
Python으로 문서 스캐너를 구축하는 방법은 무엇입니까?

- 王林앞으로
- 2023-04-26 13:10:111852검색
번역가 | Bugatti
Reviewer | Sun Shujuan
문서를 디지털화하여 물리적 공간을 절약하거나 백업을 만들 수 있습니다. 어쨌든, 종이 문서의 사진을 준포맷으로 변환하는 프로그램을 작성하는 것이 바로 Python이 잘하는 일입니다.
여러 적절한 라이브러리의 조합을 사용하면 문서를 디지털화하는 작은 애플리케이션을 구축할 수 있습니다. 프로그램은 실제 문서의 이미지를 입력으로 가져와 여러 이미지 처리 기술을 적용하고 입력 내용의 스캔 버전을 출력합니다.
1. 환경을 준비하세요
먼저 Python의 기본을 숙지하고 NumPy Python 라이브러리를 사용할 줄도 알아야 합니다.
Python IDE를 열고 두 개의 Python 파일을 만듭니다. 하나의 이름을 main.py로 지정하고 다른 하나의 이름을Transform.py로 지정합니다. 그런 다음 터미널에서 다음 명령을 실행하여 필요한 라이브러리를 설치하십시오.
pip install OpenCV-Python imutils scikit-image NumPy
OpenCV-Python을 사용하여 이미지를 입력하고 일부 이미지 처리를 수행하고, Imutils를 사용하여 입력 및 출력 이미지 크기를 조정하고, scikit-image를 사용하여 이미지 임계값을 지정합니다. NumPy가 배열에 도움을 줄 것입니다.
설치가 완료되고 IDE가 프로젝트 백본을 업데이트할 때까지 기다립니다. 백본 콘텐츠가 업데이트되면 프로그래밍을 시작할 수 있습니다. 전체 소스 코드는 GitHub 저장소에서 찾을 수 있습니다.
2. 설치된 라이브러리 가져오기
main.py 파일을 열고 설치된 라이브러리를 가져옵니다. 이를 통해 필요할 때 해당 기능을 호출하고 사용할 수 있습니다.
import cv2 import imutils from skimage.filters import threshold_local from transform import perspective_transform
spective_transform에서 발생하는 오류를 무시합니다. 변환.py 파일 처리가 완료되면 오류가 사라집니다.
3. 입력 가져오기 및 크기 조정
스캔하려는 문서의 선명한 이미지를 찍습니다. 문서의 네 모서리와 내용이 모두 보이는지 확인하세요. 프로그램 파일이 저장된 동일한 폴더에 이미지를 복사하십시오.

입력 이미지 경로를 OpenCV에 전달합니다. 원근 변환 중에 필요할 것이므로 원본 이미지의 복사본을 만드십시오. 원본 이미지의 높이를 크기를 조정하려는 높이로 나눕니다. 이렇게 하면 종횡비가 유지됩니다. 마지막으로 조정된 이미지가 출력됩니다.
# Passing the image path
original_img = cv2.imread('sample.jpg')
copy = original_img.copy()
# The resized height in hundreds
ratio = original_img.shape[0] / 500.0
img_resize = imutils.resize(original_img, height=500)
# Displaying output
cv2.imshow('Resized image', img_resize)
# Waiting for the user to press any key
cv2.waitKey(0)
위 코드의 출력은 다음과 같습니다.
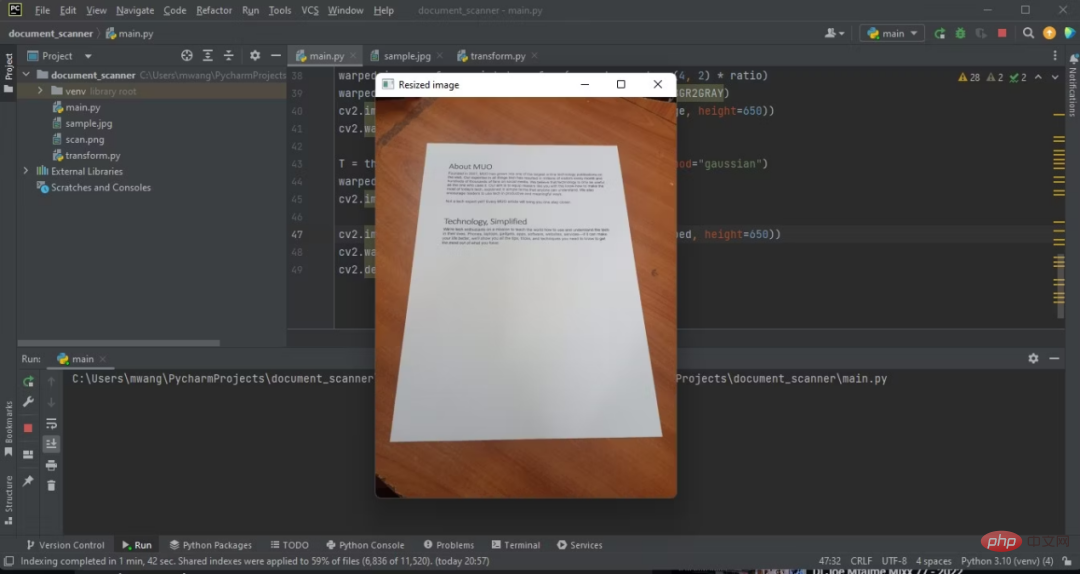
이제 원본 이미지의 높이를 500픽셀로 조정했습니다.
4. 조정된 이미지를 회색조 이미지로 변환
조정된 RGB 이미지를 회색조 이미지로 변환합니다. 대부분의 이미지 처리 라이브러리는 처리하기 쉽기 때문에 회색조 이미지만 처리합니다.
gray_image = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayed Image', gray_image)
cv2.waitKey(0)
원본 이미지와 회색조 이미지의 차이점을 확인하세요.
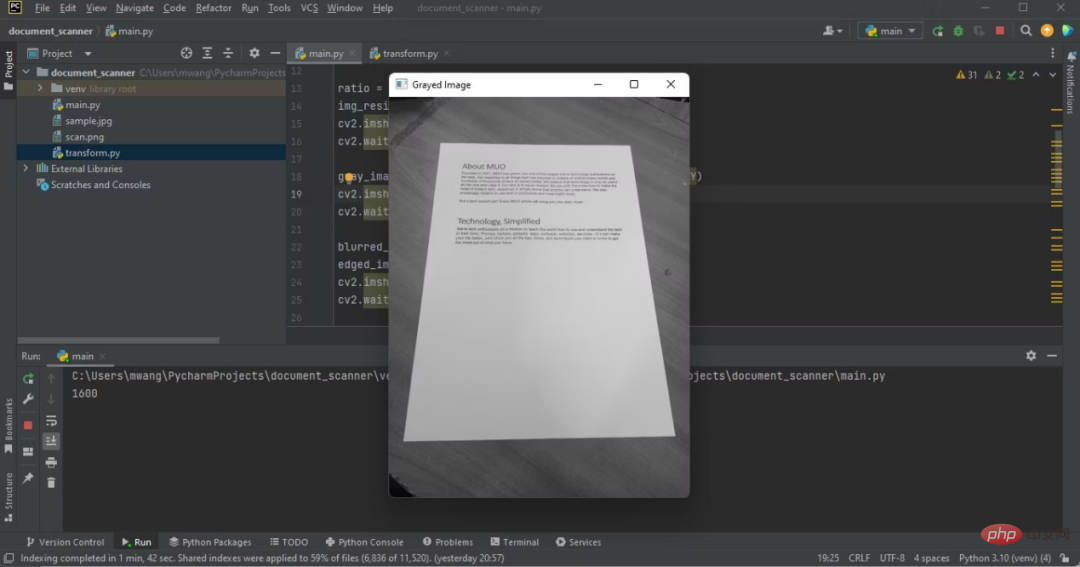
IDE에서 회색 이미지를 보여주는 프로그램 출력
컬러 테이블이 흑백 테이블로 바뀌었습니다.
5. 가장자리 감지기 사용
회색조 이미지에 가우시안 흐림 필터를 적용하여 노이즈를 제거합니다. 그런 다음 OpenCV canny 함수가 호출되어 이미지에 있는 가장자리를 감지합니다.
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
edged_img = cv2.Canny(blurred_image, 75, 200)
cv2.imshow('Image edges', edged_img)
cv2.waitKey(0)
가장자리가 출력물에 표시됩니다.
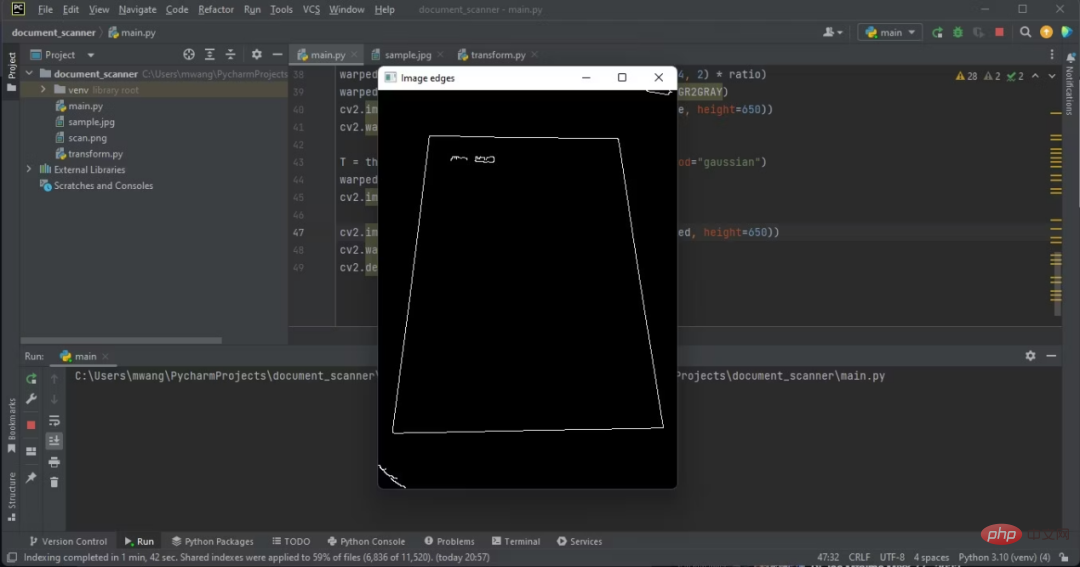
작업할 가장자리는 문서의 가장자리입니다.
6. 가장 큰 윤곽선 찾기
가장자리 이미지에서 윤곽선을 감지합니다. 가장 큰 5개의 윤곽선만 유지하면서 내림차순으로 정렬합니다. 윤곽선을 주기적으로 정렬하면 가장 큰 4면 윤곽선이 대략적으로 얻어집니다.
cnts, _ = cv2.findContours(edged_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5] for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) if len(approx) == 4: doc = approx break
사면이 있는 실루엣은 문서를 담을 가능성이 높습니다.
7. 문서 개요의 네 모서리에 동그라미를 칩니다.
감지된 문서 개요의 여러 모서리에 동그라미를 칩니다. 이는 프로그램이 이미지에서 문서를 감지할 수 있는지 확인하는 데 도움이 됩니다.
p = []
for d in doc:
tuple_point = tuple(d[0])
cv2.circle(img_resize, tuple_point, 3, (0, 0, 255), 4)
p.append(tuple_point)
cv2.imshow('Circled corner points', img_resize)
cv2.waitKey(0)
조정된 RGB 이미지의 몇 모서리에 원을 그리세요.
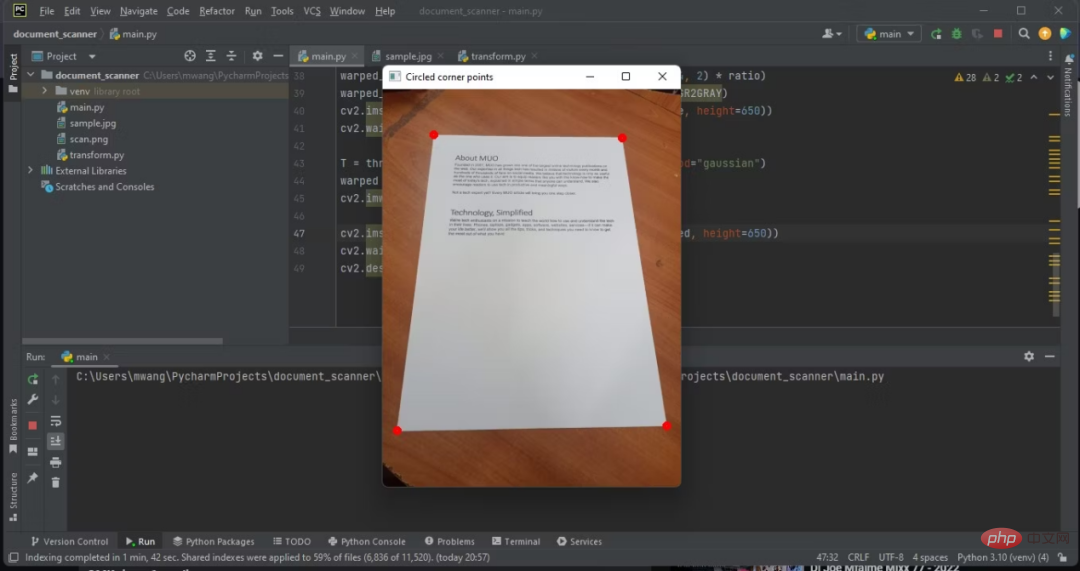
문서를 감지한 후 이제 이미지에서 문서를 추출해야 합니다.
8. 원하는 이미지를 얻으려면 뒤틀린 원근법을 사용하세요
뒤틀린 원근법은 왜곡을 교정하기 위해 이미지를 변환하는 데 사용되는 컴퓨터 비전 기술입니다. 이미지를 다른 평면으로 변환하여 다른 각도에서 이미지를 볼 수 있습니다.
warped_image = perspective_transform(copy, doc.reshape(4, 2) * ratio)
warped_image = cv2.cvtColor(warped_image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Warped Image", imutils.resize(warped_image, height=650))
cv2.waitKey(0)
왜곡된 이미지를 얻으려면 원근 변환을 수행하는 간단한 모듈을 만들어야 합니다.
9. 변환 모듈
该模块将对文档角的点进行排序。它还会将文档图像转换成不同的平面,并将相机角度更改为俯拍。
打开之前创建的那个transform.py文件,导入OpenCV库和NumPy库。
import numpy as np import cv2
这个模块将含有两个函数。创建一个对文档角点的坐标进行排序的函数。第一个坐标将是左上角的坐标,第二个将是右上角的坐标,第三个将是右下角的坐标,第四个将是左下角的坐标。
def order_points(pts): # initializing the list of coordinates to be ordered rect = np.zeros((4, 2), dtype = "float32") s = pts.sum(axis = 1) # top-left point will have the smallest sum rect[0] = pts[np.argmin(s)] # bottom-right point will have the largest sum rect[2] = pts[np.argmax(s)] '''computing the difference between the points, the top-right point will have the smallest difference, whereas the bottom-left will have the largest difference''' diff = np.diff(pts, axis = 1) rect[1] = pts[np.argmin(diff)] rect[3] = pts[np.argmax(diff)] # returns ordered coordinates return rect
创建将计算新图像的角坐标,并获得俯拍的第二个函数。然后,它将计算透视变换矩阵,并返回扭曲的图像。
def perspective_transform(image, pts): # unpack the ordered coordinates individually rect = order_points(pts) (tl, tr, br, bl) = rect '''compute the width of the new image, which will be the maximum distance between bottom-right and bottom-left x-coordinates or the top-right and top-left x-coordinates''' widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) maxWidth = max(int(widthA), int(widthB)) '''compute the height of the new image, which will be the maximum distance between the top-left and bottom-left y-coordinates''' heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) maxHeight = max(int(heightA), int(heightB)) '''construct the set of destination points to obtain an overhead shot''' dst = np.array([ [0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype = "float32") # compute the perspective transform matrix transform_matrix = cv2.getPerspectiveTransform(rect, dst) # Apply the transform matrix warped = cv2.warpPerspective(image, transform_matrix, (maxWidth, maxHeight)) # return the warped image return warped
现在您已创建了转换模块。perspective_transform导入方面的错误现在将消失。
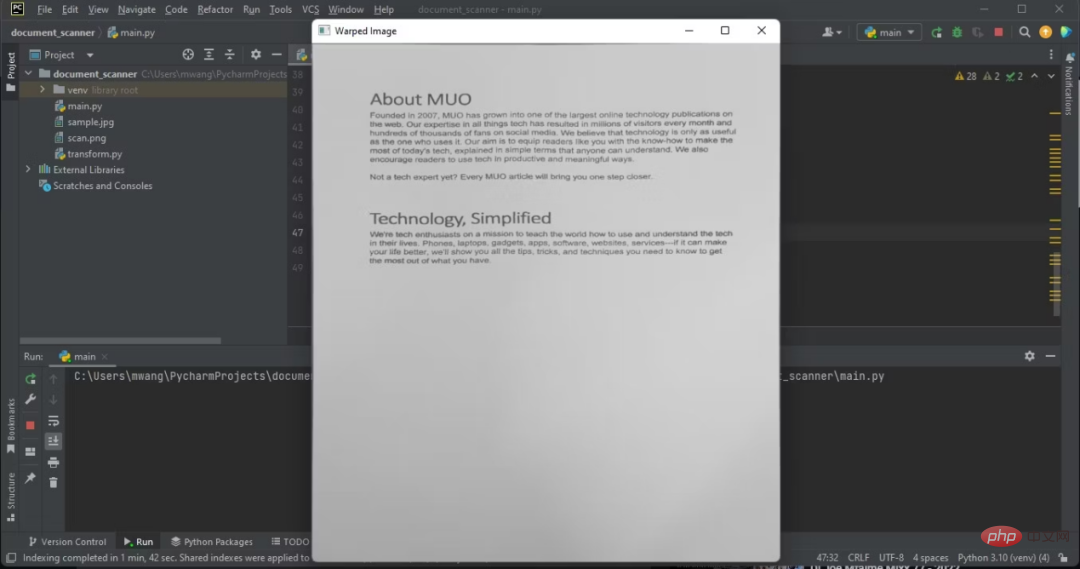
注意,显示的图像有俯拍。
10、运用自适应阈值,保存扫描输出
在main.py文件中,对扭曲的图像运用高斯阈值。这将给扭曲的图像一个扫描后的外观。将扫描后的图像输出保存到含有程序文件的文件夹中。
T = threshold_local(warped_image, 11, offset=10, method="gaussian")
warped = (warped_image > T).astype("uint8") * 255
cv2.imwrite('./'+'scan'+'.png',warped)
以PNG格式保存扫描件可以保持文档质量。
11、显示输出
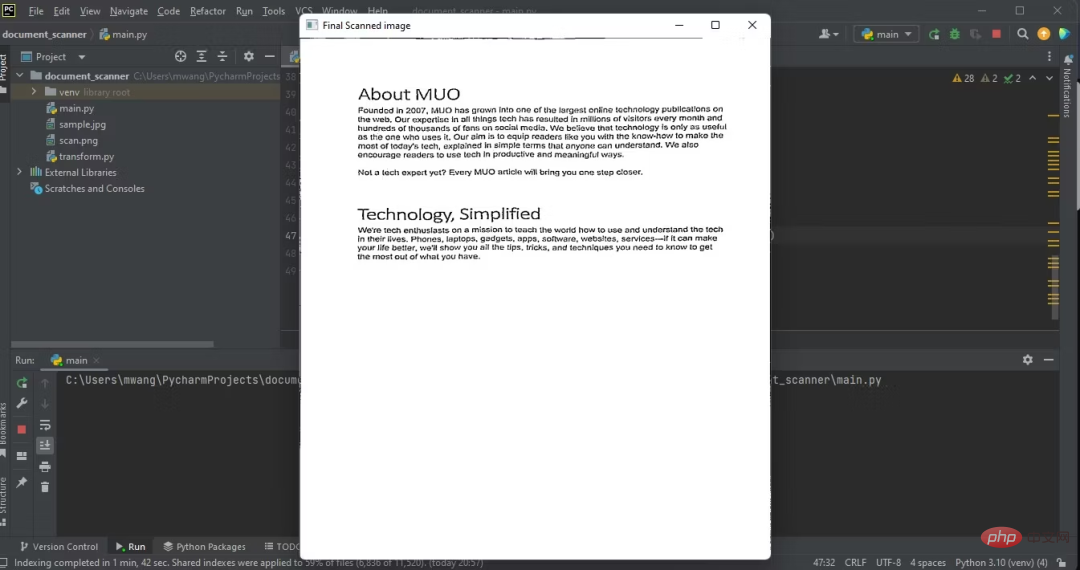
输出扫描后文档的图像:
cv2.imshow("Final Scanned image", imutils.resize(warped, height=650))
cv2.waitKey(0)
cv2.destroyAllWindows()
下图显示了程序的输出,即扫描后文档的俯拍。
12、计算机视觉在如何进步?
创建文档扫描器涉及计算机视觉的一些核心领域,计算机视觉是一个广泛而复杂的领域。为了在计算机视觉方面取得进步,您应该从事有趣味又有挑战性的项目。
您还应该阅读如何将计算机视觉与当前前技术结合使用方面的更多信息。这让您能了解情况,并为所处理的项目提供新的想法。
原文链接:https://www.makeuseof.com/python-create-document-scanner/
위 내용은 Python으로 문서 스캐너를 구축하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!