
Java에서 Bloom 필터를 구현하는 방법

- 王林앞으로
- 2023-04-24 21:43:191740검색
BitMap
현대 컴퓨터는 정보의 기본 단위로 바이너리(비트)를 사용합니다. 예를 들어 big 문자열은 3바이트로 구성되지만 실제 컴퓨터에서는 big에 해당하는 ASCII 코드는 각각 98, 105, 103이고, 해당 바이너리 숫자는 각각 01100010, 01101001, 01100111입니다. big字符串是由 3 个字节组成,但实际在计算机存储时将其用二进制表示,big分别对应的 ASCII 码分别是 98、105、103,对应的二进制分别是 01100010、01101001 和 01100111。
许多开发语言都提供了操作位的功能,合理地使用位能够有效地提高内存使用率和开发效率。
Bit-map 的基本思想就是用一个 bit 位来标记某个元素对应的 value,而 key 即是该元素。由于采用了 bit 为单位来存储数据,因此在存储空间方面,可以大大节省。
在 Java 中,int 占 4 字节,1 字节 = 8位(1 byte = 8 bit),如果我们用这个 32 个 bit 位的每一位的值来表示一个数的话是不是就可以表示 32 个数字,也就是说 32 个数字只需要一个 int 所占的空间大小就可以了,那就可以缩小空间 32 倍。
1 Byte = 8 Bit,1 KB = 1024 Byte,1 MB = 1024 KB,1GB = 1024 MB
假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用集合类型和 BitMap 分别存储活跃用户:
1.假如用户 id 是 int 型,4 字节,32 位,则集合类型占据的空间为 50 000 000 * 4/1024/1024 = 200M;
2.如果按位存储,5 千万个数就是 5 千万位,占据的空间为 50 000 000/8/1024/1024 = 6M。
那么如何用 BitMap 来表示一个数呢?
上面说了用 bit 位来标记某个元素对应的 value,而 key 即是该元素,我们可以把 BitMap 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1(0 表示这个数不存在,1 表示存在),数组的下标在 BitMap 中叫做偏移量。比如我们需要表示{1,3,5,7}这四个数,如下:
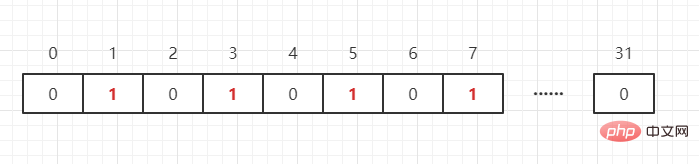
那如果还存在一个数 65 呢?只需要开int[N/32+1]个 int 数组就可以存储完这些数据(其中 N 表示这群数据中的最大值),即:
int[0]:可以表示 0~31
int[1]:可以表示 32~63
int[2]:可以表示 64~95
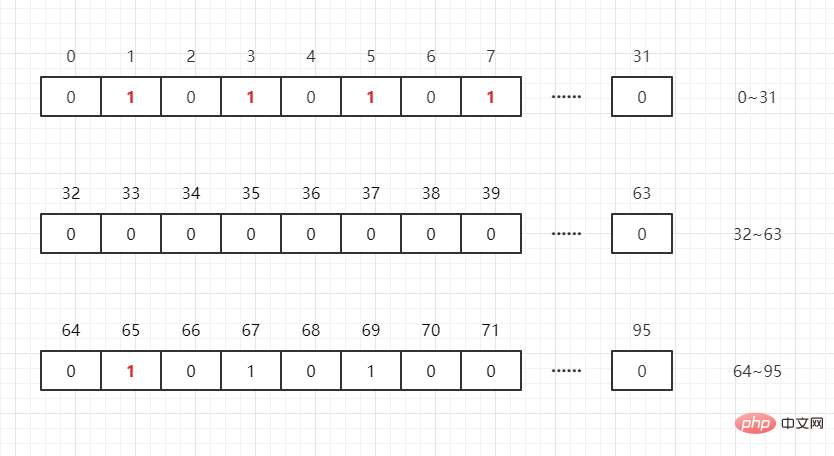
假设我们要判断任意整数是否在列表中,则 M/32 就得到下标,M%32就知道它在此下标的哪个位置,如:
65/32 = 2,65%32=1,即 65 在int[2]
1 Byte = 8 Bit, 1 KB = 1024 Byte, 1 MB = 1024 KB, 1GB = 1024 MB웹사이트의 사용자가 1억 명이고 순 사용자가 매일 5천만 명에 달한다고 가정합니다. . 컬렉션 유형과 BitMap을 사용하여 매일 활성 사용자를 저장하는 경우: 1. 사용자 ID가 int 유형, 4바이트, 32비트인 경우 컬렉션 유형이 차지하는 공간은 50 000 000 * 4/1024/입니다. 1024 = 200M; 2. 비트 단위로 저장하면 5천만 개의 숫자는 5천만 비트이고, 차지하는 공간은 50 000 000/8/1024/1024 = 6M입니다. 그렇다면 BitMap을 사용하여 숫자를 표현하는 방법은 무엇일까요? 위에서 언급했듯이 비트 비트는 요소에 해당하는 값을 표시하는 데 사용되며, 키는 비트 단위의
배열
으로 상상할 수 있습니다. 1(0은 숫자가 존재하지 않음을 의미하고, 1은 존재함을 의미), 배열의 첨자를 BitMap에서는 오프셋이라고 합니다. 예를 들어, 4개의 숫자{1,3,5,7}를 다음과 같이 표현해야 합니다:
 아직 숫자 65가 있다면 어떨까요? 이러한 데이터를 저장하려면
아직 숫자 65가 있다면 어떨까요? 이러한 데이터를 저장하려면 int[N/32+1] int 배열만 열면 됩니다(여기서 N은 이 데이터 그룹의 최대값을 나타냄). 즉,
int[ 0 ]: 0~31을 나타낼 수 있음int[1]: 32~63을 나타낼 수 있음
int[2]: 64~95를 나타낼 수 있음
M/32는 아래 첨자를 가져오고 M%32는 다음과 같이 아래 첨자에서 해당 정수가 어디에 있는지 알 수 있습니다. 65/32 = 2, 65%32=1, 즉 65는 int[2]의 첫 번째 위치입니다. Bloom 필터🎜🎜본질적으로 Bloom 필터는 효율적인 삽입 및 쿼리를 특징으로 하는 상대적으로 영리한 확률적 데이터 구조인 데이터 구조로, "어떤 것이 존재해서는 안 되거나 존재할 수 있습니다"라고 알려주는 데 사용할 수 있습니다. 🎜🎜List, Set, Map 등과 같은 기존 데이터 구조에 비해 더 효율적이고 공간을 덜 차지하지만, 반환되는 결과가 정확하지 않고 확률적이라는 단점이 있습니다. 🎜🎜실제로 블룸 필터는 🎜웹페이지 블랙리스트 시스템🎜, 🎜스팸 필터링 시스템🎜, 🎜크롤러 웹사이트 가중치 판단 시스템🎜 등에 널리 사용됩니다. Google의 유명한 분산 데이터베이스인 Bigtable에서는 검색에 Bloom 필터를 사용합니다. IO 디스크는 존재하지 않는 행이나 열을 검색하며 Google Chrome은 Bloom 필터를 사용하여 안전 검색 서비스를 가속화합니다. 🎜🎜 Bloom 필터는 Hbase, Accumulo, Leveldb 등 쿼리 프로세스 속도를 높이기 위해 많은 Key-Value 시스템에서도 사용됩니다. 일반적으로 Value는 디스크에 저장되며 디스크에 액세스하는 데 많은 시간이 걸립니다. Bloom 필터를 사용하면 프로세서는 Key에 해당하는 Value가 존재하는지 빠르게 확인할 수 있으므로 불필요한 디스크 IO 작업을 많이 피할 수 있습니다. 🎜🎜해시 함수를 통해 요소를 비트 배열(Bit Array)의 한 지점에 매핑합니다. 이런 식으로, 그것이 집합에 있는지 알기 위해서는 점이 1인지 확인하면 됩니다. 이것이 블룸필터의 기본 아이디어이다. 🎜🎜응용 시나리오🎜🎜1. 현재 10억 개의 자연수가 무작위 순서로 배열되어 있으며 정렬이 필요합니다. 제한사항은 32비트 시스템에서 구현되며 메모리 제한은 2G입니다. 어떻게 이루어 집니까? 🎜🎜2. URL 주소가 블랙리스트에 있는지 빠르게 찾는 방법은 무엇입니까? (각 URL은 평균 64바이트)🎜🎜3. 사용자 활동을 파악하기 위해 사용자 로그인 행동을 분석해야 합니까? 🎜🎜4. 웹 크롤러-URL이 크롤링되었는지 확인하는 방법은 무엇입니까? 🎜🎜5. 사용자 속성(블랙리스트, 화이트리스트 등)을 빠르게 찾으시겠습니까? 🎜🎜6. 데이터가 디스크에 저장되는데, 다수의 잘못된 IO를 방지하는 방법은 무엇입니까? 🎜🎜7. 수십억 개의 데이터에 요소가 존재하는지 확인하세요. 🎜🎜8. 캐시 침투. 🎜전통적인 데이터 구조의 단점
일반적으로 검색을 위해 웹페이지 URL을 데이터베이스에 저장하거나, 검색을 위한 해시 테이블을 생성해도 괜찮습니다.
데이터의 양이 적을 때는 이렇게 생각하는 것이 맞습니다. 그 값은 실제로 HashMap의 키에 매핑될 수 있으며, 그러면 O(1) 시간 복잡도 내에서 결과가 반환될 수 있어 매우 효율적입니다. 그러나 HashMap의 구현에는 저장 용량의 비율이 높다는 단점도 있습니다. 로드 요소의 존재를 고려하면 일반적으로 공간을 완전히 사용할 수 없습니다. 16자를 초과하고 반복성이 거의 없음), 값=정수, 얼마나 많은 공간을 차지합니까? 1.2G.
실제로 비트맵을 사용하면 1천만 개의 int 유형에는 약 40M(10 000 000 * 4/1024/1024 =40M)의 공간만 필요하므로 3%를 차지합니다. 1000만 개의 Integer에는 약 161M의 공간이 필요하며 13.3%를 차지합니다. .
값이 수억과 같이 많아지면 HashMap이 차지하는 메모리 크기를 상상할 수 있음을 알 수 있습니다.
그러나 전체 웹페이지 블랙리스트 시스템에 100억 개의 웹페이지 URL이 포함되어 있으면 데이터베이스에서 검색하는 데 시간이 많이 걸리고, 각 URL 공간이 64B라면 640GB의 메모리가 필요하므로 일반 서버에서는 이 요구 사항을 충족하기 어렵습니다. .
구현 원리
세트 A가 있고 A에 n개의 요소가 있다고 가정합니다. k 해싱 함수를 사용하여 A의 각 요소 는 길이가 비트인 배열 B의 다른 위치에 매핑되고 이 위치의 이진수는 모두 1로 설정됩니다. 검사할 요소가 이러한 k 해시 함수에 의해 매핑되고 k 위치의 이진수 가 모두 1인 것으로 확인되면 이 요소는 집합 A에 속할 가능성이 높습니다. 반대로 는 집합 A에 속해서는 안 됩니다. .
예를 들어, 3개의 URL {URL1,URL2,URL3}이 있고 다음과 같이 해시 함수를 통해 길이 16의 배열에 매핑합니다. {URL1,URL2,URL3},通过一个hash 函数把它们映射到一个长度为 16 的数组上,如下:
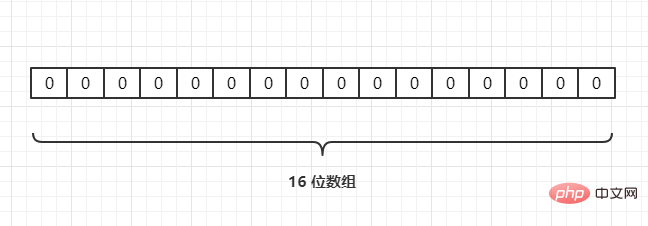
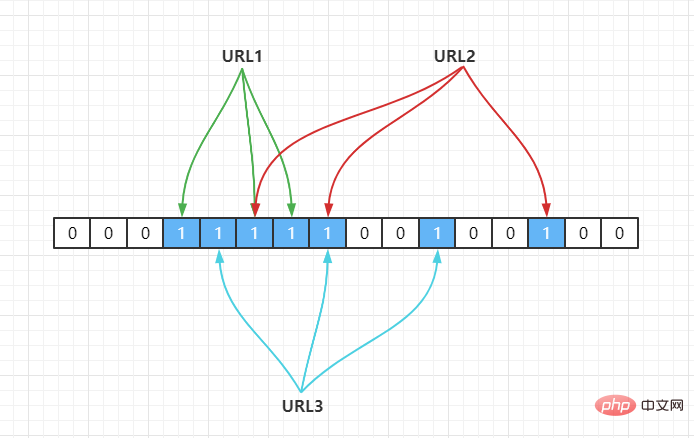
若当前哈希函数为 Hash2(),通过哈希运算映射到数组中,假设Hash2(URL1) = 3,Hash2(URL2) = 6,Hash2(URL3) = 6,如下:
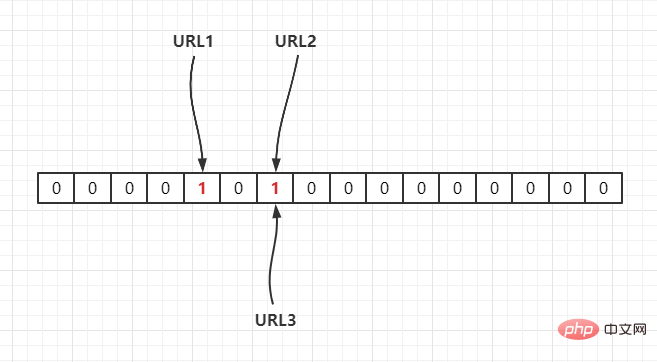
因此,如果我们需要判断URL1是否在这个集合中,则通过Hash(1)计算出其下标,并得到其值若为 1 则说明存在。
由于 Hash 存在哈希冲突,如上面URL2,URL3都定位到一个位置上,假设 Hash 函数是良好的,如果我们的数组长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素,显然空间利用率就变低了,也就是没法做到空间有效(space-efficient)。
解决方法也简单,就是使用多个 Hash 算法,如果它们有一个说元素不在集合中,那肯定就不在,如下:
Hash2(URL1) = 3,Hash3(URL1) = 5,Hash4(URL1) = 6 Hash2(URL2) = 5,Hash3(URL2) = 8,Hash4(URL2) = 14 Hash2(URL3) = 4,Hash3(URL3) = 7,Hash4(URL3) = 10
误判现象
上面的做法同样存在问题,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。比如此时来一个不存在的 URL1000,经过哈希计算后,发现 bit 位为下:
Hash2(URL1000) = 7,Hash3(URL1000) = 8,Hash4(URL1000) = 14
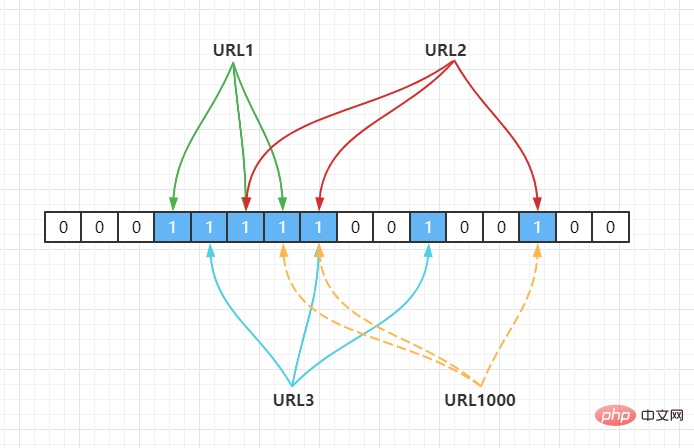
但是上面这些 bit 位已经被URL1,URL2,URL3置为 1 了,此时程序就会判断 URL1000

현재 해시 함수가 Hash2()인 경우 code>, <code>Hash2(URL1) = 3, Hash2(URL2) = 6, Hash2(URL3) = 6, 다음과 같습니다:
따라서 URL1이 이 세트에 있는지 확인해야 하는 경우 Hash(1)를 통해 해당 첨자를 계산하고 값이 1이면 해당 값을 가져옵니다. 존재합니다.
URL2, URL3은 모두 동일한 위치에 있습니다. Hash 함수가 좋다고 가정하면 배열 길이가 m 포인트이면 예를 들어 충돌률이 1%
로 감소하면 이 해시 테이블은m/100 요소만 수용할 수 있습니다. 당연히 공간 활용률이 낮아질 수 없습니다. 공간 효율적
(공간 효율적)이 되어야 합니다. 해결책도 간단합니다. 즉, 그 중 하나가 요소가 세트에 없다고 말하면 다음과 같이 확실히 거기에 없는 것입니다.public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}
 오판 현상위의 접근 방식에도 문제가 있습니다. 증가할수록 점점 더 많은 비트가 1로 설정되므로 특정 값이 저장되지 않았더라도 해시 함수에 의해 반환된 세 비트가 다른 값에 의해 모두 1로 설정되면 프로그램은 여전히 이 값이 존재한다고 판단됩니다. 예를 들어 이때 존재하지 않는
오판 현상위의 접근 방식에도 문제가 있습니다. 증가할수록 점점 더 많은 비트가 1로 설정되므로 특정 값이 저장되지 않았더라도 해시 함수에 의해 반환된 세 비트가 다른 값에 의해 모두 1로 설정되면 프로그램은 여전히 이 값이 존재한다고 판단됩니다. 예를 들어 이때 존재하지 않는 URL1000이 있을 경우 해시 계산 후 해당 비트가 rrreee
 하지만 위의 비트는
하지만 위의 비트는 URL1,URL2,URL3에 의해 1로 설정되었습니다. , 이때 프로그램은 URL1000 값이 존재하는지 확인합니다. 이것은 블룸 필터의 오판 현상입니다. 따라서 🎜블룸 필터가 존재한다고 판단한 것은 존재하지 않을 수도 있지만, 존재하지 않는다고 판단한 것은 존재하지 않아야 합니다. 🎜🎜🎜 블룸 필터는 집합을 정확하게 표현하고 요소가 이 집합에 있는지 정확하게 판단할 수 있습니다. 정확도는 사용자의 특정 설계에 따라 결정됩니다. 100% 정확도를 달성하는 것은 불가능합니다. 하지만 Bloom 필터의 장점은 아주 작은 공간을 사용하여 높은 정확도를 달성할 수 있다는 것입니다. 🎜🎜Redis의 비트맵 데이터 구조의 관련 명령어를 기반으로 🎜🎜Redis의 비트맵🎜🎜을 구현하고 실행합니다. 🎜🎜RedisBloom🎜🎜 Bloom 필터는 Redis에서 비트맵 연산을 사용하여 구현할 수 있습니다. Redis에서 공식적으로 제공하는 Bloom 필터가 플러그인 기능을 제공하기 전까지는 Redis가 정식으로 로드되지 않았습니다. Redis 서버에 공식 웹사이트에서는 Redis Bloom 필터용 모듈로 RedisBloom을 권장합니다. 🎜🎜Guava의 BloomFilter🎜🎜Guava 프로젝트가 버전 11.0을 출시했을 때 새로 추가된 기능 중 하나가 BloomFilter 클래스였습니다. 🎜🎜Redisson🎜🎜Redisson은 하단의 비트맵을 기반으로 블룸 필터를 구현합니다. 🎜public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}解决缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。
因此我们可以用布隆过滤器来解决,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如:一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
注:布隆过滤器可能会误判,放过部分请求,当不影响整体,所以目前该方案是处理此类问题最佳方案
위 내용은 Java에서 Bloom 필터를 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!