대한 저항성과 유연성을 제공합니다. 앞으로 연구자들은 사전 훈련 과정에서 작업 유형, 데이터 양, 데이터 분포가 모델 일반화 성능에 미치는 영향을 더 자세히 조사하여 진정한 보편적인 소표본 학습자를 구축하는 데 도움이 되기를 희망합니다.


위 내용은 범용 퓨샷 학습자: 광범위한 집중 예측 작업을 위한 솔루션의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 AI 내부 배포의 숨겨진 위험 : 거버넌스 격차 및 치명적인 위험Apr 28, 2025 am 11:12 AM
AI 내부 배포의 숨겨진 위험 : 거버넌스 격차 및 치명적인 위험Apr 28, 2025 am 11:12 AMApollo Research의 새로운 보고서에 따르면 고급 AI 시스템의 점검되지 않은 내부 배치는 상당한 위험을 초래합니다. 주요 AI 기업들 사이에서 널리 퍼져있는 이러한 감독 부족은 uncont에서 범위에 이르는 잠재적 인 치명적인 결과를 허용합니다.
 AI Polygraph 구축Apr 28, 2025 am 11:11 AM
AI Polygraph 구축Apr 28, 2025 am 11:11 AM전통적인 거짓말 탐지기는 구식입니다. 손목 대역으로 연결된 포인터에 의존하는 것은 대상의 활력 징후와 물리적 반응을 인쇄하는 거짓말 탐지기가 거짓말을 식별하는 데 정확하지 않습니다. 그렇기 때문에 거짓말 탐지 결과는 일반적으로 법원에서 채택되지는 않지만 많은 무고한 사람들이 감옥에 갇히게되었습니다. 대조적으로, 인공 지능은 강력한 데이터 엔진이며, 작동 원리는 모든 측면을 관찰하는 것입니다. 이것은 과학자들이 다양한 방식으로 진실을 찾는 응용 분야에 인공 지능을 적용 할 수 있음을 의미합니다. 한 가지 방법은 거짓말 탐지기처럼 심문을받는 사람의 중요한 부호 반응을 분석하지만보다 상세하고 정확한 비교 분석을 분석하는 것입니다. 또 다른 방법은 언어 마크 업을 사용하여 사람들이 실제로 말하는 것을 분석하고 논리와 추론을 사용하는 것입니다. 말이 갈 때, 한 거짓말은 또 다른 거짓말을 번식시키고 결국
 항공 우주 산업에서 AI가 이륙을 위해 청산 되었습니까?Apr 28, 2025 am 11:10 AM
항공 우주 산업에서 AI가 이륙을 위해 청산 되었습니까?Apr 28, 2025 am 11:10 AM혁신의 선구자 인 항공 우주 산업은 AI를 활용하여 가장 복잡한 도전을 해결하고 있습니다. Modern Aviation의 복잡성 증가는 AI의 자동화 및 실시간 인텔리전스 기능이 필요합니다.
 베이징의 봄 로봇 레이스를보고 있습니다Apr 28, 2025 am 11:09 AM
베이징의 봄 로봇 레이스를보고 있습니다Apr 28, 2025 am 11:09 AM로봇 공학의 빠른 발전은 우리에게 매혹적인 사례 연구를 가져 왔습니다. Noetix의 N2 로봇의 무게는 40 파운드가 넘고 키가 3 피트이며 백 플립을 할 수 있다고합니다. Unitree의 G1 로봇의 무게는 N2 크기의 약 2 배이며 키는 약 4 피트입니다. 경쟁에 참여하는 작은 휴머노이드 로봇도 많으며 팬이 앞으로 나아가는 로봇도 있습니다. 데이터 해석 하프 마라톤은 12,000 명 이상의 관중을 끌어 들였지만 21 명의 휴머노이드 로봇 만 참여했습니다. 정부는 참여 로봇이 경쟁 전에 "집중 훈련"을 수행했다고 지적했지만 모든 로봇이 전체 경쟁을 완료 한 것은 아닙니다. 챔피언 -Tiangong Ult Beijing Humanoid Robot Innovation Center가 개발했습니다.
 거울 함정 : AI 윤리와 인간 상상력의 붕괴Apr 28, 2025 am 11:08 AM
거울 함정 : AI 윤리와 인간 상상력의 붕괴Apr 28, 2025 am 11:08 AM인공 지능은 현재 형태로 진정으로 지능적이지 않습니다. 기존 데이터를 모방하고 정제하는 데 능숙합니다. 우리는 인공 지능을 만들지 않고 오히려 인공적인 추론을 만들고 있습니다.
 새로운 Google Leak은 Handy Google 사진 기능 업데이트가 공개됩니다Apr 28, 2025 am 11:07 AM
새로운 Google Leak은 Handy Google 사진 기능 업데이트가 공개됩니다Apr 28, 2025 am 11:07 AM보고서에 따르면 Google Photos Android 버전 7.26 코드에 업데이트 된 인터페이스가 숨겨져 있으며 사진을 볼 때마다 새로 감지 된 얼굴 썸네일 행이 화면 하단에 표시됩니다. 새로운 얼굴 썸네일에는 이름 태그가 없으므로 탐지 된 각 사람에 대한 자세한 정보를 보려면 개별적으로 클릭해야한다고 생각합니다. 현재이 기능은 Google 사진이 이미지에서 찾은 사람들 외에는 정보를 제공하지 않습니다. 이 기능은 아직 사용할 수 없으므로 Google이 어떻게 정확하게 사용할 것인지 모릅니다. Google은 썸네일을 사용하여 선택된 사람들의 더 많은 사진을 찾는 속도를 높이거나 편집 할 개인을 선택하는 것과 같은 다른 목적으로 사용될 수 있습니다. 기다렸다가 보자. 지금은
 강화 조정 안내서 - 분석 VidhyaApr 28, 2025 am 09:30 AM
강화 조정 안내서 - 분석 VidhyaApr 28, 2025 am 09:30 AM강화 결합은 인간의 피드백을 기반으로 조정하도록 모델을 가르치면서 AI 개발을 흔들었다. 감독 학습 기초가 보상 기반 업데이트와 혼합되어 더 안전하고 정확하며 진정으로 도움을줍니다.
 Let 's Dance : 인간 신경 그물을 미세 조정하기위한 구조화 된 움직임Apr 27, 2025 am 11:09 AM
Let 's Dance : 인간 신경 그물을 미세 조정하기위한 구조화 된 움직임Apr 27, 2025 am 11:09 AM과학자들은 C. el 그러나 중요한 질문이 발생합니다. 새로운 AI S와 함께 효과적으로 작동하도록 우리 자신의 신경망을 어떻게 조정합니까?


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

