
고품질 언어 데이터의 전 세계 재고는 부족하며 무시할 수 없습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-26 11:37:071574검색
인공지능의 3대 요소 중 하나로 데이터가 중요한 역할을 합니다.
하지만 혹시 어느 날 세상의 모든 데이터가 고갈된다면 어떻게 될까요?
사실 이 질문을 하신 분은 정신적인 문제가 없는 게 분명합니다. 왜냐하면 오늘이 곧 올 수도 있으니까요! ! !
최근 파블로 빌라로보스(Pablo Villalobos) 연구원 등이 "데이터가 부족해질까?"라는 제목의 글을 게재했습니다. arXiv에 "Analytics of the Limitations of Dataset Scaling in Machine Learning" 논문이 게재되었습니다.
이전의 데이터 세트 크기 추세 분석을 바탕으로 언어 및 비전 분야의 데이터 세트 크기 증가를 예측하고 향후 수십 년 동안 사용 가능한 레이블이 없는 데이터의 총 재고 개발 추세를 추정했습니다.
그들의 연구에 따르면 고품질 언어 데이터는 빠르면 2026년에 고갈될 것입니다! 결과적으로 머신러닝 개발 속도도 느려질 것입니다. 정말 낙관적이지 않습니다.
두 가지 방법을 함께 사용했지만 결과가 낙관적이지 않음
본 논문의 연구팀은 11명의 연구원과 3명의 컨설턴트로 구성되어 있으며, 전 세계에서 구성원으로 구성되어 AI 기술 개발과 AI 기술 간의 격차를 줄이기 위해 최선을 다하고 있습니다. AI 전략 및 제공 AI 안전과 관련된 주요 의사결정자에게 조언을 제공합니다.

Chinchilla는 DeepMind 연구원들이 제안한 새로운 예측 컴퓨팅 최적화 모델입니다.
실제로 이전에 Chinchilla에 대한 실험을 진행했을 때 한 연구원은 "훈련 데이터가 곧 대규모 언어 모델 확장에 병목 현상이 될 것"이라고 지적한 적이 있습니다.
그래서 그들은 자연어 처리 및 컴퓨터 비전을 위한 기계 학습 데이터 세트 크기의 증가를 분석하고 두 가지 방법을 사용하여 추정했습니다. 과거 성장률을 사용하고 미래 예측을 위한 계산 예산의 최적 추정치를 계산했습니다. 데이터 세트 크기.
이전에 그들은 일부 교육 데이터를 포함하여 기계 학습 입력 동향에 대한 데이터를 수집하고 향후 수십 년 동안 인터넷에서 사용할 수 있는 레이블이 없는 데이터의 총 재고를 추정하여 데이터 사용량 증가를 조사했습니다.
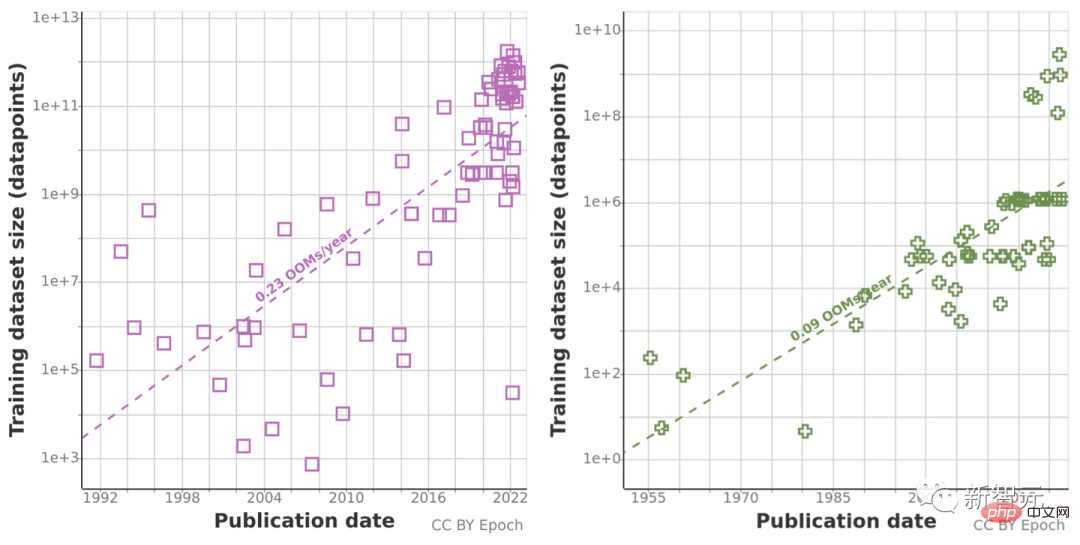
지난 10년간의 비정상적인 컴퓨팅량 증가로 인해 역사적 예측 추세가 '오도'할 수 있기 때문에 연구팀도 친칠라 스케일링 법칙을 사용하여 향후 몇 년간의 데이터 세트 크기를 추정했습니다. 계산 결과 성별의 정확성을 향상시킵니다.
궁극적으로 연구원들은 일련의 확률 모델을 사용하여 향후 몇 년간 영어 및 이미지 데이터의 전체 인벤토리를 추정하고 훈련 데이터 세트 크기와 전체 데이터 인벤토리에 대한 예측을 비교했습니다. 결과는 그림에 나와 있습니다. 아래에.
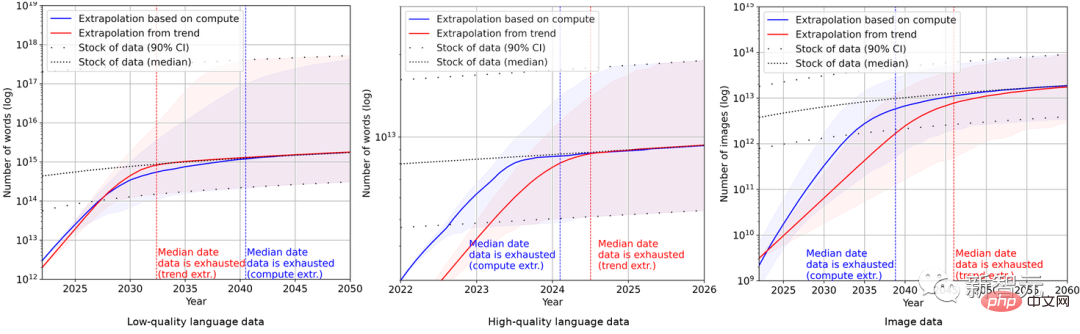
이는 데이터 세트의 증가 속도가 데이터 재고보다 훨씬 빠르다는 것을 보여줍니다.
따라서 현재의 추세가 계속된다면 데이터 재고가 소진되는 것은 불가피할 것입니다. 아래 표는 예측 곡선의 각 교차점에서 소진까지 걸리는 평균 연수를 보여줍니다.
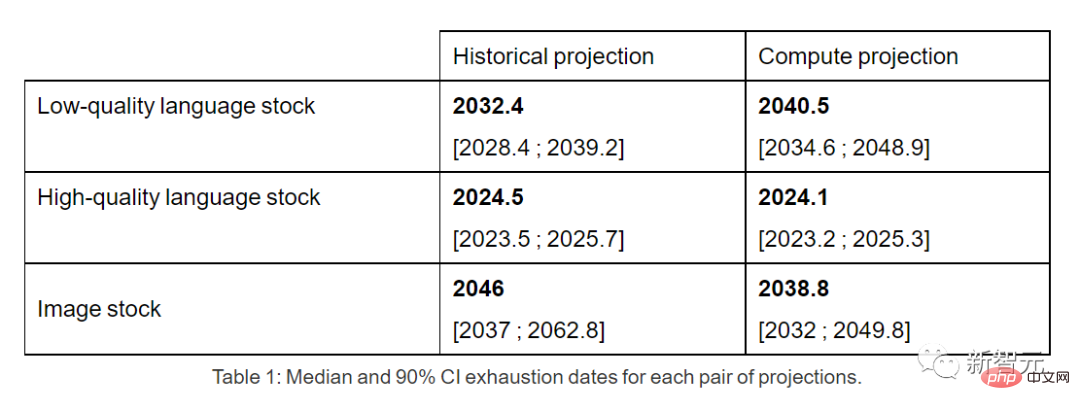
고품질 언어 데이터 인벤토리는 이르면 2026년에는 소진될 수 있습니다.
반면 품질이 낮은 언어 데이터와 이미지 데이터는 약간 더 좋습니다. 전자는 2030년에서 2050년 사이에, 후자는 2030년에서 2060년 사이에 소모됩니다.
논문 끝에서 연구팀은 데이터 효율성이 크게 향상되지 않거나 새로운 데이터 소스를 사용할 수 있다면 현재 계속해서 확장되는 거대한 데이터 세트에 의존하는 기계 학습 모델의 성장 추세가 둔화될 가능성이 높다는 결론을 내렸습니다. 아래에.
네티즌: 걱정하는 건 무리입니다. Efficient Zero에 대해 자세히 알아봅시다
그러나 이 글의 댓글란에는 대부분의 네티즌들이 글쓴이가 걱정할 만한 근거가 없다고 생각하고 있습니다.
Reddit에서 ktpr이라는 네티즌은 다음과 같이 말했습니다.
"자기 지도 학습이 뭐가 문제인가요? 작업을 잘 지정하면 결합하여 데이터 세트 크기를 늘릴 수도 있습니다.
 "
"
lostmsn이라는 네티즌은 더욱 무례했습니다. 그는 퉁명스럽게 말했습니다:
"Efficient Zero에 대해 모르시나요? 작성자가 정말 시대에 뒤떨어진 것 같아요."
Efficient Zero는 효율적으로 칭화대 Gao Yang 박사가 제안한 샘플입니다.
데이터량이 제한된 경우 Efficient Zero는 강화학습의 성능 문제를 어느 정도 해결했으며, 범용 알고리즘 테스트 벤치마크인 Atari Game에서 검증되었습니다.
본 논문의 저자 팀 블로그에서 그들도 다음과 같이 인정했습니다.
"우리의 모든 결론은 현재 머신러닝 데이터의 사용 및 생산에 대한 비현실적인 가정에 기초하고 있습니다. 추세 "
"더 안정적인 모델은 머신러닝 데이터 효율성 향상, 합성 데이터 사용, 기타 알고리즘 및 경제적 요인을 고려해야 합니다."
" 그래서 현실적으로 이 분석은 심각한 한계를 갖고 있습니다. 모델의 불확실성이 매우 높습니다."
"하지만 전체적으로는 훈련 데이터 부족으로 인해 2040년까지 확률이 20% 정도라고 생각합니다. 머신러닝 모델의 확장 속도가 크게 느려질 것입니다."
위 내용은 고품질 언어 데이터의 전 세계 재고는 부족하며 무시할 수 없습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!